Kubernetes scheduler

What is the Kubernetes scheduler?
The Kubernetes scheduler is a component of the open source Kubernetes container orchestration platform that controls performance, capacity and availability through policies and topology awareness.
The Kubernetes scheduler resembles the containerization equivalent of virtual machine schedulers such as VMware Distributed Resource Scheduler.
How does the Kubernetes scheduler work?
Kubernetes deploys containers that are organized into pods, which reside on logical groupings of resources called nodes. Workload-specific requirements are set through the Kubernetes application program interface (API).
The scheduler is a monolithic component of Kubernetes, decoupled from the API server that manages clusters. It is not an admission controller, which is plugin code that intercepts requests to the Kubernetes API.
The Kubernetes scheduler attempts to match each pod Kubernetes creates to a suitable set of IT resources on a node. It can also distribute copies of pods across different nodes to ensure high availability, if desired.
If the Kubernetes scheduler fails to find hardware that suits a pod's requirements and specifications -- such as affinity and anti-affinity rules and quality-of-service settings -- that pod is left unscheduled, and the scheduler retries it until a machine becomes available.
Configuring the Kubernetes scheduler
To configure the Kubernetes scheduler in versions 1.24 and later, users can write a configuration file containing a scheduling profile, which specifies how Kubernetes should behave at different stages of the scheduling process. This configuration file can then be passed to the scheduler as a command-line argument.
In Kubernetes versions 1.23 and prior, the scheduler is configurable with two policies: PriorityFunction and FitPredicate. Together, these two policies aim to load balance container workloads across multiple machines so that one machine is not given intense activity while others sit idle.
The Kubernetes scheduler can also pick a node at random -- a method that assigns containers to resources with minimal computational overhead.
Kubernetes scheduler vs. other scheduling options
Kubernetes users can implement a chosen scheduler instead of the default. Custom schedulers are not generally in high demand, but they come in handy for users with exacting needs around latency or uptime for specific workloads.
For example, a user can write a custom scheduler for a workload in a pod with particularly demanding requirements. Likewise, a user could implement Apache Spark or Mesos schedulers to take over scheduling for applications based on these frameworks.
Kubernetes also lets users perform concurrent scheduling, in which multiple schedulers can work simultaneously, including the default scheduler. Thus, some pods in a Kubernetes deployment might use the default scheduler while others in the same deployment do not.
Kubernetes scheduler history and future outlook
Kubernetes is a fast-evolving open source project originally created by engineers at Google and first announced in 2014.
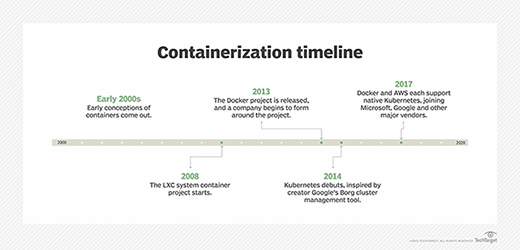
Many scheduling features appear in alpha and beta in new Kubernetes releases before becoming part of the stable release. For example, Kubernetes 1.7 introduced an alpha feature to let users request that pods execute on nodes with locally attached storage via StorageClass settings.
In future releases, look for the Kubernetes project to focus on refining advanced scheduling features such as affinity and anti-affinity at the node and pod level, taints and tolerations, and custom parameters. The Kubernetes open source community is also focused on prioritization technology that enables users to tell Kubernetes that one pod is more important than the others and should not wait to be scheduled behind other workloads.





