Rapid growth is a blessing and a curse for any application. It provides both increased revenue and increased technical challenges. To mitigate these challenges, developers should consider cloud design patterns.
Design patterns that govern cloud-based applications aren't always discussed until companies reach a certain scale. While there are countless design patterns to choose from, one of the biggest challenges is dealing with scale when it becomes necessary. To better scale workloads, several design patterns can make any cloud-based application more fault-tolerant and resistant to problems from increased traffic.
Review these five cloud design patterns to help developers better handle unexpected increases in throughput:
Bulkhead.
Retry.
Circuit breaker.
Queue-based load leveling (QBLL).
Throttling.
Also, learn about various best practices to build resilient applications.
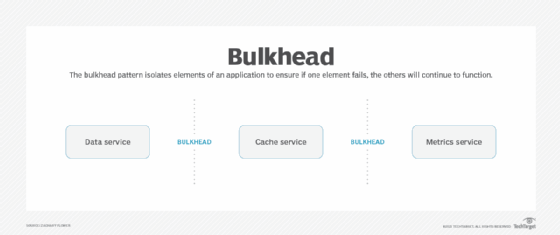
1. Bulkhead
Named after the partitions of a ship that help isolate flooding, the bulkhead pattern prevents a single failure within an application from cascading into a total failure. While implementing this pattern isn't always obvious, it is typically found in applications that can operate under degraded performance.
An application that implements the bulkhead pattern is built with resiliency in mind. While not all operations are possible when email or caching layers go down, the application can still function with enough foresight and communication to the end user.
The bulkhead pattern ensures application functionality by isolating different parts of the app.
With isolated application sections that can operate independently of one another, subsystem failures can safely reduce the application's overall functionality without shutting everything down. A good example of the bulkhead pattern in action is any application that can operate in offline mode. While most cloud-based applications require an external API to reach their full potential, fault-tolerant clients can operate without the cloud by relying on cached resources and other workarounds to ensure the client is marginally usable.
2. Retry
In many applications, failure is a final state. However, in more resilient services, a failed request can potentially be resent.
The retry pattern, a common cloud design pattern for third-party interactions, encourages applications to expect failures. Processes that implement the retry pattern create fault-tolerant systems that require minimal long-term maintenance. These processes are implemented with the ability to retry failed operations safely.
The retry pattern enables failed requests to be resent a limited number of times to encourage success.
The retry pattern is often seen in webhook implementations. When one service tries to send a webhook to another service, that request can do one of two things:
Succeed. If it succeeds, then the operation is completed.
Fail. If it fails, the sending service can resend the webhook a limited number of times until the request is successful. To avoid overloading the target system, many webhook implementations use exponential backoff, increasing time delays between each request to give a faulty destination time to recover before failing. These delays often introduce some randomness in the timing -- called jitter -- to prevent synchronized retries from further overwhelming the system.
The retry pattern only works when both the sender and receiver know that failed requests can be resent. In the webhook example, a unique identifier for each webhook is often provided. The receiver can then validate that a request is never processed more than once. This avoids duplicates, while enabling the sender to experience its own errors that could erroneously resend redundant data.
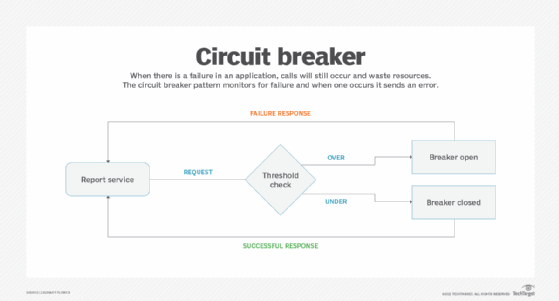
3. Circuit breaker
Dealing with scale can be an incredibly nuanced problem in cloud-based applications, especially with processes with unpredictable performance. The circuit breaker pattern prevents processes from "running away" by cutting them short before they consume more resources than necessary.
The circuit breaker pattern can halt any request that takes too long to generate.
Imagine a webpage that generates a report from several different data sources. In a typical scenario, this operation might take only a few seconds. However, querying the back end might take much longer in rare circumstances, which ties up valuable resources. A circuit breaker could halt the execution of any report that takes more than 10 seconds to generate, which prevents long-running queries from monopolizing application resources.
More modern implementations can take this further by pairing failure thresholds with dynamic recovery times, enabling more resiliency in systems with unpredictable resource constraints, such as serverless environments.
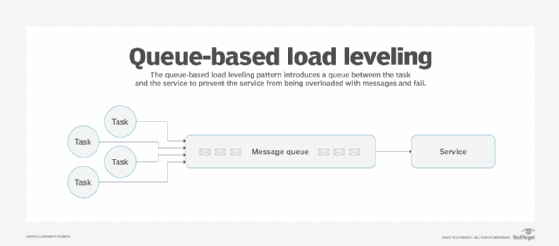
4. Queue-based load leveling
QBLL is a common cloud design pattern that uses queues to execute requests. Rather than performing several complex operations at request time -- which adds latency to user-exposed functionality -- these operations enter a queue. This queue executes fewer requests within a given time period. This design pattern is valuable in systems where many operations do not need to show immediate results, such as sending emails or calculating aggregate values.
The queue-based load leveling pattern organizes requests into a queue to manage execution.
Consider an API endpoint that must make retroactive changes to a large data set whenever it is executed. While this endpoint was built with a certain threshold of traffic in mind, a large burst in requests or rapid growth in users could negatively affect the application's latency. By offloading this functionality to a QBLL system, the application infrastructure can more easily withstand the increased throughput by processing a fixed number of operations at a time.
5. Throttling
An alternative design pattern to QBLL is the throttling pattern, which functions in relation to the noisy neighbor problem. While the QBLL pattern offloads excess workloads to a queue for more manageable processing, the throttling pattern sets and forces limits on how frequently a single client can use a service or endpoint to keep one noisy neighbor from negatively impacting the system for everyone. The throttling pattern can also supplement the QBLL pattern. This enables the managed processing of excess workloads and ensures the queue depth doesn't become full.
The throttling pattern enforces limits on how many times a client uses a service or endpoint.
Looking back at the QBLL example, imagine the API endpoint could originally handle about 100 requests per minute before the heavy work was offloaded to a queue. An API can support a maximum throughput of about 10,000 requests per minute. That is a huge jump from 100, but the queue can only support 100 requests per minute without any noticeable impact on the end user. This means that 1,000 API requests could take 10 minutes to process, and 10,000 API requests could take two hours.
In a system with evenly distributed requests, every user experiences slower processing equally. But, if a single user sends all 10,000 requests, all other users experience a two-hour delay before their workloads start. A throttling schema that limits all users to 1,000 requests per second ensures that no single user could monopolize application resources at the expense of any other user.
Best practices for resilient applications
Building resilient applications isn't just about the patterns. It's also about how developers think about application development and their approach to risk management, architecture and application design. The following are just a few best practices that can help take the above patterns and successfully apply them in business systems.
When it comes to technology, failure is never a matter of 'if,' but 'when.'
Plan for failure
When it comes to technology, failure is never a matter of "if," but "when."
A key component of designing resilient applications is to start with the assumption that every component eventually fails. This perspective creates a plan of action by identifying areas where an application might be fragile or otherwise vulnerable to scale issues.
Don't stop at just a plan for failure. Cause failures with a technique called chaos engineering. Chaos engineering is the process of intentionally introducing faults, errors and other failures into a running system to better understand the tolerances of that system. Popularized by Netflix, this is a common discipline that tests the resilience of a system and helps users better understand how they should improve it.
Decouple and isolate services
There's a common software development pattern called separation of concerns. This pattern involves organizing a codebase into distinct components, each with a focus area of expertise. This loose coupling enables developers to build more scalable and maintainable systems. Since the individual concern of each component is tended to, the likelihood that a failure in one results in a failure of the overall application reduces.
While the bulkhead pattern accomplishes this at the infrastructure level, it is important to consider other, more advanced techniques when scaling. Event-driven architecture, database sharding and workload partitioning can contain failures and increase a system's overall stability.
Automate recovery
Recovery is the act of returning a failed system to a healthy state. However, recovery can be time-consuming and drain resources and energy. Building a resilient application requires a culture of constant improvement, prioritizing the resolution of failures and automating recovery for the future.
In any system, every known failure state has a corresponding recovery method. This could require scaling resources up, killing runaway processes or redirecting traffic. Once developers have identified their failure states and resolution procedures, they can start to identify the conditions that lead to those failure states through intelligent health checks and other monitoring techniques. This enables developers to build a comprehensive system that can recover from a failure before it even happens.
Offload resiliency
While some of these design patterns can seem complicated, they don't all need to be built from scratch. Sometimes, it's worth it to offload some resiliency to a third party with more experience and expertise, such as an API gateway, load balancer or application cache. Many cloud provider services and features can reduce overhead and complexity, while increasing an application's stability and resiliency.
A common pattern implemented here is the ambassador pattern. This involves using an ambassador -- like an API gateway -- to act as a proxy between the application code or clients and the services the application depends on. In this pattern, the ambassador handles the circuit breaking and retry logic, enabling developers to focus their efforts on business logic.
Think cattle, not pets
In DevOps, the phrase "cattle, not pets" means that infrastructure should be built so that each service and component is interchangeable rather than being treated as irreplaceable. Put another way, don't care for infrastructure when it gets in a bad state; just raise a new resource.
This is called immutable infrastructure, which emphasizes replacing application instances and other services instead of patching them. While managing infrastructure in this way can ensure that nothing is ever stale, it has the added benefit of enabling more advanced deployment techniques, like blue-green and canary releases. These can help avoid downtime and make the release process far more stable.
True resiliency means considering the physical location of your infrastructure and planning accordingly.
Build for real-world resilience
In layman's terms, the cloud is a bunch of computers that exist somewhere in the world. No amount of chaos engineering and QBLL can save an application from an asteroid crash-landing into a data center in Palo Alto. True resiliency means considering the physical location of your infrastructure and planning accordingly.
Deploying across multiple regions or availability zones can help safely fail over in the event a business's primary data center is out of commission. Devs that want to cover their bases should adopt a multi-cloud strategy to weather the loss of not just a regional data center, but an entire cloud provider.
The 6-month rule
It can be incredibly difficult to scale a cloud-based application. Often, IT teams must choose between implementing a design pattern that can support application growth for another six months or a design pattern that can support application growth for another six years.
In my experience, options that fall under the six-month timeline are the most cost-effective. Spend a few weeks to buy in for six months to support the business's and users' needs. It's more effective than spending a year building a more extensive system that is harder to change.
A midterm focus is not the same as shortsighted hacks and Band-Aids. The careful implementation of common design patterns can support an application's long-term maintenance, while also being flexible enough to adapt as circumstances change.
Editor's note: This article was updated to reflect changes in the best practices for cloud design patterns.
Zachary Flower, a freelance web developer, writer and polymath, strives to build products with end user and business goals in mind and an eye toward simplicity and usability.
Dig Deeper on Cloud app development and management