Ensure Kubernetes high availability with master node planning
Kubernetes ensures high availability in its worker nodes, but for a mission-critical workload, IT teams should take these extra steps for redundancy in the master node components.

Kubernetes automatically places and balances containerized workloads, as well as scales clusters to accommodate increasing demand. But to have a successful deployment in production at scale, IT operations teams need to take steps to ensure Kubernetes high availability.
An overview of Kubernetes redundancy
Those with a cursory understanding of Kubernetes might think that, since it manages container clusters, it's inherently redundant -- but that's not entirely the case. The nodes that run containers, called the worker nodes, are interchangeable. Therefore, in a multi-node cluster, the failure of one or more nodes merely results in the redistribution of workloads to one or more of the remaining worker nodes without disruption to application users.
Unlike the worker nodes, the brains of a Kubernetes cluster -- the master nodes and etcd datastore -- are not inherently redundant. Kubernetes is an example of a common design pattern: a distributed system with a non-redundant management control plane. While the failure of a single master won't disrupt running containers, it will prevent the system from scheduling new workloads or restarting already running ones, should they or their entire node stop.
Highly available Kubernetes clusters might be needed for critical enterprise workloads. An organization can build a single-site reliable cluster without additions to Kubernetes itself; Kubernetes high availability is primarily a matter of proper design, configuration and networking.
Non-redundant Kubernetes components
Before building for high availability, review the primary components of a Kubernetes cluster, including those related to master and worker nodes.
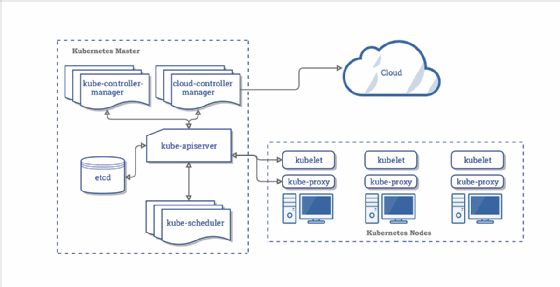
Kubernetes master components include:
- Kube-apiserver. The front end of the control plane that exposes Kubernetes APIs to cluster nodes and applications.
- Etcd. The Kubernetes data plane, in the form of a key-value store that manages cluster-specific but not application data.
- Kube-scheduler. Monitors resource usage on a cluster and assigns workloads, in the form of Kubernetes pods, to one or more worker nodes based on specified policies about hardware usage, node-pod affinity, security and workload priority.
- Kube-controller-manager. Runs the controller processes responsible for node monitoring, replication, container deployment and security policy enforcement.
- Cloud-controller-manager. A feature that primarily service providers use to run cloud-specific control processes.
Kubernetes worker node components include:
- Kubelet. An agent that runs on each worker node.
- Kube-proxy. Manages network communication between cluster nodes.
- Container runtime. The engine that runs containers and maintains workload isolation within the OS.
Build a Kubernetes high availability strategy
The master node components are critical to the operation of Kubernetes clusters, which means that to build a highly available environment entails adding redundancy to the master elements. The trick is in the details, for both single data center deployments and geographically distributed clusters.
Within a single data center, the control plane components that run on master nodes and the data plane of etcd require protection from failure. In a highly available Kubernetes cluster, both these elements must run on multiple systems. The Kubernetes support team also should regularly back them up to an independent archive system.
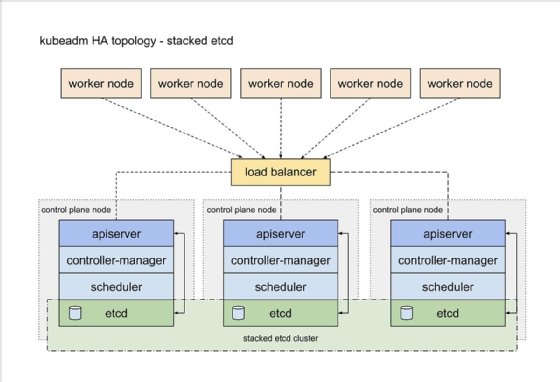
Kubernetes recommends two design approaches to HA topologies. The first approach for highly available Kubernetes clusters is made of stacked control plane nodes, in which the control plane and etcd components run on the same nodes. Stacked clusters are the default option in kubeadm. The kubeadm tool is a way to set up a Kubernetes cluster with a reasonable set of defaults. Kubeadm is an alternative to Kubernetes Operations, called kops, which is kubectl for clusters. In the simplest scenario, kubeadm configures a cluster with all the control plane components on a single node, but there are ways to create more complicated deployments.
With kubeadm, Kubernetes automatically creates a local etcd key-value store on each control plane node, which enables simple set up and management. However, this configuration is risky for Kubernetes deployments that must withstand outages, since every critical component to manage a cluster runs on the same node. A minimum of three-node redundancy is advised for enterprises that use stacked clusters.
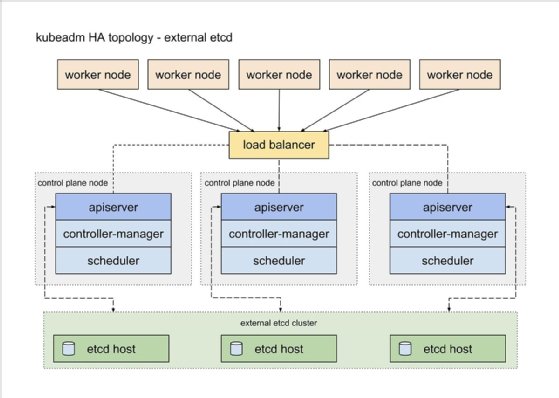
The second approach to Kubernetes high availability involves external etcd nodes, in which the redundant control plane and etcd components run on separate nodes. This technique has two failure domains -- the control plane and etcd database -- which minimizes the effects of a master node failure. However, it uses twice as many hosts as the stacked approach, consuming resources. Ideally, the design also includes a second load balancer between the control plane and etcd nodes, although one-to-one coupling works between the two types of nodes.
Kubernetes cluster setup for high availability
To set up a cluster with either above approach to high availability, use the kubeadm command-line interface to complete these steps, outlined here and detailed in Kubernetes' kubeadm documentation:
- Create and configure a load balancer to manage traffic to the kube-apiserver. The load balancer can be an external device, virtual cloud service or proxy software such as HAProxy or NGINX and should be set to monitor the kube-apiserver's TCP port (default 6443).
- Set up and start the first control plane node using kubeadm.
- Set up and start replicas of the initial node. Use kubeadm join to join them into a cluster.
- For external etcd nodes, set up an etcd cluster and configure the first control plane node to use the cluster via the kubeadm-config file. Use kubeadm join to join the replica control plane nodes to the first one.
Due to how multiple Kubernetes masters reach consensus when there's a change in the cluster's state, the configuration must use more than two nodes, since the failure of either one in a two-node cluster means the cluster cannot reach consensus. Thus, a two-node cluster effectively doubles the likelihood of a cluster failure over a single-node implementation.
Availability in the cloud
IT admins can use the previous steps to run self-managed Kubernetes clusters on cloud infrastructure, such as AWS Elastic Compute Cloud instances. The ability to deploy compute instances in multiple cloud data centers adds another measure of resilience as it protects against the failure of an entire data center site. At a minimum, cloud users should consider setting up control plane nodes that spread across multiple AWS availability zones (AZs) or the equivalent on Azure and Google Cloud Platform and other public cloud providers. Control plane, i.e. master, clusters can spread across multiple cloud regions, although this setup introduces complexity into the load balancer and networking configuration.
With managed Kubernetes services such as Amazon Elastic Kubernetes Service and Google Kubernetes Engine, this type of manual cluster configuration is unnecessary -- the services provide redundant infrastructure by default. For example, EKS splits the control plane across multiple AWS AZs and automatically detects and replaces failed control plane instances. Microsoft's Azure Kubernetes Services does not provide control plane redundancy by default, but it is a user-configured option.




