
kentoh - Fotolia
Optimize Kubernetes cluster management with these 5 tips
Effective Kubernetes cluster management requires operations teams to balance pod and node deployments with performance and availability needs.

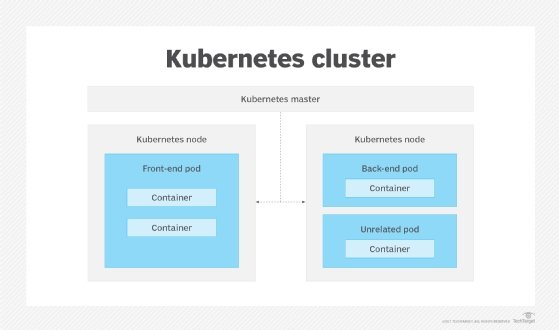
To deploy and manage Kubernetes successfully, IT admins must first understand its core architectural building blocks.
For example, Kubernetes groups containers into units called pods, which run on physical or virtual hosts called nodes. Collections of nodes that work together to support a pod deployment, and its associated applications, are called clusters.
IT operations teams must manage these various Kubernetes components deliberately to achieve desired levels of workload performance and reliability. But, like so many things in IT, effective Kubernetes cluster management requires a firm grasp of relevant technical concepts, hands-on practice -- and perhaps a bit of patience.
Use these five SearchITOperations tips to streamline the design and oversight of a Kubernetes container cluster.
Map pods to nodes based on resource use
The decision of how many pods to run on a Kubernetes node shouldn't be arbitrary. IT consultant Tom Nolle discusses why admins must carefully consider resource usage trends and an application's overall architecture to make sound Kubernetes deployment decisions.
Kubernetes uses scheduling rules to assign containers in a pod to certain nodes within a cluster. IT administrators should set these rules based on container resource requirements and make them as detailed as possible to ensure optimal scheduling and, therefore, optimal application performance.
Use Kubernetes cluster monitoring tools to track the resource usage trends relevant to container-to-pod and pod-to-node mapping.
Optimize the number of nodes in a cluster
Just as they should when mapping pods to nodes, IT admins must consider resource usage to determine how many nodes to run in a Kubernetes cluster. Tech writer and analyst Chris Tozzi explores three general factors that dictate the number of nodes to include: workload performance goals, availability requirements and node type.
Nodes contribute varying amounts of resources, such as compute and memory, to a Kubernetes cluster. Carefully assess those resource contributions as you consider the number of nodes per cluster; for example, a large number of lightweight nodes might contribute fewer overall resources than a smaller number of more powerful nodes.
In addition, ensure a sufficient number of nodes is in place to maintain availability in case some nodes fail. And understand the implications that node types -- VMs versus physical machines -- have on cluster availability.
Manage scheduling with taints and tolerations
IT admins can lean on several mechanisms to streamline Kubernetes cluster management. One is affinities, characteristics of a pod that draw it to a certain set of nodes. Another is the opposite of affinities, called taints, which enable a node to repel certain pods.
Taints work alongside tolerations, which are applied at the pod level to let pods schedule onto nodes that have corresponding taints. Nolle explains how, together, taints and tolerations prevent pods from being assigned to nodes that aren't suited to host them -- perhaps because those nodes are reserved for specific users or for workloads that require specialized resources, such as GPUs.
Before working with taints and tolerations in Kubernetes, be familiar with the use of keys to restrict scheduling. And to prevent potential errors, carefully manage who in an organization can define tolerations.
Ensure high availability at the master-node level
As mentioned earlier, the nodes in a Kubernetes cluster affect workload availability. In a cluster with multiple nodes, one or more nodes can fail, and the remaining nodes will pick up the slack to ensure minimal disruption to users.
But while this is true of worker nodes -- or the nodes that actually run containers -- the failure of a single master node -- the node that controls the workers -- can be far more disruptive, and eliminate, for example, the ability to schedule new deployments.
As a result, it's critical to build high availability into a Kubernetes cluster, and ensure redundancy for master node components. IT analyst Kurt Marko dives into two Kubernetes high availability design approaches, and discusses how cloud services can also boost resiliency.
Carefully plan cluster networking
Networking is core to Kubernetes cluster management, as it enables communication between the various cluster components.
Nolle examines how the container orchestration platform supports two network models: unified and overlay. The former entails standard ethernet and IP network protocols but isn't always suitable for hybrid or multi-cloud models. The overlay approach, on the other hand, is optimized for these cloud environments, but requires a new cloud network for container deployment. The best Kubernetes networking strategy ultimately depends on an organization's current and future cloud requirements.
In addition to understanding the unified and overlay models, Kubernetes admins must grasp cluster networking concepts at three levels: networking within pods, networking between pods and networking that connects users with containerized resources.





