How to build redundancy in Active Directory replication
Building redundancy in Active Directory replication is one way an administrator can ensure AD replication continues even if critical domain controllers fail.

One of the critical aspects of any administrator's job is his or her ability to recover from an unexpected failure – be it intentional or accidental. Active Directory disaster recovery has many facets to ensure a recovery of the Active Directory. It is far more complex than simply keeping a backup tape handy.
The best way to ensure that you can successfully recover from any kind of failure - hardware or software - is to be proactive. Take steps to ensure that the business will suffer a minimum of downtime - preferably no downtime at all. In this article, we will discuss how to ensure that Active Directory replication will continue in spite of failure of critical domain controllers.
Password changes, security changes, security policy, and a host of critical configuration settings are implemented through group policy, FRS Replication and Active Directory replication and are responsible for making sure all domain controllers have the same policy settings. Therefore, it stands to reason that it is in the best interest of the enterprise to ensure that Active Directory replication is successful and remains uninterrupted. It is very common for companies to create a disaster recovery site - a site that could be used to support the infrastructure, critical applications and data should the corporate "hub" site go down entirely. Many corporate networks are configured in some iteration of a hub and spoke network, as shown in Figure 1. Note that in some configurations, there are multiple hubs that form a core for Active Directory replication. Having multiple core hub sites contains an inherent disaster recovery configuration. That is, if one core site goes down, there are others that will share the load.
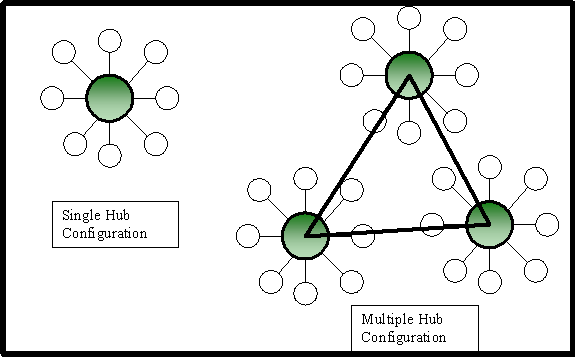
Figure 1: Single vs Multiple hub network topology
For single hub configurations, the disaster recovery challenge is to create an Active Directory site in a well connected location in the network, coupled with at least one domain controller from each domain in each forest in the enterprise. This should include at least one global catalog server (GC), Exchange servers, and other file/print and application servers depending on the infrastructure required to support the user community.
Assuming we have selected such a site and have the necessary server infrastructure, one of the things we have to determine is what happens to Active Directory replication when the primary hub site becomes unavailable. Remember that you don't have to wait for a terrorist attack for this site to become unavailable - a simple network failure or power outage could accomplish the failure.
Consider the case where the network is a simple hub-and-spoke topology with a single hub. A well-designed disaster recovery site would take the load if the primary hub site failed. In considering how to make Active Directory replication redundant in case of a complete failure of all domain controllers at the hub site, the temptation is to create site links both the primary hub site an the disaster recovery site as shown in Figure 2. Here we see that the site links connecting remote sites to the primary hub site have a cost of 100, and those connecting remote sites to the disaster recovery site have a cost of 200. On the surface it seems to make sense. The redundant links would not be used as long as the domain controllers in the primary site were operational, since the least-cost-path would favor the primary site links to the remote site links. However, in testing with the primary site domain controllers disabled, we found that the KCC computed a different topology than the architect had intended, resulting in connections going between remote sites rather than directly to the disaster recovery site. Attempts to correct it were in vain. While it would be interesting to try to figure out exactly why this topology was calculated the way it was by the KCC, a review of simple Active Directory replication rules revealed that the real problem was the design.
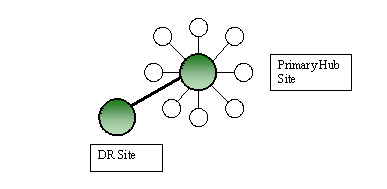
Figure 2: A single hub site configuration with a disaster recovery site.
Active Directory replication has a built-in redundancy feature called the Site Link Bridge. The Site Link Bridge allows the KCC to build transitive links in the event of a failure of a domain controller in any given site, allowing replication to route around failed domain controllers without any human intervention. This is particularly important in the event that a failed domain controller is the only one in the site (or similarly, if all domain controllers in a site fail as is the case with our disaster recovery scenario). Consider the case in Figure 3. There are 3 sites - ATL, CHI, and NYC. Assuming physical network connects all three sites, site links connect ATL and CHI sites, and a site link connects CHI and NYC sites. No site link connects ATL and NYC. As long as the domain controller in CHI is alive, replication is happy. But what if the CHI domain controller fails? It would seem that replication between ATL and NYC would fail - and it certainly would, without the Site Link Bridge. If the Site Link Bridge is enabled, the KCC would determine that, since ATL can replicate to CHI and since CHI can replicate to NYC, then ATL can replicate with NYC. It then creates a link from ATL to NYC, with a cost equal to the combined cost of the CHI-NYC and ATL-CHI links (see Figure 4).
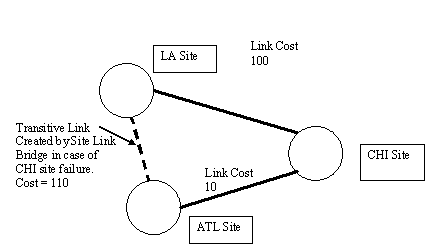
Figure 3: ATL site replicates to LA site via the CHI site domain controllers.
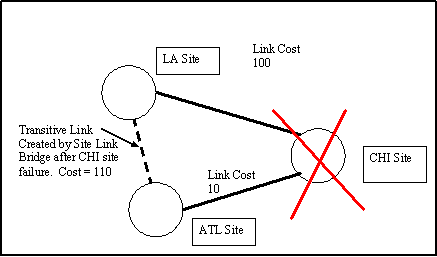
Figure 4: In case of CHI site failure, and Site Link Bridge is enabled, the KCC builds a transitive link between ATL site and LA site to allow replication.
Remember, the KCC can't see the physical network and relies on the administrator to configure site links that will connect domain controllers across the physical network. In the case of the CHI site failure, the KCC knows that since there is connectivity from CHI-NYC and ATL-CHI, then the physical network connects ATL and NYC - but the administrator didn't create an explicit site link from ATL-NYC. The KCC takes care of this oversight and replication continues between ATL and NYC, until CHI comes back on line, in which case the KCC will tear down the ATL-NYC connections and establish the original ones via CHI. We could decide to disable the Site Link Bridge (enabled by default) and simply create the ATL-NYC link, but in a large environment, this becomes difficult to manage.
It is important to this discussion to note that Windows 2000 had certain limitations that caused Microsoft to recommend that no more that about 200 sites with domain controllers be enabled in the enterprise, and that no more than about 120 sites replicate to a single hub site, with hardware configuration being a critical factor in addition to the KCC's limitations. We don't have space to go into detail on that topic, but it is well documented in public KB articles such as KB 244368: How to optimize Active Directory replication in a large network and the Branch Office Deployment Guide. A common solution was to simply disable the Sitel Link Bridge which reduced the load on the KCC and virtually eliminated the problem in most cases. Windows 2003 uses a completely different algorithm for the spanning tree that allows the KCC to eliminate those limitations and lets us use the Site Link Bridge again.
So, what does all this Site Link Bridge stuff have to do with eliminating the duplicate links created from the DR site to the remote sites in our case study? If we apply the example shown previously with the ATL, NYC and CHI sites, we can see how it works. In that example let's say that CHI was the hub site and ATL is the disaster recovery site. But instead of only NYC as a remote site, we have many other remote sites, and of course the SLB is enabled. We saw in the example, how the remote site NYC replicated to ATL when the CHI site domain controllers were unavailable. This scenario can be applied to all the other remote sites. Thus if the domain controllers in CHI become unavailable, the KCC will eventually determine CHI has no domain controllers to replicate with and will create links to ATL which allows connection objects to be built between the remote sites and ATL, completing the fail-over.
A few important points should be made:
- A low cost site link between the primary hub site and the disaster recovery site should be made to ensure replication between the two is frequent to ensure the disaster recovery site is up to date with the primary site. This also implies that the physical network should have a reliable, high speed link between the two as well.
- Do NOT create site links between the disaster recovery site and the remote sites.
- Do NOT create manual connection objects to the disaster recovery site.
- Windows 2000 does not do a great job of cleaning up old connection objects when the failed site comes back on line, requiring the administrator to do manual cleanup of old connection objects to the disaster recovery site. Windows 2003 DOES a great job of cleaning them up.
- Of course this all relies on the fact that there is physical network connectivity between the disaster recovery site and the remote sites.
- As always, be sure to test this in the lab before you put it into production. There are always things you didn't think about the first time, so make sure you don't wait for a catastrophic failure to work out the kinks.
- In the case of multiple core hub sites, when one fails, (and the Site Link Bridge is enabled), the KCC will route connections to the other nodes. They all become built-in disaster recovery sites for each other.
- The best way to control the KCC's behavior is to give it enough parameters that it can't go astray. Giving it too much freedom will usually result in replication not going the way you expect. Allowing the Site Link Bridge transitivity does just that.
The bottom line is to design the replication topology in as simple terms as possible (hub-and-spoke provides a single path to remote sites), then allow the Site Link Bridge to provide the redundancy in case of the primary hub site failure.
More on Active Directory replication
- Solving Active Directory replication failure
- Bad external time source stops Active Directory replication

![]() Disaster Recovery Planning for Active Directory
Disaster Recovery Planning for Active Directory ![]()
![]() Part 1: How creating an Active Directory replication lag site reduces disaster
Part 1: How creating an Active Directory replication lag site reduces disaster![]() Part 2: How to build redundancy in Active Directory replication
Part 2: How to build redundancy in Active Directory replication![]() Part 3: How to restore a domain controller from backup in AD
Part 3: How to restore a domain controller from backup in AD![]() Part 4: How to use Install from Media to restore a domain controller
Part 4: How to use Install from Media to restore a domain controller
Gary Olsen is a systems software engineer for Hewlett-Packard in Global Solutions Engineering. He wrote Windows 2000: Active Directory Design and Deployment and co-authored Windows Server 2003 on HP ProLiant Servers. Olsen is a Microsoft MVP for Windows Server-File Systems.
Dig Deeper on Microsoft cloud computing and hybrid services
-
![]()
How a safety-net system reached 70% colorectal cancer screening rates
By: Sara Heath
-
![]()
How telehealth is boosting care access among NYC’s homeless population
By: Anuja Vaidya
-
![]()
After Slowdown, ACO Participation in Shared Savings Program Grows
By: Jacqueline LaPointe
-
![]()
Fallon Ambulance Service Data Breach Impacts 911K Individuals
By: Jill Hughes