Set up persistent storage for containers in the cloud
All the major cloud vendors offer containers as a service. There are various ways IT admins can enable persistent storage for these flexible environments.
Persistent storage for containers is a common need among enterprise users, including those who run workloads in the cloud.
Container instances are ephemeral; once an individual container is destroyed, it leaves nothing behind. As a result, workloads that require persistence -- whether by saving state and work products or accessing a shared database -- must interface with external systems.
To meet this need, management platforms like Docker and Kubernetes, as well as cloud container management services from AWS, Azure and Google, provide mechanisms to connect to storage volumes, network file systems and databases.
Because there are many ways to implement persistent storage for containers in the cloud, admins must choose the option that is best for their unique storage needs.
Background on CaaS and Kubernetes
Containers as a service (CaaS) offerings have become increasingly popular alternatives to self-managed Kubernetes installations because of their convenience, portability, security, scalability, performance and flexibility. The versatility of cloud-hosted containers, which can use a panoply of cloud providers' native services, is a significant incentive for organizations that prefer online services to private container infrastructure.
Kubernetes has become the preferred cluster management platform. It is available through offerings like Amazon Elastic Kubernetes Service (EKS), Azure Kubernetes Service (AKS) and Google Kubernetes Engine (GKE). Nonetheless, cloud users still have several options to provision cluster nodes using either dedicated compute instances like Amazon Elastic Compute Cloud or on-demand container instances through services like AWS Fargate, Azure Container Instances or GKE node auto-provisioning.
Admins often use persistent volumes with a Kubernetes feature called StatefulSets, an API that manages the deployment and scaling of a set of pods.
Regardless of how admins deploy cluster nodes, the Kubernetes control plane offers several ways to connect to persistent volumes and file shares, including those created by cloud storage services.
Kubernetes storage options
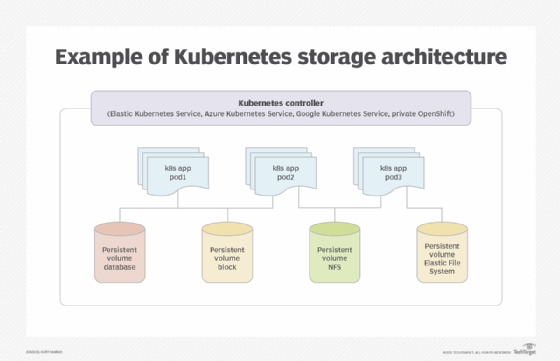
Storage use in Kubernetes can be confusing because of the platform's flexibility and support for so many storage platforms. In reality, Kubernetes storage is conceptually simple and boils down to connecting a pod -- one or more containers sharing a namespace, volumes and other settings -- to an external volume. Volumes can be:
a logical disk and mount point;
block storage services like Amazon Elastic Block Store (EBS) or Azure Disk; and
a network file share, from a storage array running NFS, Ceph (CephFS), etc., or cloud file services like Amazon Elastic File System (EFS) or Google Cloud Filestore.
According to Kubernetes documentation, a volume is just a directory, possibly with some data in it, that is accessible to the containers in a pod. The particular volume type an admin uses will determine how that directory comes to be, the medium that supports it, and its contents.
The flexibility to support multiple storage types stems from the Container Storage Interface (CSI), a standard for exposing block and file storage to container orchestrators including Cloud Foundry, Kubernetes, Mesos and Nomad. Pods use the configuration in a .spec.volumes file to mount volumes, but admins can't nest volumes. One volume can't mount or have symbolic links to other volumes. Each supported volume type has a distinct keyword, as specified in Kubernetes documentation; for example, awsElasticBlockStore for EBS, azureFile for Azure Files or iscsi for a SAN iSCSI volume.
Admins often use persistent volumes with a Kubernetes feature called StatefulSets, an API that manages the deployment and scaling of a set of pods. It provides unique, persistent identities, permanent host names and ordered, automated rolling code updates. According to Kubernetes documentation, individual pods in a StatefulSet can fail, but the persistent pod identifiers help match existing volumes to the new pods that replace those that fail.
Applications that run in a container can also connect to external databases through IP using Open Database Connectivity drivers available for most languages. Some cloud services such as Azure provide instructions to maximize network performance and minimize database overhead when admins connect AKS with Azure Database for PostgreSQL.
Other cloud database services use a sidecar proxy to support connection methods. For example, the Google Cloud SQL Proxy is a secure and reliable method to link GKE applications to Cloud SQL instances. Google offers best practices to map external services to Kubernetes, such as the creation of service endpoints for external databases and the use of uniform resource identifiers with port mapping for hosted database services.
Because CaaS products use existing storage interfaces, and there are CSI drivers for cloud block and file services, pod deployments can choose between private, self-managed storage volumes and shares or cloud resources.
Some of the most popular CSI driver options include:
Amazon EKS EBS CSI driver
Amazon EKS EFS CSI driver
Azure Disk CSI driver
Azure Files AKS CSI driver
GCP GKE Persistent Disk CSI driver
GCP GKE Filestore connections
GCP Cloud SQL Proxy for GKE
Likewise, Kubernetes pods can connect to private NAS using NFS CSI drivers. Several enterprise storage providers offer CSI and storage software designed for Kubernetes, such as Dell EMC CSI Plugins, NetApp Trident and Pure Storage Portworx.