Getty Images/iStockphoto
10 best practices for managing data in microservices
Data architects managing loosely coupled microservices applications need to make the right decisions about databases, data ownership, sharing, consistency and failure recovery.

While microservices offer many benefits for developers and application owners, they don't do the data architect many favors.
With the inherent independence and loose coupling of microservices-based applications, data and data management can become a tangled web quickly. Where monolithic applications have similarly monolithic databases, microservices applications have microdatabases for each service accessing data.
Each service owns its data, but data might need to travel between services for an application to function. While only one service can change its microdatabase, some services might need to know the state of that data. Data design for a microservices application must account for consistency needs, multiple types of databases, chatty network communication, failure and recovery mechanisms, and more.
What is a microservices architecture?
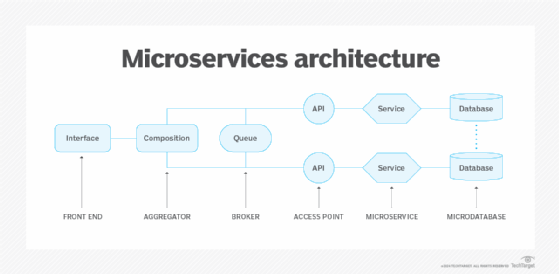
A microservices architecture separates application tasks and functions into independent, limited-scope services that interact but can scale and act independently. This separation is also referred to as application decomposition. Some application architectures are 100% microservices, while others are a mix of microservices and monolithic codebases.
Application architects choose microservices designs for many reasons, such as to scale some application components with demand and to give developers control over code in different parts of the application. At the database layer, microdatabases arrange the application's data as a collection of loosely coupled schemas. Data designers must develop and deploy separate physical or logical databases to support microservices architecture independence.
Microservices data design best practices
There is no single correct way to manage data in a microservices architecture. In fact, management techniques can vary by service within the same application. The following 10 recommendations are not exhaustive but provide a starting point for a microservices data design that is performant and manageable. They cover key areas, including data ownership, service interaction and sharing, data propagation and consistency, and database design.
1. Assign data ownership
Each service is responsible for its own private database. That microdatabase's schema is only relevant to its owning service. Changes to the microdatabase schema happen in isolation from other services. This isolation eliminates design-time coupling. Without proper data ownership boundaries, it's a data monolith.
Each database is only directly accessible by its owning service. This service -- and only this service -- can read and write to its database. But microservices do not operate in a vacuum. When another service needs access to a service's data, it goes through the owning service.
2. Establish data-sensitive service boundaries
Architects must decompose an application's functional boundaries with data consistency in mind. Services need to share data from their owned databases.
Data in a single monolithic data store is consistent. With data distributed across multiple private databases, data can become inconsistent. Application designers should not rely on synchronous distributed transactions, such as two-phase commit, in a design with independent distributed services. Fundamentally, microservices are self-contained, independent and autonomous. Synchronous transactions across services violate the concept by introducing dependency. This leaves the data architect to develop their own data consistency systems.
3. Limit strict consistency
Confine strong consistency to within a service boundary. Strict consistency means every read request returns the most up-to-date value from the database. Consistency is only guaranteed within a service boundary. A single microdatabase should represent the system of record for an entity. The service tied to that database requires consistent data from it. If you find that a service requires consistent data from another service's database, you need to redraw service boundaries.
4. Accept eventual consistency
Propagation of data across services occurs as asynchronous communication. Eventual consistency means, once data is updated in the owning database, its updated value is, at some point, reflected in the other services' databases. The services that do not own that data must, therefore, tolerate temporarily stale or inconsistent values for the data. Application and data architects must work out the data consistency requirements between services. These often vary within an application.
5. Restrict data sharing in transactional workflows
In transactional workflows, restrict data sharing to only what receiving services need. A nonowning service might need to store a subset of information about a domain entity -- not all its information.
Designers have multiple ways to set up transaction workflows in an application. For example, the customer service and order service interact to complete a transaction. The customer service in the application could share customer entity data, such as contact information, with the order service. However, the application could simply pass a reference, such as a customer identifier for the specific customer entity involved, between the services. This customer reference is stored with the order for referential integrity. All other customer data remains in the customer service.
6. Optimize cross-service queries
Certain tasks in an application require information from multiple sources. Queries can span services and, therefore, databases. Since each service handles its own database, such a query could trigger a lot of service-to-service communication to gather the required information. For example, designers could set up a chain of responsibility pattern where each service messages the other involved until the responses are compiled in one output. Several approaches avoid unnecessary service-to-service communication, in varying degrees addressing independence, scalability and performance:
- Local data. Services store all needed data locally. All nonowned data acts as a read-only cache.
- Specialized service. The application design includes a reporting/analytics service and database. It integrates and optimizes the data from the owning services for querying.
- Data composition. Set the application up to aggregate distributed data on the fly. Data composition joins and filters individual service database queries. A service, API gateway or API query language aggregates the queries to generate this multidatabase query result without creating a chatty front end.
7. Design for failure
Distributed application architectures do not inherently enforce data consistency. And a single logical transaction can span services and their associated databases. Therefore, the transaction gets divided into a series of sequential multiservice local transactions coordinated by orchestration or choreography. The application designer must create fault tolerance in each step of the workflow.
When the application detects an error, it reacts to the failure by initiating an error recovery strategy. Recovery from errors typically includes a retry mechanism, where the task attempts to run again and finish successfully. Another option is to back out via compensating transactions. This recovery method reverses the effects of a preceding failed operation by undoing the effects of each step, returning affected databases to the prior consistent state. In some situations, the application can rely on periodic reconciliation to confirm integrity in the transactions.
8. Adopt event-driven architecture
An asynchronous messaging pattern must explicitly accommodate data latency and time sensitivity between services.
Use event- or stream-driven architecture to propagate data updates across services. In an event-driven architecture, the services that own the data distribute it by publishing that data as events. Nonowning services, interested in the data, subscribe to the events.
Any implementation of data consistency brokered via a queue between services needs to ensure order, durability and guaranteed delivery.
9. Logically separate databases
In a loosely coupled microservices architecture, the services can share a physical data store but not a common data schema. If multiple services share a data store, each service must have logical schema separation. The service controls its own tables, documents, objects and other components, establishing a virtual private data store. Another option is to have multiple physical data stores, which are logically separate by default.
10. Use separate physical data stores
When each microservice has its own physical data store, each service can use the data store technology best suited to it. This is referred to as polyglot persistence. Each data store is optimized for the data types, read/write patterns and functions of the service.
For complete independence from runtime coupling, a data architect favors a separate data store for each service. However, the benefits of isolation come with increased management complexity. A given microservices-based application could use many data stores. The architect should weigh the pros and cons of this decision from a data infrastructure perspective more than a microservices architecture perspective.
Jeff McCormick is an enterprise data architecture director and IT principal who has extensive experience in data-related IT roles. He is also an inventor, patent holder, freelance writer and industry presenter.