
carloscastilla - Fotolia
Implement and manage an event-driven microservices architecture
Learn the basics of event-driven architecture as they apply to microservices, with the help of real-world examples and three main architecture patterns.

To meet business needs, applications must reach new heights of scalability, resilience and 24/7 operation with near-perfect uptime. Technologies like event hubs, cloud computing and microservices emerged because existing architectures couldn't meet such demands and challenges.
Event-driven microservices can replace applications with a monolithic architecture, creating systems that are more flexible, scalable and easier to maintain. The event-driven architecture in microservices offers several advantages over legacy systems, but application designers and developers must learn how to approach microservices communication, maintainability and scalability within these event-driven methods. Additionally, teams should decide on an architectural pattern that best fits the application's tasks: event sourcing, polyglot persistence or command query responsibility segregation (CQRS).
Benefits of event-driven architecture
In an event-driven architecture, the domain events are the first-class citizens. Event-driven architectures -- commonly seen in microservices and serverless projects -- underpin systems that are reliable, loosely coupled, scalable and have high availability.
Modern microservices architectures are event-driven and reactive. If one component in an event-driven architecture goes down, the other components can continue to function as usual, whereas, in a typical monolithic application, failure of one component might bring the other components down as well.
Companies such as LinkedIn and Netflix use an event-driven, asynchronous messaging architecture.
Data management for microservices
When organizations adopt event-driven microservices, they should expect many changes from legacy application designs, particularly with data.
A monolithic application architecture typically contains a single database. On the contrary, data access in a microservices architecture is much more complex. Each microservice typically owns its data, which implies that the data is private to the microservice. When a service wants to access the data owned by another service, it must call for access to that service's exposed API. Furthermore, the way that an API encapsulates data makes it easier for developers to build loosely coupled microservices, as well as independently manage, maintain and change them as needed.
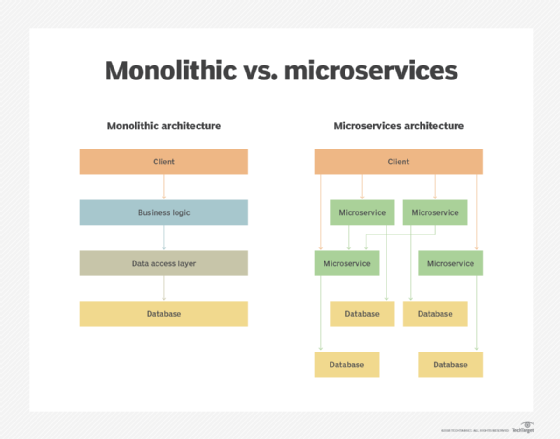
When multiple services access the same piece of data, things become complicated. To make things even harder, you might have microservices that use different types of databases. One example includes microservices that have a mix of SQL and NoSQL databases -- commonly known as polyglot persistence.
While polyglot persistence has benefits aplenty -- such as loosely coupled services and better performance and scalability -- it introduces major distributed data management challenges. For example, how will business transactions span multiple services and ensure data consistency? A typical monolithic application might take advantage of atomicity, consistency, isolation and durability -- known by the acronym ACID -- transactions to maintain consistency. However, these types of transactions don't fit naturally into a microservices application.
Communication among event-driven microservices
In a typical event-driven architecture, several microservices need to communicate with each other asynchronously. These services should be scalable, decoupled from each other and individually maintained. Additionally, the microservices should produce events that other services can consume.
In an event-driven microservices architecture, a microservice publishes an event when a given activity occurs, like a status update of an order. Once a service receives an event, it updates its data. Then, the other microservices subscribe to those events. This design can help implement business transactions that span multiple services. Consider two services -- namely, the Order Service and the Customer Service -- that must communicate to process orders. The Order Service owns the Order Table, and the Customer Service owns the Customer Table. When the Order Service creates an order with the status as "New" and publishes an "Order Created" event, the Customer Service consumes this event, reserves credit and then publishes a "Credit Reserved" event. Next, the Order Service consumes this "Credit Reserved" event and sets the Order Status to "Open."
Event-driven microservices also help developers build responsive applications. Consider a service named Confirmation that notifies users once their order is received and placed in the queue. Multiple users access the order processing application at the same time, which causes it to queue all the notifications before sending them to the respective users. In this case, a user need not wait while the order processes. This architecture produces a responsive, loosely coupled application.
Event-driven microservices architecture patterns
Patterns to build microservices in the event-driven style include event sourcing, polyglot persistence and CQRS.
Event sourcing is a commonly used architectural pattern for migration from a monolith to microservices. In the event sourcing pattern, a sequence of events determines the state of the application. This pattern uses an append-only event stream, such as Apache Kafka or RabbitMQ. Events are delivered in the same order they are received, like a queue.
In polyglot persistence patterns, data stores are selected depending on the characteristics of the data types. Microservices architectures can store data as a separate service and in several formats. For example, an online e-commerce application needs a full-text search feature. The database used by this search engine is a document database -- MongoDB -- because it facilitates fast searches. But the e-commerce application uses a relational database to track transactions. So, the search engine and its database should coexist alongside the other relational database, or databases, the e-commerce application uses to enable polyglot persistence.
CQRS isolates the read model from the write model. This architectural pattern works with different models to read and update domain data. In the CQRS design pattern, there's typically a separate service, model and database for the insert or update operations, as well as for data querying.





