How an object storage architecture can help reduce storage complexity
An object storage architecture tackles traditional storage limitations by offering a file structure that is ideal for storing and protecting large amounts of unstructured data.

With data growth increasing at an accelerating rate, organizations need more data storage capacity, more quickly and on a more regular basis than ever before.
But this trend creates two primary challenges: It can be hard to grow storage capacity in a non-disruptive way, and traditional storage systems often struggle to scale beyond a certain point. An object storage architecture can address these challenges.
Adding storage often requires taking down primary storage during the expansion, causing disruption. And when capacity is added, it often puts a strain on other underlying resources, such as CPU and networking, on which the storage relies to maintain acceptable performance.
There are other limitations inherent in traditional storage that can impact availability. Perhaps most important is the need to back up data. If your storage goes down, you need a way to recover it.
As data sets become larger, this need to provide after-the-fact data protection can become incredibly difficult and expensive to address. As data sets grow, more data is ingested than can be reasonably accommodated during backup windows. A more real-time approach is required to handling data protection. This is where object storage technology comes in.
Object storage 101
An object storage architecture addresses the problem of growing unstructured data and helps companies reduce the complexity of their storage systems.
You may be used to storage consisting of files or blocks that are accessed through storage protocols such as NFS, Fibre Channel, iSCSI or SMB. In the world of object storage, however, the structure of the underlying data means that you no longer need to use these protocols. While in some cases you still can, here you no longer need to create complex directory hierarchies to categorize your objects. Instead, object storage allows you to access objects directly.
Objects can be as simple as a single file, image or video, or can be comprised of multiple elements, but they are still accessed as a single object. Every object also has associated metadata and a unique object identifier that allows it to be retrieved at a later date. This customizable metadata describes various attributes of each associated object.
Metadata elements always include common object characteristics, but can be extended to include application-specific characteristics, as well. Let's use an example of a photo library. In a file-based world, you would have a file name, a creation date, a modification date, a file size and a file owner, and maybe some operating system-specific identifiers.
Now, consider a company such as Shutterstock. Its object storage system can be extended to include additional metadata elements, such as image type (illustration or photo), image width in pixels, image height in pixels, primary colors present in the picture and much more. By having all of this information attached to the object, the company can quickly and easily retrieve photos for its users without using a huge SQL database to track it all.
As another example, in the medical field, metadata can include the patient's name, procedure data and physician name, and be attached to an object, such as an X-ray image. Beyond simply describing an object, metadata can also be used for security and availability purposes by describing who is allowed to access an object, how much redundancy an object should have and more.
An object vs. file vs. block bake off
At first glance, an object storage architecture might look similar to block storage, which, at its most basic, also has no hierarchy. However, the retrieval of blocks of data requires higher level applications in file systems to impose a hierarchy on block storage. Another difference between blocks and objects is block-based storage carries no metadata.
For file-based storage, the file system provides a hierarchy and even limited metadata, so it is far more suitable for content organization than raw block storage. However, under the hood, the reality is that individual files are broken into tiny pieces, and then strewn about storage in random locations. The file system knows where to go to get all of the pieces, and when a user requests a file, the file system jumps into action to retrieve everything.
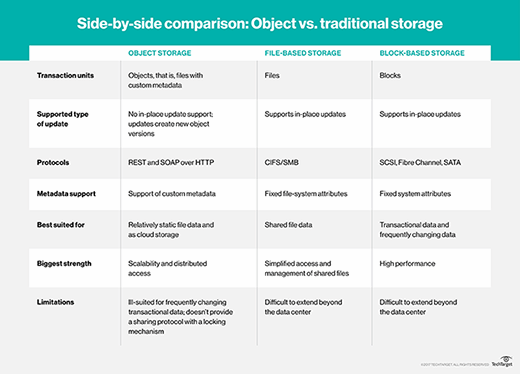
An object storage system stores files as single entities, with retrieval taking place after an application makes a call to storage with an object ID. Every object has a unique object ID, so there is no need to maintain higher level structures to keep things organized. The ability to search against all of the metadata makes it even easier to retrieve items.
Availability and data protection in an object world
Keeping storage available and data protected is one of IT's most important responsibilities.
To that end, storage pros deploy RAID arrays and backup systems. RAID helps to protect against hardware failure, while backup and recovery systems jump in when RAID falls short, or when there is a disaster that RAID cannot protect against.
An object storage architecture commonly includes one or two different data protection methods to protect against hardware failure and disasters. While not necessarily true in every organization, object storage can potentially eliminate the need for third-party backup and recovery software. This feat can be accomplished in a few different ways.
Erasure coding. This is a bit more complex than a traditional RAID implementation, but the intent is to hide the complexity and present to the administrator an overall simpler environment.
erasure coding works by adding a number of parity segments to a data block, and then distributing these parity segments to various locations. For example, suppose a storage system uses a 10+6 erasure coding methodology. Parity blocks are spread across 16 drives, but you only need 10 of these disks to remain available to continue retrieving data. That means any six drives can fail. As long as 10 remain in play, the system remains in operation.
If there is a drive failure, upon replacement of the failed drive, the lost data blocks are rebuilt from the 10 drives that remain in production. This results in much faster recovery than is possible with RAID, especially with large drives.
With quick rebuilds, erasure coding is efficient when it comes to capacity overhead. And it could be used for traditional file and block storage, but those implementations are rare because erasure coding is a complex, computationally intense process.
Replication. Sometimes used in addition to erasure coding, replication involves making redundant copies of data in other storage cluster locations, or even in alternative geographic locations. But replication adds capacity overhead.
By using a replication factor of two, you can save data twice and double your capacity footprint. A replication factor of three will triple your capacity footprint, and so on. Often, local availability and protection can be handled via erasure coding alone, with disaster recovery leveraging replication.
Protocols and file access. Object storage systems are natively accessible via HTTP and REST API calls. This makes storage accessible even through corporate firewalls. However, it does not make object storage all that useful for more mainstream use cases, such as enterprise file sharing.
Users have become accustomed to accessing their files via NFS and SMB. Many object storage systems front end their object stores with NFS or SMB services so that users and applications can access files using these industry standard protocols. This is simply a compatibility mechanism. Behind the scenes, the object storage system is running the show.
Who uses object storage technology?
The biggest consumers of object storage are media and entertainment companies, oil and gas companies, and healthcare organizations. These companies have an intense need for data storage that can grow really fast and that can efficiently house billions of data elements, which become objects.
Technology companies, particularly cloud service providers, and other software and service providers are also using object storage.
The pros and cons of an object storage architecture
An object storage architecture provides a number of benefits.
Simplicity. Object storage is almost always the right tool for the job of managing vast quantities of unstructured data. Thanks to powerful metadata capabilities and a flat structure, object storage requires no abstraction layers, such as file systems.
Cost. Because expanding traditional storage and forecasting data growth can be difficult, many companies overbuy storage, so that they do not need to manage it as often, and to prevent getting caught short.
Because it is highly scalable, object storage can help organizations operationalize their storage costs. In other words, they can easily add more storage as needed rather than buying in bulk upfront.
This scalability also means that the idea of a traditional storage refresh goes away. Instead of planning a weekend to move to new storage every other year, you simply add a new node and take an old one out of service.
Organization. Simplicity in management is one thing, but simplicity in data access and retrieval is another. Thanks to the underlying simplicity inherent in an object store, users can easily find content.
But object storage has some limitations, as well, and may not be right for everyone. For example, if you have data that is rapidly changing, such as significant database workloads with high transaction counts, object storage may not be for you.
Further, some object storage vendors do not support or recommend running virtual machines on their products because the underlying data is changing too rapidly, and application performance may suffer.
Finally, although some object storage systems claim that they don't need to be backed up using traditional tools, many corporate risk managers disagree. However, some traditional backup tools do not support protecting object storage. Object storage adopters will need to find alternative ways to align the protection of their object storage systems with their corporate policies.
Buying object storage software
You can buy object storage in a few different ways. In this era of the software-defined data center, many resources can be acquired as software only, if you are willing to add your own hardware.
Still, many companies prefer to buy products ready to deploy, and will choose to acquire software packaged on appliances. In general, these appliances are x86 servers tuned to run with the specific software.
Another option for object storage is to allow your vendor to manage it for you in a hosting facility. And don't forget the cloud: Object storage is pervasive among cloud storage providers. Object storage companies generally support deployment in the public cloud to enable hybrid cloud initiatives that provide the seamless transition of data from on-premises environments.
The market for object storage platforms
Here, we will examine products from the leading object storage vendors. We will focus on offerings from Caringo Inc., DataDirect Networks Inc., Dell EMC, Hitachi Data Systems Corp., IBM, NetApp and Scality Inc. These vendors and products were chosen by TechTarget after extensive research into the top market shareholders and which products fit the presented buying criteria best. Here is a brief overview of what each vendor offers.
Caringo is notable as one of the stand-alone object storage companies in the lineup. It provides the Swarm object storage platform, as well as FileFly, which helps organizations migrate their existing Microsoft Windows and NetApp file shares to Caringo Swarm clusters.
Another stand-alone company, Hitachi, offers its Hitachi Content Platform (HCP), which forms the basis for the company's object storage efforts, and is a full-featured object store. HCP can be expanded with HCP Anywhere to imbue enterprises with on-premises sync-and-share (Dropbox-like) capabilities, as well.
Not all of the companies in the lineup are focused solely on object storage. DataDirect Networks, for example, sells a variety of file- and block-based storage products, as well as the WOS purpose-built object storage product. Like Caringo, DDN is a stand-alone, storage-centric company that has developed its own line of storage products.
Another from-scratch product is Scality's RING object storage software, which can run on commodity x86 hardware, making it an option for organizations that want to bring their own hardware to get to exact specifications and, maybe, to reduce cost.
Dell EMC is a prime example of a company that has undergone major changes recently. Through Dell's acquisition of EMC, the company now offers multiple object storage products, including Isilon and Elastic Cloud Storage.
As mentioned, not all of the vendors have developed their own products. One such company is IBM. In 2015, IBM acquired Cleversafe, and it recently rebranded the product as IBM Cloud Object Storage.
Likewise, via a 2010 acquisition of Bycast, NetApp now sells its StorageGRID Webscale product, which can scale both on-premises and across geographies.
Dig Deeper on Storage architecture and strategy
-
![]()
Block vs. file vs. object storage: Differences explained
By: Brien Posey
-
![]()
Latest version of Vdura Data Platform aimed at enterprise AI
By: Adam Armstrong
-
![]()
Hammerspace reaches everywhere with erasure coding
By: Adam Armstrong
-
![]()
Hammerspace leverages smart metadata handling for AI/ML workloads
By: Antony Adshead



