Ultimate IoT implementation guide for businesses
IoT implementation involves many considerations, including security, network connectivity, data aggregation, and analytics and device management and control.

The internet of things, or IoT, provides organizations with real-time data and business insights that, when acted upon, can improve processes and operations to be more accurate, efficient and safer. IT administrators, architects, developers and CIOs planning an IoT deployment must clearly understand what IoT is, how it works, its uses, requirements, tradeoffs and how to implement IoT devices and infrastructure.
What is IoT and how does it work?
IoT is a network of dedicated devices -- called things -- designed to gather and exchange real-world data across networks. These devices work together to collect information, transmit it for processing and enable actions based on that data.
Key concepts of IoT are as follows:
- Focus on real-world data. Unlike static digital information -- such as documents and images -- IoT devices produce data reflecting physical conditions in real time, enabling businesses to learn what's happening and exercise dynamic control.
- Real-time operation. IoT data must be delivered and processed without delay, making network bandwidth and connectivity crucial. Data usefulness is often measured in seconds, especially for medical monitoring and other such critical applications.
- Data purpose. IoT projects are defined by their business objectives. Often, IoT data forms part of a control loop with cause-and-effect relationships. For example, a sensor detects an unlocked door, and an actuator allows remote locking.
- Scale and scope. IoT deployments can involve hundreds to thousands of sensors collecting various parameters, such as temperature, pressure or location. These vast data collections often fuel big data initiatives, machine learning (ML) and AI projects.
An IoT system includes four basic elements:
- Things. Every IoT device -- a thing or smart sensor -- is a small, dedicated computer with embedded processors, firmware, limited memory and network connectivity. They collect specific physical data, transmit it using networks and typically operate on battery power with unique IP addresses.
- Connections. Data travels through conventional IP-based networks (Ethernet, internet) using wireless interfaces (Wi-Fi, 5G). IoT gateways collect and preprocess raw sensor data through normalization and filtering.
- Back end. The collected data moves to processing centers (corporate data centers or cloud infrastructure) where it's stored, processed and analyzed using computing clusters.
- Interface. Although IoT enables automation beyond human capabilities, systems include human interfaces (alerts, dashboards, reports) that let operators monitor and control the IoT infrastructure. For example, a smart home needs an interface that lets the homeowner set the indoor temperature.
What are the layers of an IoT architecture?
Although the scope and detail of an IoT architectural plan can vary depending on the IoT initiative, leaders must consider how IoT will integrate into the current IT infrastructure.
Depending on the specific model, an IoT architecture can have up to seven major layers. These layers are like the Open Systems Interconnection networking model in that they can be discussed from bottom to top.
1. Device layer
This layer includes the devices that convert the physical world into digital data and vice versa through actuators. Devices comprise sensors and actuators that can number hundreds of thousands for an IoT deployment. Each device connects to a network using either wired or, more commonly, wireless connections.
2. Network layer
The network layer connects IoT devices and transfers data and commands between devices and computing resources. It includes IoT and network gateways and can also incorporate data aggregation or preprocessing methods, such as edge computing, to minimize the amount of raw data exchanged across the network.
3. Edge processing (preprocessing) layer
Large IoT deployments can strain network capacity, and decision-making is often relevant at the edge. Therefore, edge computing is regularly used to collect and preprocess IoT device data, enabling certain compute and analytics operations to be performed locally for greater efficiency instead of sending all raw data back for centralized processing.
4. Data storage layer
IoT systems routinely generate massive amounts of raw data. Like other business data, this data becomes a business asset and is subject to storage, security and regulatory considerations, such as retention and proper use policies. The data storage layer manages IoT data's storage, protection, organization and access.
5. Computing layer
This layer handles the central processing in IoT deployments. It's where vital IoT data is collected, stored and used for business decisions. Some processing might happen at the edge, where data is first preprocessed, normalized and aggregated. However, more detailed analysis can also occur at the primary data center. Using edge computing to reduce data load enables centralized layers to decrease network traffic and data center resources to focus on more advanced applications.
6. Application layer
At the highest level, an application layer handles user interactions, such as device management or environment control. However, the application layer is mainly where a primary data center ingests data delivered from the computing layer and performs detailed analytics and reporting on the IoT data.
7. Business use layer
This isn't a technology layer but rather a business strategy stage where business leaders can review performance and assess the value of IoT outcomes to the business. This is where IoT system design and use case must align with the larger business strategy.
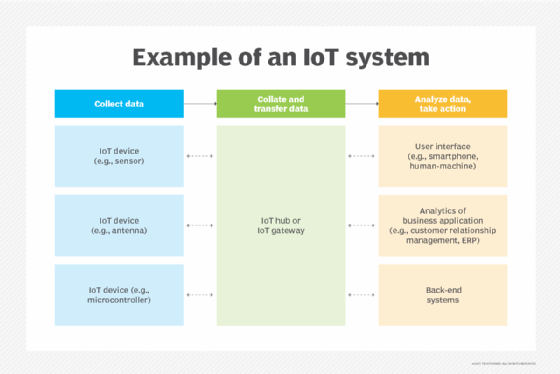
There are four major architectural issues to consider: infrastructure, security, integration, and analytics and reporting.
1. Infrastructure
The physical layer includes IoT devices, the network and computing resources used to process data. Infrastructure often covers sensor types, quantities, locations, power, network interfaces and configuration and management tools. Networks must account for bandwidth and latency to handle IoT device demands. Computing handles IoT data analytics on the back end, and organizations might need to deploy new resources or use on-demand options, such as the public cloud.
The infrastructure discussion also involves choosing IoT protocols and available connectivity standards such as Bluetooth Low Energy (BLE), 5G, Wi-Fi, Zigbee, long-range WAN, narrowband IoT and low-power wireless personal area networks.
2. Security
IoT data can be sensitive and confidential, such as patient medical telemetry data. Transmitting such data over open networks can expose devices and information to snooping, theft and hacking. Organizations planning an IoT project must consider IoT privacy and the best methods to secure IoT devices and data both in transit and at rest. Encryption is a common approach to IoT data security.
Additional measures should also be implemented on IoT devices to prevent hacking and malicious modifications to device configurations. Security involves a range of software tools and traditional security devices, such as firewalls and intrusion detection and prevention systems.
3. Integration
This involves making everything work together seamlessly, ensuring that devices, infrastructure and tools added for IoT can interoperate with an organization's existing systems and applications, such as systems management and ERP. Proper IoT integration requires careful planning, proof-of-principle testing and a well-researched selection of IoT tools and platforms like Apache Kafka or OpenRemote.
4. Analytics and reporting
The highest level of IoT architecture requires a clear understanding of how IoT data will be analyzed and used -- what the business aims to achieve with the IoT system. This is the application layer, which often includes analytical tools, AI and ML modeling and training engines, and data visualization or rendering tools. These tools can be obtained from third-party vendors or accessed through cloud providers where data is stored and processed. Note, though, that IoT data visualization comes with its own challenges.
Business use cases for IoT
The wide range of small and capable IoT devices has found significant business applications across most major consumer, industrial, medical and government sectors. Consider some of the growing use cases in six key industries.
1. Smart building automation
IoT devices appear in construction and facilities for energy management, security and even some task automation:
- Thermostats and lighting can be scheduled and controlled through internet applications.
- Motion-activated sensors can trigger video and audio streams to homeowner smartphones.
- Water sensors can watch basements or equipment-sensitive areas for leaks.
- Smoke, fire and carbon dioxide detectors can report danger to users and first responders.
- IoT actuators can lock and unlock doors remotely.
2. Manufacturing
IoT devices have been broadly adopted in all manufacturing and industrial settings. Examples of industrial IoT (IIoT) include the following:
- IIoT tags can track, locate and inventory enterprise assets.
- IIoT devices can help monitor and optimize energy use, such as lowering lighting when human-occupied areas are idle or lowering temperature settings during off-hours.
- IIoT sensors and actuators can support process automation and optimization.
- IIoT devices can monitor all machine behaviors and parameters during regular operation, enabling ML algorithms to guide predictive maintenance to optimize process uptime.
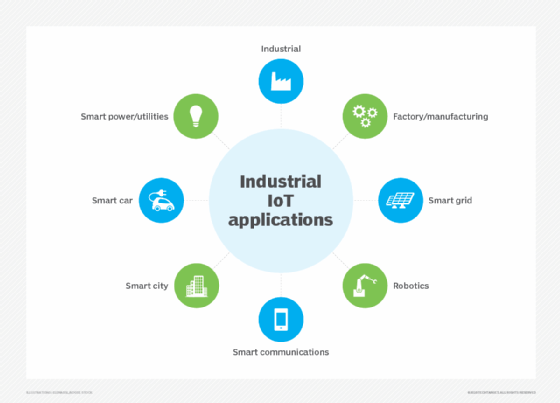
3. Public/safety
IoT sensors with cellular-class connectivity can operate collaboratively across metropolitan areas to serve a wide range of purposes:
- IoT devices can detect the presence of vehicle traffic, enabling cities to adjust street lighting on idle streets and off-hours.
- Crime prevention efforts might include camera-based surveillance, while connected audio detection can direct police to areas where gunfire is detected.
- Cameras can be used to determine and optimize traffic, while transponders and cameras can read license plates or toll boxes to direct toll collection and management.
- Interconnected parking systems enable cities to track parking spots and alert drivers to available spots through an app.
- Sensors can watch bridges and other structures for stress and problems, enabling early detection and remediation.
- Sensors can monitor water quality, enabling early detection of contaminants or pollutants.
4. Medical/health
IoT is present in remote patient telemetry and other medical uses. Examples of the internet of medical things (IoMT) include the following:
- IoMT exists in countless wireless, wearable devices, including blood pressure cuffs, heart rate monitors and glucometers. Devices can be tuned to track calorie expenditure against exercise goals and remind patients of appointments or medications.
- IoMT enables early-warning devices, such as fall detection pendants, that alert health providers and family members and even provide location information for potential issues.
- With IoMT's remote monitoring capabilities, health providers can track patient health and adherence to treatment plans and better correlate health issues with telemetry data.
- Hospitals can use IoMT to tag and track the real-time location of medical equipment, including defibrillators, nebulizers, oxygen and wheelchairs.
- IoMT in staff badges can help locate and direct medical staff more efficiently.
- IoMT can help control other equipment, such as pharmacy inventory systems, refrigerator temperatures and humidity and temperature control.
- IoMT hygiene-monitoring equipment can help ensure that medical environments are clean and reduce infection.
5. Retail
IoT and big data analytics have found extensive use in retail sales and physical store environments:
- IoT devices can tag every product, enabling automated inventory control, loss prevention and supply chain management (SCM) so that retailers can place orders based on sales and inventory levels.
- Cameras and other surveillance technologies can watch shopper activity and preferences, helping retail stores optimize layouts and organize related products to maximize sales.
- IoT devices can support touchless and scanless checkout and payment, such as near-field communication payment.
6. Fleet management
Logistics and transportation companies can use IoT to enhance fleet management by optimizing routes, increasing driver safety and lowering operational costs:
- GPS trackers can monitor vehicle locations to determine arrival times based on speed and prevailing traffic conditions.
- Fuel monitoring devices can track fuel usage and calculate efficiency.
- Vehicle monitoring devices can check for wear and diagnostic issues, helping schedule preventive maintenance and avoid vehicle downtime.
- Speed monitoring can help drivers comply with speed limits and improve driver safety.

What are the business benefits of implementing IoT?
Benefits of IoT implementation can include the following advantages.
Data-driven decision-making
IoT offers immediate knowledge by measuring and reporting specific real-world conditions. Using modern tools, such as a thermostat in a building that measures current temperatures to control heating or cooling, real-world conditions can be examined and responded to instantly.
Suppose a medical heart rate monitor detects an excessive heart rate. In that case, the patient can slow down, relax to lower the heart rate, take appropriate medication, contact their doctor for further guidance or even call for medical help.
If a traffic monitoring system detects a backup on a major highway, it can update travel apps with current conditions and help commuters choose alternate routes to avoid congestion.
Long-term analytics
IoT's true power and benefits are the long-term insights it can offer business leaders.
Think about the countless IoT sensors that can be placed on equipment, vehicles, buildings, factories, campuses and municipal areas, enabling better long-term insight through advanced analytics: the back-end computing processes capable of analyzing and correlating large amounts of unrelated data to answer business questions and make accurate predictions about future conditions.
This can result in significantly improved operational efficiency and better resource management.
Natural relationship with ML and AI
The data collected and analyzed from IoT fleets can also be used to train ML models, supporting the development of AI initiatives that gain a deep understanding of the data and its relationships.
For example, sensors placed throughout a vehicle or industrial machine can be analyzed to identify operational and condition changes, which might indicate the need for maintenance or even predict a potential failure.
Such insights enable a business to order parts, schedule maintenance or make proactive repairs while minimizing the disruption to normal operations.
Cost savings
All the benefits outlined here can potentially lead to cost savings through improved logistics, lower usage of resources such as fuel or electricity, more effective SCM and otherwise-unrecognized business opportunities.
IoT services and business models
Setting up countless individual IoT devices can be overwhelming, but analyzing that data to extract valuable business insights can also pose challenges. As the IoT industry advances, the ecosystem is growing to support new implementations and enable innovative business models.
One of the biggest challenges with IoT is getting it to function correctly. Infrastructure requirements can be extensive, security is often a concern, and network and processing loads can introduce additional complexity.
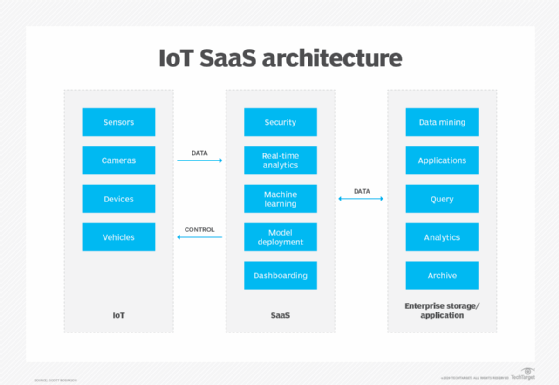
IoT vendors are addressing these issues with a growing number of SaaS platforms designed to simplify IoT adoption and reduce the need for deep investments in gateways, edge computing and other IoT-specific components.
IoT SaaS operates between IoT devices and the enterprise, handling many essential functions the enterprise would otherwise need to handle.
For example, the SaaS manages routine infrastructure tasks, such as data security and reporting, but often includes advanced processing and computing, like analytics, with added support for ML. This eases the burden on the enterprise data center and IT team, letting the business focus on the generated analyses.
IoT SaaS offerings have similar features, so carefully evaluate the pricing to choose the provider best suited to your organization's number of IoT devices, data volumes and analytical needs.
Currently, there are dozens of IoT SaaS providers, and an internet search for IoT SaaS services reveals a wealth of specialized providers and tools, including the following:
- 2Base Technologies IoT Development.
- AJProTech Solutions for IoT.
- AllGuard by GuardRFID.
- Apexon end-to-end IoT development services.
- Blues Inc.
- Brightware by Bright Machines.
- Canopy.
- Cheesecake Labs.
- EPAM Systems.
- Eviden.
- EY IoT Consulting Services.
- Fosfor Decision Cloud by LTIMindtree.
- Fujitsu Hyperconnected Industry Solutions.
- GE Vernova.
- Hitachi Digital Services.
- HPE.
- Innfini IoT Platform by Innovent.
- Intellias IoT services.
- Intersog IoT App Development.
- Intetics.
- IoT.nxt by Vodafone.
- MeShare IoT platform.
- Mutual Mobile (now Grid Dynamics).
- Saviant Consulting.
- ScienceSoft IoT services.
- Seasia Infotech IoT development services.
- ThoughtFocus Industry X.
- Toshiba IoT Solution Pack.
- UST.
- Volo custom IoT services.
- World Wide Technology IoT services.
- Zoi.
IoT SaaS providers differ in size and capabilities, often serving specific industries, such as healthcare or manufacturing. It's essential to choose a provider that specializes in the target industry and can deliver the necessary services, scalability and reliability.
As the IoT industry grows, businesses will discover that IoT tools and software are becoming more accessible in three main areas of the technology stack:
- Devices and edge. This lowest layer of the IoT stack includes IoT devices, OSes, edge management and security platforms, and data ingestion/preprocessing tools and platforms.
- Middleware. The middle layer of the IoT stack includes a wide range of middleware and platforms, such as databases, message brokers, data ingestion and management tools, and more comprehensive IoT platforms designed to reduce the infrastructure burden for businesses.
- Applications. The highest layer of the IoT stack includes applications such as data access, processing (analysis), reporting and visualization tools that enable businesses to work with the collected IoT data.
IoT is transforming business operations and enabling various new business models that will enable organizations to generate revenue from IoT projects and products. Companies are increasingly exploring ways to monetize and incorporate IoT data as new growth avenues and revenue streams.
There are at least four types of business models that IoT can effectively support:
- Salable data. The raw data gathered by IoT devices can readily be monetized. For example, the data collected by a personal fitness tracker or weight data gathered from IoT home scales might interest health insurance companies seeking to adjust premiums based on consumer fitness activity and physical state.
- B2B and B2C. IoT is all about collecting and analyzing data, and such analytics can be used to identify and optimize brand loyalty or drive additional sales based on business needs or consumer activities identified by IoT devices.
- IoT platforms. The data and analytics IoT yields can form the foundation of platforms that offer AI services -- Amazon's Alexa, for instance. Those platforms continue to learn and improve with a wealth of real-world IoT data, and third-party businesses can integrate the services offered for a fee.
- Pay-per-use. IoT technologies readily facilitate businesses such as bicycle or scooter rentals. GPS can locate equipment, which users with corresponding apps can find, access, use and pay for automatically. IoT data can analyze utilization and maintenance patterns to optimize the business process.
What are the requirements for implementing IoT?
There is no universal approach to designing and implementing an IoT infrastructure. Still, a common set of considerations can help organizations ensure they cover all the bases to successfully build and deploy an IoT project. Below are some key implementation considerations.
Network connectivity
IoT devices have several connectivity options, including hard-wired connections, Wi-Fi, Bluetooth, 4G and 5G. Although there's no requirement for all devices to use the same connection type, standardizing one can make device setup and IoT monitoring easier. Additionally, decide whether sensors (inputs) and actuators (outputs) should share the same network or use separate, segmented or isolated networks.
IoT hub
Simply transmitting all IoT data directly from devices to an analytics platform can result in disparate connections and poor performance. An intermediary platform, such as an IoT hub, can help organize, preprocess and encrypt data from devices across an area before forwarding it for analysis. If a remote facility is IoT-enabled, a hub might collect and preprocess that IoT data at the edge before sending it for further analysis.
Aggregation and analytics
Once the data is collected, it can be used to drive reporting systems and actuators or for deeper analysis, querying and other big data purposes. Choose software tools to process, analyze, visualize and enable ML. For example, select appropriate IoT database types and architectures: SQL versus NoSQL, or static versus streaming. These tools might be deployed locally in data centers or accessed through SaaS platforms or cloud providers.
Device management and control
Use a software tool capable of reliably managing all IoT devices throughout the project's lifecycle. Look for high levels of automation and group/asset monitoring and management features to simplify configuration and minimize errors. IoT device patching and updates are becoming challenging, so organizations should focus on effective update and upgrade processes. Use a comprehensive device dashboard to monitor and control IoT device fleets with meaningful metrics.
Security
Every IoT device poses a potential security risk, so an IoT implementation must carefully consider IoT configuration and integration into existing security tools and platforms, such as intrusion detection and prevention systems and antimalware tools. Likewise, the data generated by IoT devices must be managed with data protection, compliance and retention requirements in mind.
Storage and computing infrastructure
Although much of the focus is on IoT devices and support, it's crucial to consider what happens to the massive amount of data generated by the IoT infrastructure. IoT data must be stored and then analyzed using significant computing resources.
Sometimes, this involves terabytes, petabytes and even exabytes of data processed across dozens or hundreds of servers dedicated to big data computing. The storage and processing infrastructure can be local, but it is increasingly shifting to public cloud providers.
Iterate and optimize
IoT deployment is an ongoing process. Regular updates and patches, new devices and issue resolutions drive continuous evaluation and improvements. This can include adding new devices, increasing storage or network bandwidth and refining data management and retention strategies.
Learn more about IoT
IoT and digital twins: How they work together, with examples
Discover how IoT and digital twins create virtual replicas of physical assets to revolutionize operational efficiency and decision-making processes.
Top IoT interview questions and answers
Prepare for your next IoT job interview with this guide to the most challenging questions and expert-crafted responses that will set you apart from other candidates.
Best IoT conferences and events to attend
Expand your professional network and stay ahead of emerging IoT trends by attending these industry-leading conferences.
Top IoT blogs to follow
Stay at the cutting edge of IoT developments by following these influential blogs that deliver timely insights, technical deep-dives and industry analysis from recognized thought leaders.
Top IoT online courses to boost your career (free and paid)
Accelerate your career growth in the IoT sector with these online courses that range from beginner fundamentals to advanced specializations for every budget.
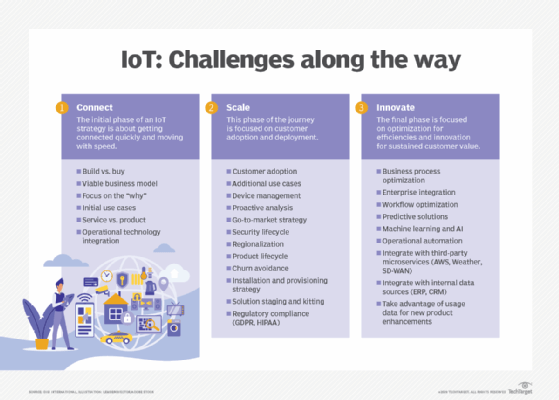
4 steps for IoT implementation
As mentioned above, implementing IoT involves many technical factors, such as choosing and deploying devices, ensuring network connectivity, developing analytical capabilities and computing power and establishing network and data security. However, all these factors pertain to the actual construction and operation of an IoT infrastructure.
For many organizations, the initial questions are much simpler: Why take on an IoT project, and how do we begin? Start with these four steps:
- Begin with a clear strategy. IoT initiatives can vary widely in purpose, capabilities and scope. Like any IT project, an IoT initiative must start with a well-defined strategy that outlines its purpose and explicitly states its goals. This initial plan should also highlight the project's intended value -- such as increased productivity or reduced costs through predictive maintenance -- to justify the necessary financial and intellectual investment. A skills assessment and cross-functional training roadmap should be developed early to identify knowledge gaps and ensure team members have the specialized IoT expertise required for successful implementation.
- Consider the infrastructure. With a strategy in mind, the business typically moves into a research and experimentation phase to identify IoT products, services and software. Project managers then carry out limited proof-of-concept projects to showcase the technology and improve its deployment and management approaches, such as those involving configuration and security. This is where a business can evaluate and address many implementation challenges, including IoT device firmware updates, IoT device and network security and IoT device power management.
- Consider how to use the data. At the same time, analysts evaluate ways to use the resulting data and understand the tools and computing infrastructure needed to derive business intelligence from it. This might involve using limited data center resources for small-scale analytics, with an eye toward public cloud resources and services as the IoT project scales.
- Pick an approach. A business can approach an IoT project in three ways:
- Experimental. Assemble a limited or test platform and let business and technology leaders find value, similar to how a business might start its first test projects in a public cloud.
- Comprehensive and formal. Employ a clear project blueprint, including goals and a project timeline.
- A full commitment to IoT across the organization. Such an effort usually requires more expertise and confidence in IoT than others.
Regardless of the specific approach, the key is to remain focused on IoT and its data's value to the business. Ultimately, an IoT implementation must address tangible business needs, and objective metrics can measure its success.
What are the risks and challenges of implementing IoT?
Although their risks are well understood, IoT devices' sheer volume and diversity require greater attention and control than a business might otherwise exercise. The following encompasses some of the most detrimental risks of IoT environments.
Poor project design
Although IoT devices readily adopt various standards like Wi-Fi or 5G, there are currently no major international standards guiding the design and implementation of IoT architectures, nor is there a widely accepted rulebook for approaching an IoT project. This provides significant flexibility in design but also opens the door to major flaws, vulnerabilities and oversights.
IoT projects should be led by IT staff with IoT expertise, but that expertise is continually evolving. There is no substitute for careful, well-planned design and proven performance based on extensive testing and proof-of-concept projects.
Inability to discover all IoT devices
IoT tools and practices must be able to detect and configure all IoT devices in the environment. Undiscovered devices are unmanaged or orphaned, which might not provide valuable data and could serve as attack points for hackers to access the network. Administrators must be able to identify and manage all IoT devices on the network. Incompatible devices can be challenging to manage properly, if at all.
Weak or absent access control
IoT security relies on robust protection through proper authentication and authorization for each device. Each device's unique identifier enhances this, but it remains crucial to configure each IoT device for least privilege or zero trust, granting access only to necessary network resources for IoT operation and data transfer.
Enhance security by using strong passwords and enabling network encryption on all IoT devices. Default passwords must be changed, and all IoT middleware, platforms and applications should implement proper access control.
Lack of storage security
IoT generates vast amounts of raw data, a business asset that must be protected and monitored. Encryption is highly recommended for data in transit, whether from IoT devices or during processing, and at rest -- i.e., when stored on media.
Additionally, data storage should follow data retention and appropriate use policies, ensuring only authorized users can access and use it for approved business purposes. Data should also be destroyed when its retention period expires or be stored securely in proper long-term archives.
Ignored or overlooked device updates
IoT devices often need regular software and firmware updates or patches. Ignoring or missing these updates can leave IoT devices vulnerable to hacking or unauthorized access. Therefore, it is essential to plan and implement update strategies when designing an IoT environment.
Some devices can be difficult or impossible to update on-site -- often because of low-bandwidth network speeds -- and might even be hard to access or take offline. These factors are a key part of IoT device management and should be considered during the planning stage of an IoT project.
Poor or weak network security
IoT deployments can add thousands of devices to a LAN, each opening a potential access point for intrusion. Organizations often implement additional network-wide security measures for IoT, including intrusion detection and prevention systems, tightly controlled firewalls, strong data encryption and comprehensive antimalware tools. They might also opt to segment the IoT network from the rest of the IT network.
Lack of security policy or process
Policy and process are vital for proper network security. They represent the combination of tools and practices used to configure, monitor and enforce device security across the network. Adequate documentation, clear configuration guidelines and rapid reporting and response are all part of IoT and everyday network security. Successful IoT policies and processes are often the result of experience, but they should align with existing IT policies and processes.
Weak or inadequate device management
IoT devices aren't just a software issue; each one represents a physical device or endpoint that needs management and maintenance. Every IoT device must be procured, prepared, installed, connected, configured, managed, maintained, replaced or retired.
Handling this for a few servers is one thing, but it's entirely different when dealing with hundreds, thousands or even tens of thousands of IoT devices. Issues like device failures, replacements, power support -- including battery replacements -- and the physical integrity of each device's installation require careful planning and staffing.
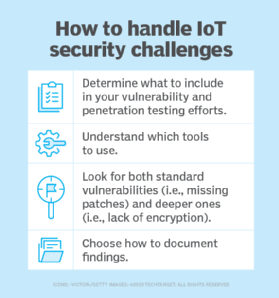
IoT security and compliance
IoT deployments face unique security challenges due to their scale and nature:
- Volume. Tens or hundreds of thousands of devices create an enormous attack surface.
- Weak security features. Many devices have inadequate security standards, including default or easily guessed passwords.
- Limited computing power. Devices are designed for battery efficiency, making firmware updates difficult and time-consuming.
- Management complexity. IoT requires specialized tools to discover, configure and monitor all devices.
- Network vulnerabilities. Shared networks with regular computing devices increase threat exposure.
Effective IoT security revolves around three fundamental issues:
- Design. Select devices with strong security capabilities and plan their implementation from the beginning. Create separate, protected networks specifically for IoT devices.
- Process. Implement tools and practices that properly configure every device, including regular firmware updates. Avoid orphaned devices requiring manual intervention.
- Diligence. Use management tools to monitor configurations and security tools to detect intrusions or malware.
Still, IoT devices face numerous security vulnerabilities, including botnet attacks, weak DNS systems susceptible to malware, unauthorized network access and physical tampering. These threats directly affect organizational compliance; stolen patient data or ransomware attacks, for instance, can create regulatory nightmares and operational disruptions.
The IoT landscape lacks universal security standards, forcing businesses to document their design decisions and align with existing IT best practices. Although selecting devices that follow established standards -- such as IPv6, BLE and Zigbee -- provides a foundation, these connectivity protocols alone can't ensure comprehensive security.
Fortunately, industry organizations are developing more robust frameworks. The IEEE 2413-2019 standard offers a common architectural approach across multiple domains, while IEEE 802.15.4 defines critical physical and media access layers for wireless networks used in many IoT implementations. When properly implemented, these standards can significantly strengthen compliance efforts.
Effective IoT security requires integration with existing IT compliance initiatives. This holistic approach addresses equipment selection, configuration management and personnel training, ensuring IoT devices receive the same security oversight as other enterprise systems.
Organizations must update business guidelines to incorporate IoT data management and security protocols, treating connected devices as full members of the enterprise technology ecosystem, requiring appropriate protection and monitoring.
What is the future of IoT in the enterprise?
The future of IoT remains hard to predict because the technology and its applications are still relatively new and have great growth potential. New IoT applications and use cases are continuing to emerge. By about 2030, it's expected that there will be over 25 billion IoT devices in use, with 75% of all devices anticipated to be IoT-connected or IoT-capable by then.
When it comes to enterprise IoT, there are several important trends to watch.
Advanced connectivity evolution
As IoT devices grow more numerous and sophisticated, the demand for increased network bandwidth will promote widespread adoption of advanced connectivity like 5G and upcoming standards. 5G technologies offer lower latency, network sharing, real-time data processing and dependable coverage across large geographic regions.
Enhanced security frameworks
In the coming years, we will likely see a reevaluation and dramatic increase in IoT security, beginning with initial IoT device design and extending through business selection and implementation. Future devices will include stronger security features enabled by default, not disabled or optional. A combination of new legislation, regulatory pressures and device defaults will reinforce end-to-end IoT data encryption.
AI and IoT convergence
Some aspects of AI and IoT are merging to create a hybrid artificial intelligence of things technology that aims to combine IoT data collection with the computing power and continually evolving decision-making skills of ML and AI. AI applications for IoT will continue to grow, from predicting system failures to providing real-time support and improving autonomous operations.
Edge computing expansion
IoT data storage and processing at the edge will become more important as the number of IoT devices and data volumes places even greater pressure on network bandwidth and latency. This will continue to shift more IoT computing work from centralized infrastructures to distributed/edge computing.
Data-driven business opportunities
IoT data volumes will continue to swell and translate into new revenue opportunities for businesses, such as finding purchasing trends or optimizing supply chains. That data will increasingly drive ML and AI initiatives across many industries, from science to transportation to finance to retail.
Market maturation and simplification
The IoT marketplace will continue to grow and mature as vendors seek to offer platforms and services across the IoT stack. Market maturity will help speed the creation of new IoT deployments by removing complexity and making the design and deployment process more turnkey for businesses.
Stephen J. Bigelow, senior technology editor at TechTarget, has more than 30 years of technical writing experience in the PC and technology industry.







