What is IoT (internet of things)?
The internet of things, or IoT, is a network of interrelated devices that connect and exchange data with other IoT devices and the cloud. IoT devices are typically embedded with technology, such as sensors and software, and can include mechanical and digital machines and consumer objects.
These devices encompass everything from everyday household items to complex industrial tools. Increasingly, organizations in various industries are using IoT to operate more efficiently, deliver enhanced customer service, improve decision-making and increase the value of the business.
With IoT, data is transferable over a network without requiring human-to-human or human-to-computer interactions.
A thing in the internet of things can be a person with a heart monitor implant, a farm animal with a biochip transponder, an automobile that has built-in sensors to alert the driver when tire pressure is low, or any other natural or human-made object that can be assigned an Internet Protocol address and can transfer data over a network.
How does IoT work?
IoT systems function by gathering data from sensors embedded in IoT devices, which is then transmitted through an IoT gateway for analysis by an application or back-end system.
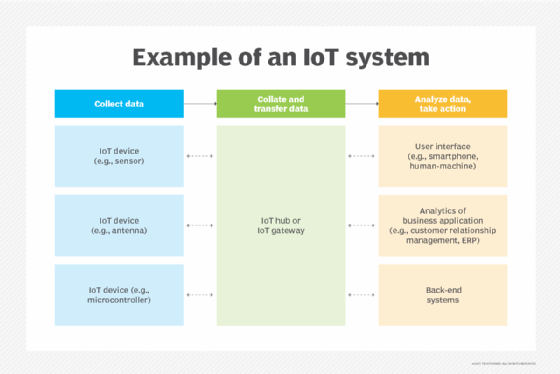
The following four elements are incorporated into an IoT ecosystem for it to function: sensors or devices, connectivity, data analytics and a graphical user interface.
Sensors or devices
An IoT ecosystem consists of web-enabled smart devices that use embedded systems -- such as processors, sensors and communication hardware -- to collect, send and act on data acquired from their environments.
Connectivity
IoT devices can communicate with one another through a network over the internet. These devices share sensor data by connecting to an IoT gateway, which acts as a central hub where IoT devices can send data. Before the data is shared, it can also be sent to an edge device where it is analyzed locally.
Data analytics
Only the relevant data is used to identify patterns, offer recommendations and identify potential issues before they escalate. Analyzing data locally reduces the volume of data sent to the cloud, which minimizes bandwidth consumption.
Sometimes, these devices communicate with related devices and act on the information they get from one another. The devices do most of the work without human intervention, although people can interact with them. For example, they can set them up, give them instructions or access the data. The connectivity, networking and communication protocols used with these web-enabled devices largely depend on the specific IoT applications deployed.
IoT can also use AI and machine learning (ML) to make data collection processes easier and more dynamic.
Graphical user interface
A graphical user interface (UI) is typically used to manage IoT devices. For example, a website or a mobile app can be used as a UI to manage, control and register smart devices.
Why is IoT important?
IoT helps people live and work smarter. Consumers, for example, can use IoT-embedded devices -- such as cars, smartwatches or thermostats -- to improve their lives. For instance, when a person arrives home, their car could communicate with the garage to open the door, their thermostat could adjust to a preset temperature, and their lighting could be set to a lower intensity and color.
In addition to automating homes through smart devices, IoT is essential to business. It provides organizations with a real-time look into how their systems work, delivering insights into everything from machine performance to supply chain and logistics operations.
When integrated into a vertical market like healthcare, which is known as the internet of medical things (IoMT), these devices can help improve efficiency and patient care.
IoT enables machines to complete tedious tasks without human intervention. Companies can automate processes, reduce labor costs, cut down on waste and improve service delivery. IoT helps make it less expensive to manufacture and deliver goods, and it offers transparency into customer transactions.
IoT also continues to advance as more businesses realize the potential of connected devices to keep them competitive.
Examples of consumer and enterprise IoT applications
The following are some common examples of IoT applications:
- Agriculture. IoT can benefit farmers by making their jobs easier. For example, sensors can collect data on rainfall, humidity, temperature and soil content, and IoT can help automate farming techniques. Additionally, IoT devices can be used to oversee the health of livestock, monitor equipment and streamline supply chain management.
- Construction. IoT can help monitor operations surrounding infrastructure. Sensors can monitor events or changes within structural buildings, bridges and other infrastructure that could potentially compromise safety. This provides benefits such as improved incident management and response, reduced operations costs and improved service quality.
- Home automation. A home automation business can use IoT to monitor and manipulate mechanical and electrical systems in a building. Homeowners can also remotely control and automate their home environment using IoT devices, including smart thermostats, lighting systems, security cameras and voice assistants such as Alexa and Siri for increased comfort and energy efficiency.
- Smart buildings and cities. Smart cities can help citizens reduce waste and energy consumption. In this application, IoT sensors can reduce energy costs by detecting how many occupants are in a room and turning the air conditioner on if they detect a conference room is full, or lowering the heat if everyone in the office has gone home.
- Urban consumption systems. IoT technologies can also monitor and manage urban consumption, such as traffic lights, parking meters, waste management systems and public transportation networks.
- Healthcare monitoring. IoT devices, such as remote patient monitoring systems, smart medical devices and medication trackers, enable healthcare providers to monitor patients' health status, manage chronic conditions and provide timely interventions. IoT gives providers the ability to monitor patients more closely by analyzing the generated data. Hospitals also often use IoT systems to complete tasks such as inventory management for pharmaceuticals and medical instruments.
- Retail. IoT sensors and beacons in retail stores can track customer movement, analyze shopping patterns, manage inventory levels and personalize marketing messages. This enhances customers' shopping experiences and optimizes store operations.
- Transportation. IoT devices help the transportation industry by monitoring vehicle performance, optimizing routes and tracking shipments. For example, the fuel efficiency of connected cars can be monitored to reduce fuel costs and improve sustainability. IoT devices can also monitor cargo condition so that it reaches its destination in optimal condition.
- Wearable devices. Wearable devices with sensors and software can collect and analyze user data, sending messages to other technologies about the users to make their lives easier and more comfortable. Wearable devices are also used for public safety -- for example, by improving first responders' response times during emergencies by providing optimized routes to a location or by tracking construction workers' or firefighters' vital signs at life-threatening sites.
- Energy management. IoT-enabled smart grids, smart meters and energy management systems enable utility companies and consumers to monitor and optimize energy usage, manage demand-response programs and integrate renewable energy sources more efficiently. For example, the data collected by the IoT devices and sensors helps identify patterns, peak usage times and areas of inefficiency.

What are the benefits of IoT to organizations?
IoT offers several benefits to organizations. Some of these advantages are industry-specific, while others are applicable across multiple industries. IoT encourages companies to rethink how they approach their operations and gives them the tools to improve their business strategies. Some of the advantages of IoT devices include the following:
- Provides easy accessibility. IoT offers easy access to information from anywhere at any time on any device. For example, IoT enhances the accessibility of information by providing real-time data and insights, intuitive interfaces and proactive alerts.
- Improves communication. IoT improves communication between connected electronic devices by enabling efficient data exchange, extending network reach, conserving energy and prioritizing critical communications. For example, if a motion sensor in a smart home ecosystem detects activity at the front door, it triggers a communication alert with the smart lighting system to turn on the outdoor lights.
- Saves time and money. IoT enables the transfer of data packets over a connected network, which can save time and money. Predictive maintenance in industrial settings is a good example of this. IoT sensors installed on machinery continuously monitor parameters, such as temperature, vibration and operating conditions, in real time. Data gathered from these sensors is analyzed using ML algorithms to detect patterns that show potential flaws or degradation in performance, which helps save both time and money.
- Optimizes supply chain. IoT data can be used to optimize supply chain and inventory management processes, enabling manufacturers to reduce costs and enhance customer satisfaction. By tracking goods and materials in real time, manufacturers can keep track of low stock, reduce excess inventory and streamline logistics operations.
- Improves efficiency. IoT analyzes data at the edge, reducing the amount of data that needs to be sent to the cloud. Edge computing enables physical devices to communicate more efficiently by processing data locally and exchanging only relevant information with other devices or cloud services.
- Provides automation. IoT automates tasks to improve the quality of a company's services and reduces the need for human intervention. For example, in agriculture, IoT-enabled irrigation systems can automatically adjust watering schedules based on soil moisture levels, weather forecasts and crop requirements.
- Improves customer experience. IoT enables the development of personalized products and services tailored to individual preferences and needs. Smart home devices, wearable technology and personalized recommendations in retail are examples of how IoT enhances the customer experience.
- Provides flexibility. IoT options can be scaled according to an organization's changing needs. Whether adding new devices, expanding operations or integrating with existing systems, IoT provides the flexibility to scale and evolve with business requirements.
- Enables better business decisions. IoT generates vast amounts of data that can be analyzed to gain valuable insights into operations, consumer behavior and market trends. By harnessing and analyzing big data, businesses can make data-driven decisions, optimize processes and identify new revenue opportunities.
- Offers environmental sustainability. IoT enables efficient resource use and reduces negative environmental effects through initiatives such as smart energy management, waste reduction and sustainable agriculture practices. By optimizing resource utilization and minimizing waste, IoT contributes to environmental sustainability.
IoT challenges for businesses
Along with its various advantages, IoT also comes with some potential drawbacks, including the following:
- Security concerns. IoT increases the attack surface as the number of connected devices grows. As more information is shared between devices, the potential for a hacker to steal confidential information increases.
- Complex management. Device and data management become more challenging as the number of IoT devices increases. Organizations might eventually have to deal with a massive number of IoT devices, and collecting and managing the data from all those devices could be difficult.
- Corruption of connected devices. If a bug in the IoT system corrupts one device, it has the potential to corrupt other devices connected to the internet.
- Compatibility issues. IoT increases compatibility issues between devices, as there's no international standard of compatibility for IoT, which causes platform fragmentation. Platform fragmentation refers to the proliferation of diverse and incompatible IoT platforms, protocols and standards, which can hinder interoperability and integration between different devices and systems. For example, many IoT vendors develop proprietary platforms and protocols that are tailored to their specific products and ecosystems. This results in a lack of standardization and interoperability, as devices from different manufacturers use incompatible technologies.
- Job displacement. Due to decreased human intervention in various tasks, IoT can result in job displacement for low-wage workers or those with limited experience. For example, inventory task automation and the use of ATMs have reduced the need for manual labor and human intervention, leading to job losses and job insecurity for those currently employed in such roles.
- Regulatory and legal hurdles. With the proliferation of IoT devices, legal hurdles are also increasing. Businesses must adhere to diverse data protection, privacy and cybersecurity regulations, which can differ from one country to another.
- Data storage. The amount of data IoT collects requires large amounts of storage, meaning organizations must also scale their storage infrastructure to match the amount of data they collect.
- Unclear value proposition. IoT processes might be wasted if the implementing organization doesn't have a clear picture of how to gain insights from its collected data.
- Barriers to adoption. IoT requires an upfront deployment and implementation cost, as well as expertise to make use of the collected data properly. Along with other presented challenges, IoT adoption might face different barriers from business to business.
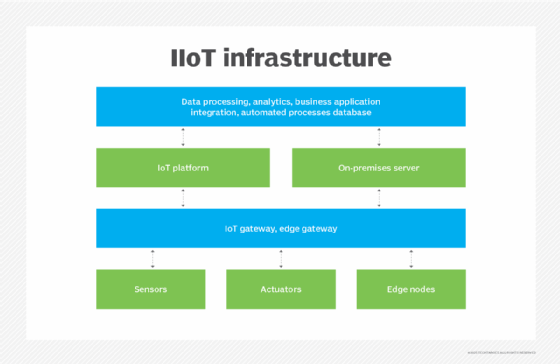
What is IIoT and how is it transforming industries?
IIoT, or the industrial internet of things, is a narrower application of IoT aimed at the industrial sector, such as manufacturing, energy management, utilities, oil or gas. The goal of IIoT is to enhance manufacturing and industrial processes by regulating and monitoring industrial systems.
Smart sensors, actuators, radio frequency identification tags and other IoT devices are embedded into industrial equipment and infrastructure and are networked together to provide data collection, exchange and analysis.
In manufacturing and industrial settings, IIoT has the potential to improve quality control, predictive maintenance, employee safety, supply chain efficiency, energy management and asset tracking.
IoT standards and frameworks
Notable organizations involved in the development of IoT standards include the following:
- Connectivity Standards Alliance.
- IEEE (Institute of Electrical and Electronics Engineers).
- Industry IoT Consortium.
- International Electrotechnical Commission.
- Internet Engineering Task Force (IETF).
- Open Connectivity Foundation.
- Thread Group.
The following are some examples of IoT standards:
- 6LoWPAN. Short for IPv6 over Low-Power Wireless Personal Area Networks, 6LoWPAN is an open standard defined by the IETF. It enables any low-power radio to communicate with the internet, including 804.15.4, Bluetooth Low Energy and Z-Wave for home automation. This standard is also used in industrial monitoring and agriculture.
- Zigbee. This low-power, low-data-rate wireless network is used mainly in home and industrial settings. Zigbee is based on the IEEE 802.15.4 standard. The Zigbee Alliance created Dotdot, the universal language for IoT that enables smart objects to work securely on any network and understand each other.
- Data Distribution Service. DDS was developed by the Object Management Group and is an IIoT standard for real-time, scalable and high-performance machine-to-machine communication.
IoT standards often use specific protocols for device communication. A chosen protocol dictates how IoT device data is transmitted and received. Some example IoT protocols include the following:
- Constrained Application Protocol. The IETF designed CoAP, a protocol that specifies how low-power, compute-constrained devices can operate in IoT.
- Advanced Message Queuing Protocol. The AMQP is an open source published standard for asynchronous messaging by wire. AMQP enables encrypted and interoperable messaging between organizations and applications. The protocol is used in client-server messaging and IoT device management.
- Long-Range Wide Area Network (LoRaWAN). This protocol for WANs is designed to support huge IoT networks, such as smart cities, with millions of low-power devices.
- MQ Telemetry Transport. MQTT is a lightweight protocol used for remote control and remote monitoring applications. It is suitable for devices with limited resources.
IoT frameworks include the following:
- Arm Mbed IoT. This is an open source platform for developing apps for IoT based on Arm microcontrollers. The goal of this IoT platform is to provide a scalable, connected and secure environment for IoT devices by integrating Mbed tools and services.
- AWS IoT. Amazon Web Services released this cloud computing platform for IoT. Its framework is designed to enable smart devices to easily connect and securely interact with the AWS cloud and other connected devices.
- Microsoft Azure IoT Suite. This set of services enable users to interact with and receive data from their IoT devices, as well as perform various operations over data -- such as multidimensional analysis, transformation and aggregation -- and visualize those operations in a way that's suitable for business.
IoT security and privacy issues
IoT connects billions of devices to the internet and involves the use of billions of data points, all of which must be secured. Due to its expanded attack surface, IoT security and IoT privacy are cited as major concerns.
One of the most notorious IoT attacks happened in 2016. The Mirai botnet infiltrated domain name server provider Dyn, resulting in major system outages for an extended period of time. Attackers gained access to the network by exploiting poorly secured IoT devices. This is one of the largest distributed denial-of-service attacks ever seen, and Mirai is still being developed today.
Because IoT devices are closely connected, a hacker can exploit one vulnerability to manipulate all the data, rendering it unusable. Manufacturers that do not update their devices regularly -- or at all -- leave them vulnerable to cybercriminals. Additionally, connected devices often ask users to input their personal information, including name, age, address, phone number and even social media accounts -- information that is invaluable to hackers.
Hackers are not the only threat to IoT; privacy is another major concern. For example, companies that make and distribute consumer IoT devices could use those devices to obtain and sell users' personal data. To ensure the safe and responsible use of IoT devices, organizations must provide education and awareness about security systems and best practices.

What technologies have made IoT possible?
Many technological advancements have accelerated IoT. Here are a few key advancements:
- Sensors and actuators. Sensors detect environmental changes, such as temperature, humidity, light, motion or pressure, while actuators cause physical changes, such as opening a valve or turning on a motor.
- Connectivity and network protocols. The availability of a host of network protocols for the internet has made it easy to connect sensors to the cloud and to other devices, facilitating efficient data transfer. IoT employs a range of connectivity technologies, including Wi-Fi, Bluetooth, cellular, Zigbee and LoRaWAN.
- Low-cost and low-power sensor technology. Because dependable and reasonably priced sensors are available, more manufacturers have access to IoT technology. These sensors enable data to be gathered from the real world, which is then transferred to and analyzed in the digital domain.
- AI and natural language processing. Due to the developments in neural networks, IoT devices now feature natural language processing, which makes them appealing and useful for a wide range of applications, such as conversational AI assistants and digital personal assistants.
- Microservices and wireless technologies. IoT has evolved from the convergence of wireless technologies, microelectromechanical systems and microservices. All these advancements have facilitated seamless connectivity and data exchange between devices and the cloud.
- Edge computing. Edge computing pushes data processing as close to the data source as possible, reducing latency and bandwidth.
- Cloud computing. IoT collects large amounts of data. Cloud computing enables an organization to scale up its storage infrastructure as needed to match the amount of data collected.

Future IoT outlook and trends
According to Forbes, the IoT healthcare market is predicted to grow to around $150 billion and be valued at $289 billion by 2028. Likewise, IoT in healthcare has expanded the use of wearables and in-home sensors that can remotely monitor a patient's health.
The number of IoT devices is also expected to grow over time, driven by their adoption and new uses in different industries. Connectivity technologies such as 5G, Wi-Fi 6, low-power WANs and satellites are also enhancing IoT adoption, while wearable devices such as smartwatches, earbuds and augmented reality/virtual reality headsets are increasingly evolving and growing in adoption.
Key trends related to IoT are likely to continue improving. For example, the AI and ML models used to collect and analyze data have become increasingly important for organizations and will continue to develop into more reliable technology. For example, AI models used in IoMT will likely continue to be advanced through more explainable AI models that are able to give further transparency into their actions.
Technological convergence, which occurs when unrelated technologies are merged, is also likely to be a driving force behind the general improvement of IoT. For example, 5G, edge computing and artificial intelligence of things, or AIoT, all serve to improve the operation and efficiency of IoT systems.
The industry is also likely to see related IoT services continue to improve, such as AWS IoT, which provides cloud services that connect to an organization's IoT devices, or Azure IoT Edge, which enables containerized workloads to run on edge devices.
IoT is a growing market, and many different developing technologies are pushing it forward. Learn about more current and potential future trends in IoT.





