
JNT Visual - Fotolia
Evaluate AWS Glue vs. Data Pipeline for cloud-native ETL
There's more than one ETL option for AWS-hosted apps. Choose between Glue's managed service, Data Pipeline's range of supported data sources and Batch's asynchronous operations.

At some point, most applications need to move, transform or analyze data across different components or execute long-running, asynchronous jobs that perform various tasks in the systems. Cloud-native applications have services available to them for that.
Cloud-native applications can rely on extract, transform and load (ETL) services from the cloud vendor that hosts their workloads. AWS Glue, Amazon Data Pipeline and AWS Batch all deploy and manage long-running asynchronous tasks. To make a choice between these AWS ETL offerings, consider capabilities, ease of use, flexibility and cost for a particular application scenario. Use the included chart for a quick head-to-head faceoff of AWS Glue vs. Data Pipeline vs. Batch in specific areas.
AWS Glue provides a managed option
AWS Glue is a fully managed ETL service. Developers define and manage data transformation tasks in a serverless way with Glue. Its data transformation steps, known as jobs, can run on either Apache Spark or Python shell. Glue offers predefined scripts for common data transformation tasks, which simplifies the overall process to build and run a job. Developers can also bring their own scripts if they need flexibility outside of the prebuilt options. Glue's suite of machine learning algorithms can also find matches and label data.
AWS Glue keeps a Data Catalog for data stored in supported sources. Developers can maintain this catalog manually or configure crawlers to automatically detect the structure of data stored in Amazon S3, DynamoDB, Redshift, Relational Database Service (RDS) or any on-premises or public data stores that supports Java Database Connectivity (JDBC) API. When a job executes in AWS Glue, it reads data from a source defined in the Data Catalog, applies transformations to this data, and then stores the result in either S3 or a JDBC-supported database.
AWS Glue's management capabilities extend into basic workflow orchestration, where users define triggers and tasks. For more complex data transformation workflows, Glue users can rely on its built-in integration with AWS Step Functions, which coordinates serverless workflows across multiple AWS technologies.
AWS Data Pipeline on EC2 instances
AWS users should compare AWS Glue vs. Data Pipeline as they sort out how to best meet their ETL needs. AWS Data Pipeline is another way to move and transform data across various components within the cloud platform. Like Glue, Data Pipeline natively integrates with S3, DynamoDB, RDS and Redshift. Developers can configure Data Pipeline jobs to access data stored in Amazon Elastic File System or on premises as well.
Data Pipeline offers prebuilt templates to do common tasks. Use these templates to simplify ETL operations, such as copying data from RDS into S3, or from DynamoDB to Redshift. Data Pipeline also supports the execution of shell commands for custom operations.
Developers can define more complex workflows within Data Pipeline versus in Glue; however, Glue's integration with Step Functions gives developers a high degree of flexibility in terms of how they orchestrate complex workflows and set up triggers and conditions that involve other native services and custom logic.
A key difference between AWS Glue vs. Data Pipeline is that developers must rely on EC2 instances to execute tasks in a Data Pipeline job, which is not a requirement with Glue. AWS Data Pipeline manages the lifecycle of these EC2 instances, launching and terminating them when a job operation is complete. Jobs can launch on a schedule, manually or automatically using the AWS API. Data Pipeline also integrates with the Amazon Elastic MapReduce (EMR) big data platform, and it can launch clusters to process data as part of a pipeline step. Additionally, users can configure on-premises hardware to run Java-based Data Pipeline tasks.
The integration between Data Pipeline and EMR also gives developers the option to use a range of big data platforms supported in EMR, such as Spark, Hadoop, HBase, Hive and Presto.
AWS Batch beyond ETL
AWS Batch, like Data Pipeline and Glue, manages the execution and compute resources of asynchronous tasks, and developers can use Batch to transform data. But AWS Batch is not limited to transforming and moving data across application components. It also suits scenarios that require heavy computational tasks or the execution of asynchronous operations in general.
AWS Batch is optimized for application workflows that must run a large number of batch jobs in parallel. The service also supports job scheduling and preconditions where a particular job execution is dependent on other jobs' completion. Like AWS Glue, Batch easily integrates with Step Functions for flexible job orchestration flows.
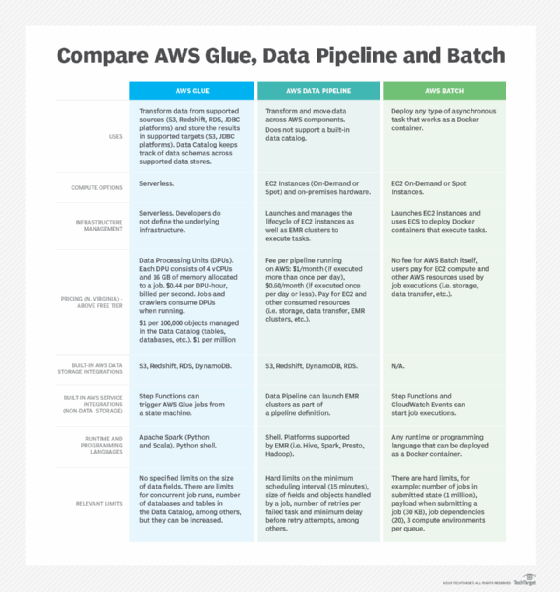
AWS Batch jobs are defined as Docker containers, which differentiates the service from Glue and Data Pipeline. Containers offer flexible options for runtimes and programming languages. Developers can define all application code inside a Docker container, or define commands to execute when the job starts.
AWS Batch manages the EC2 compute infrastructure required to run jobs; it uses Amazon Elastic Container Service (ECS) to deploy Docker containers.
Dig Deeper on AWS cloud development
-
![]()
AWS Machine Learning Certification Exam Dumps and Braindumps
By: Cameron McKenzie
-
![]()
Sample Questions for AWS' Machine Learning Associate Certification
By: Cameron McKenzie
-
![]()
AWS Machine Learning Associate Practice Exams
By: Cameron McKenzie
-
![]()
Certified AWS Data Engineer Exam Dumps and Braindumps
By: Cameron McKenzie



