
Getty Images/iStockphoto
The pros and cons of a layered architecture pattern
Layered architecture patterns provide a consistent and secure way to organize code when implemented correctly. However, the way those layers interact should remain a top concern.

When designing code structure, it's often helpful to consider how to separate responsibilities within the software stack. One way to do this is by abstracting layers of the application away from the other layers that reside above or below it -- an approach often referred to as a layered architecture pattern.
How many layers does a typical web-based application require? Learn more about how a layered architecture works, including its advantages and disadvantages, and follow these guidelines for successful implementation.
How does a layered architecture pattern work?
The design of each layer in a layered architecture aligns with specific application or business goals. As such, a clear abstraction exists between the layers and responsibilities they take custody of. For instance, an application could maintain one layer dedicated to rendering user views, another that relays responses for web APIs, and another responsible for saving data to file systems or databases.
While there's no specific limit to the number of layers involved, a typical web-based application architecture might contain four basic layers:
- Presentation layer that renders views or responses within the interface.
- Business layer that executes necessary, functional business logic.
- Data layer that handles storage for the application's internal state data.
- Persistence layer that contains objects that need to retain long-term data.
This separation provides a way to encapsulate application logic, isolate the effects of changes in a single part of the system and perform independent testing on individual application components. Developers can even inject stub implementations of adjacent layers to assess their interactions and still keep the operation isolated.
Additionally, separating presentation from the domain can help restrict the exposure of sensitive data fields to third-party or otherwise unauthorized end users. For instance, when the application renders a new user profile object, a simple development oversight could accidentally expose hashed passwords or other sensitive credentials within the domain or entity objects. However, if the presentation layer uses a unique representation for rendering responses, it's less likely that an error in the persistence layer that handles those objects would accidentally expose sensitive data to users.
Guidelines for layered architecture implementation
Development teams that pursue a layered architecture design should observe a few basic guidelines during implementation.
Give each layer a clear identity
Each layer within the architecture must provide the right balance of abstraction and operational value. Teams should identify the layer names, their purpose and the relevant entities that will reside within them as early in the architecture design process as possible. Figure 1 (below) shows a list of all the possible objects, separated by layers, in a single movie ticket booking application.

Be mindful of layer interactions
In a basic layered architecture pattern, the layers in the stack only interact with those adjacent to it. This limits the impact of a change, and it's expected that each layer maintains some degree of independent application logic related to its core function.
However, sometimes certain application operations don't need to involve certain layers. In cases like this, developers might want to make layers open, where the adjacent layers might go through the layer or skip it completely. Alternatively, closed layers always require a pass-through. The example mapping below (Figure 2) demonstrates the concept of open and closed layers in a generic architecture setup.
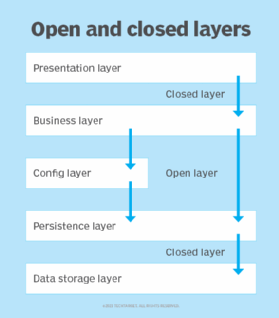
CleanArchitecture with ASP.NET Core is a popular open source project that demonstrates the use of open and closed layers in its implementation for web-based applications.
Isolate state and behavior
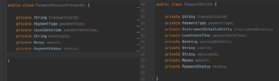
For each layer, it's important to isolate the store and process details specific to that layer. For instance, in the code example below (Figure 3), a payment presenter object (PaymentReceiptPresenter) stores the fields needed to render the UI in a persistent data store. However, the PaymentEntity object -- which also needs to reside within the persistent data store -- captures and stores sensitive account data that users shouldn't see. Separating the two into distinct classes that can respectively reside in either the presentation or persistence layer will increase data encapsulation and decrease the chance of unintentional information leaks.
Potential pitfalls in layered architecture
Several problems can emerge when using a layered architecture pattern, often related to issues that manifest during implementation. It's important to watch for these potential pitfalls to get the most out of a layered architecture.
Lack of parallel processing
A layered architecture doesn't readily lend itself to parallel processing across the various application layers. Instead, the architecture's design assumes that a request will sequentially pass through each layer to achieve its objective. If one of the layers in the workflow must manipulate an object's state, developers should put additional measures in place (such as making layers open or closed) to ensure that layer can make its own decision regarding whether to pass a request to the next layer or relay it elsewhere. The layered architectural design won't address these concerns by default.
Too many nonfunctional proxies
Some layers can act as intermediary proxies that allow requests to pass through them without performing specific operations. However, if too many layers within the workflow act as a mere pass-through, they can become an overhead without enough utility to justify the cost. Teams can address this by assessing for redundant layers that they can remove or, if appropriate, convert into open layers. Try to keep the number of layers that only act as proxies within the workflow to less than 20%.
Open or closed?
The decision to keep a layer open or closed comes down to a few basic considerations. For instance, if communication overhead or system latency is a key concern for an optional layer, it's likely a good one to keep open. If a team designs a layer to create isolated contexts, build abstractions and enforce state behaviors without exceptions, it's arguably better to keep it closed.
Difficulty at a larger scale
Layered architecture can lend plenty of readability, reliability and structure to small, cohesive units of application functionality within a codebase. However, as code volumes grow, the accumulation of features and domain concepts in each layer over time can make it increasingly difficult to draw logical boundaries between entities. Furthermore, this might introduce tight component coupling across layers, which will eventually make it difficult to pull out individual modules for updates or testing.
Development teams can deal with this issue head-on by releasing comprehensive feature packages early in the development cycle. It's also important to continually manage dependencies within the layered architecture to ensure coupling doesn't get out of control.
Priyank Gupta is a polyglot system architect who is well-versed with the craft of building distributed systems that operate at scale. He is an active open source contributor, working on projects and libraries geared toward microservices development.







