Resource Description Framework (RDF)

What is RDF?
The Resource Description Framework (RDF) is a general framework for representing interconnected data on the web. RDF statements are used for describing and exchanging metadata, which enables standardized exchange of data based on relationships.
RDF is used to integrate data from multiple sources. An example of this approach is a website that displays online catalog listings from a manufacturer and links products to reviews on different websites and to merchants selling the products. The semantic web is based on the use of the RDF framework to organize information based on meanings.
RDF statements express relationships between resources, such as the following:
- documents
- physical objects
- people
- abstract concepts
- data objects
Collections of related RDF statements comprise a directed graph that maps the relationships among entities. A collection of RDF statements about related entities can be used to construct an RDF graph that shows how those entities are related.
The World Wide Web Consortium (W3C) maintains the standards for RDF, including the foundational concepts, semantics and specifications for different formats. The first syntax defined for RDF was based on the Extensible Markup Language (XML). Other syntaxes are now more commonly used, including Terse RDF Triple Language (Turtle), JavaScript Object Notation for Linked Data (JSON-LD) and N-Triples.
How does RDF work?
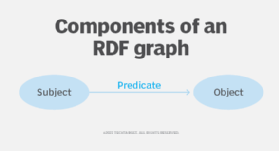
RDF is a standard way to make statements about resources. An RDF statement consists of three components, referred to as a triple:
- Subject is a resource being described by the triple.
- Predicate describes the relationship between the subject and the object.
- Object is a resource that is related to the subject.
The subject and object are nodes that represent things. The predicate is an arc, because it represents the relationship between the nodes.
The RDF standard provides for three different types of nodes:
- Uniform Resource Identifier (URI) is a standardized format for identifying a resource, whether abstract or physical. Uniform Resource Locator (URL) is a type of URI that is commonly used in RDF statements. When W3C updated the RDF specification to version 1.1 in 2014, it added Internationalized Resource Identifier (IRI) as a node type. IRIs are similar and complementary to URIs, enabling the use of international character sets.
- Literal is a specific data value and can be a string, a date or a numerical value. Literal values are expressed using the URI or IRI format.
- Blank node identifier is also known as an anonymous resource or a bnode. It represents a subject about which nothing is known other than the relationship. Blank node identifiers use special syntax to identify them.
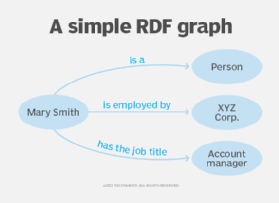
Every component -- subject, predicate and object -- of an RDF triple can be expressed as a URI or IRI. The URI can be a URL pointing to a web resource, or it can contain arbitrary data.
Multiple RDF statements about the same entity will all be RDF triples. They have the same subject, but different predicates and objects. When building an RDF graph from those triples, the subject can be displayed once, with multiple arrows branching out from the subject, representing different predicates and different objects.
How is RDF used?
RDF statements can be incorporated into Hypertext Markup Language webpages or stored in separate files and linked to data in web content. When RDF was first specified, RDF statements were incorporated into XML documents linked with web content.
Although the XML syntax was the only syntax option specified at first, standards for encoding RDF statements now include the following three syntaxes:
- Turtle is the most popular text syntax for RDF statements. The W3C describes it as a "compact and natural text form" that includes abbreviations for commonly used patterns.
- JSON-LD uses the JSON syntax for RDF statements.
- N-Triples is a subset of the Turtle syntax, designed to be a simpler text-based format for RDF statements for improved ease of use by humans writing statements. The simpler format also makes it easier for programs to create and parse RDF statements.
An RDF query language is used to access and manage information stored in RDF graphs. RDF query languages must be capable of parsing RDF triples and interpreting and producing results related to the contents of the triples, as well as the relationships among triples.
SPARQL, a recursive acronym for SPARQL Protocol and RDF Query Language, is the standard for RDF query languages that the W3C developed. SPARQL-compliant query languages operate on RDF triples only and don't support queries on RDF schemas. RDF schemas are extensions of basic RDF vocabulary that define standardized resources and relationships.
Benefits of RDF
The semantic web depends on having an open and interoperable standard for data and metadata exchange. That is what RDF provides and the reason it was first standardized. The benefits of RDF include the following:
- A consistent framework encourages the sharing of metadata about internet resources.
- RDF's standard syntaxes for describing and querying data enable software that uses metadata to work more easily.
- The standard syntax and query capability enable applications to exchange information more easily.
- Searchers get more precise results from searching based on metadata than they would from indexes derived from full-text gathering.
- Intelligent software agents have more precise data to work with and are more precise in what they deliver to users.
Unlike relational databases, RDF data can provide much more interesting information about an entity and its relationships to other entities.
Limitations of RDF
With its open specifications and wide applicability, RDF has been a successful standard for publishing semantic web data and assembling semantic information. RDF has some limitations, some of which are a result of its popularity.
The following are some of the difficulties encountered with RDF:
- Standardization of vocabulary for describing RDF resources can be difficult. The Dublin Core Metadata Initiative is an important effort to standardize RDF elements and terms for common entities and attributes.
- Choosing the most appropriate syntax format for RDF statements takes practice. Different formats may be easier to use for specific implementations, especially for the systems that generate the RDF statements.
- Choosing the most appropriate RDF query language for an application depends on the features of the query language and the specific needs of the application.
As more web content and resources are made available with metadata that encodes relationships, users have more options for getting the information they need -- and only the information they need. Find out more about how personalization engines can be used to engage and retain customers.







