Kubernetes pod

What is a Kubernetes pod?
Kubernetes pods are the smallest deployable computing units in Kubernetes, an open source system for container scheduling, orchestration and management. The name reflects how Kubernetes pods function like pods in nature, such as pea pods.
How does a Kubernetes pod work?
In Kubernetes, the term "pod" describes one or more containers that operate together. Although a pod can encapsulate many containers, each pod is typically home to only one container or a small number of tightly integrated containers.
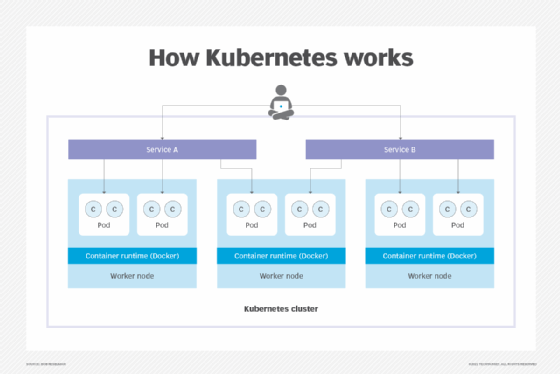
Pods reside on nodes. More than one pod can share the same node. The containers within each pod share the host node's networking and storage resources, as well as specifications that determine how the containers run.
A pod's contents are scheduled and located together, modeling an application-specific logical host. Kubernetes users should host tightly integrated application containers in the same pod because, without containers, these applications or services would run on the same virtual or physical machine.
A pod's shared context is set by facets of isolation, such as Linux namespaces or cgroups. For an individual pod, single applications can be further isolated.
Kubernetes operators can expose information about pods, nodes and containers using environment variables. Kubernetes environment variables are statically defined or written by the user.
Pod environment variables tell the application in the pod's containers where to find resources or how to configure a component. This information is injected into the container at runtime. Although nodes also contain environment variables, they are not exposed to the containers.
Kubernetes pod management
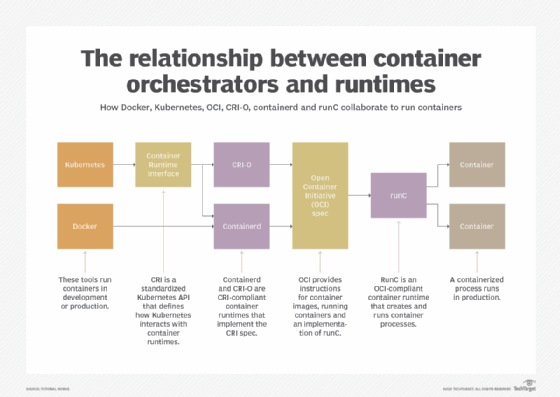
Kubernetes supports any container runtime compatible with the Container Runtime Interface (CRI), such as containerd and CRI-O.
Although users can create pods, the Kubernetes controller usually creates pods and pod replicas for high availability or horizontal scaling. For example, when the user requests three new instances of a pod, Kubernetes creates three pods as API-level resources. The scheduler finds the appropriate node for each pod based on the Kubernetes user's policies and places the pod there.
Containers within a pod share a common IP address and port space. They can discover each other through localhost. Applications assigned to the same pod access shared volumes, attached to that pod.
Pods also enable containers to communicate using other standard means of communication, such as POSIX shared memory or System V semaphores. Containers in different pods have different IP addresses and are unable to use the inter-process communication (IPC) protocol.
However, Kubernetes pods can easily communicate with each other via services. For example, if the front end of an application resides in a pod on one node, the back end of that application can reside on the same node, on a different node or in multiple instances spread across various nodes. The front-end pod simply connects to a service that represents the back-end pod or pods.
How are Kubernetes pods used?
In Kubernetes, pods are generally ephemeral, as are application containers.
Users design a pod and assign it unique identification and resource requirements. The system can then schedule the pod to an appropriate node, specifying settings for quality of service if desired. The pod uses that node until the session is terminated or the pod is deleted.
When a node shuts down, the pods attached to it are scheduled for deletion following a timeout period. An individual pod, which is marked with a unique identifier, cannot be rescheduled to a new node but can be copied and replaced with an identical pod. The user can recycle the same name and identifier for the new pod.




