
Getty Images/iStockphoto
3 common CQRS pattern problems, and how teams can avoid them
While CQRS can provide a lot of value when it comes to structuring an event-driven architecture, improper practices can cause this pattern to be more of a burden than a blessing.

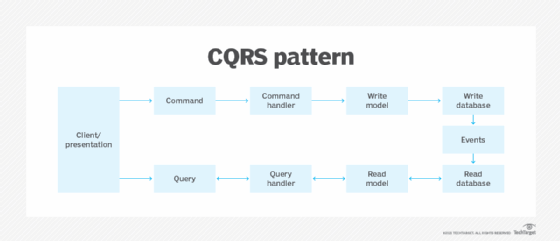
At the surface, the practice of separating the command elements from query elements seems straightforward: Simply separate the models used to update information from the models used for read operations, including the data stores they rely on. In this case, the data stores that handle writes might resemble a log of transactions, while the data store for reads is likely a traditional database that models product orders or customer account information.
In practice, implementing this type of separation often requires the support of an event-driven architecture, where commands are relayed to a service bus that proceeds to initiate the two independent data store updates. But while this approach -- commonly referred to as command query responsibility segregation (CQRS) -- makes sense in online e-commerce, social media and other application scenarios where it's possible to combine persistent data stores with events, it doesn't come without certain management risks.
In this article, we'll run through a quick review of what a typical CQRS pattern entails, cover the risks a careless approach to this pattern imposes and review some of the essential guidelines for successful implementation.
The inherent risks of CQRS
Like many event-based patterns and mechanisms, CQRS adds news levels of complexity within an underlying codebase. For instance, a typical implementation will inevitably employ the following four elements:
- a webpage or mobile interface that calls an API;
- a message broker that publishes the API call as an event;
- back-end services that subscribe to those events and update data stores; and
- a domain model entity for data reads that processes the updated information.
While the sophisticated nature of a CQRS implementation allows programmers to implement sophisticated application functions and features with only a few lines of custom code, that nature is what also makes it a challenge to navigate.
Delayed data synchronization
The need to coordinate all the separate components listed above -- especially in a distributed architecture that values decoupling -- creates the first big risk with CQRS: a loss of data synchronization. Patterns like CQRS that often rely on publish/subscribe models are subject to delays in updates and race conditions because the client must wait for updated event data.
To imagine this from a user perspective, consider a web-based retail application that provides customers a viewable list of their unique order history. After placing an order, it may take anywhere from several seconds to a few minutes for that transaction to show up in a customer's order history screen, meanwhile requiring the customer to refresh the page until the new order appears. Eventually, the event will process, and the customer can refresh the order history page to see the updated information on their screen -- but not without the risk that customers get frustrated or confused over the delay.
Developers have tried to mitigate the inherent data synchronization delay in CQRS, such as reworking the read/write process or updating the data models directly. A common response to this is to use a write through cache -- typically a NoSQL model -- to read data. However, doing that mixes the commands and the reads, which is the exact scenario that CQRS was designed to eliminate.
Write-based performance issues
In order to deal with the above-mentioned data synchronization issue, a clever person might configure some way to query the transaction log directly, perhaps to create a report for a particular customer or to track down an error. Other programmers might even try to update the data models directly in attempt to resolve production-level breaks and errors. However, if the core of the issue isn't properly addressed, this perceived fix might become a weekly code cleanup chore. Eventually, teams will end up in a repetitive process of reading from the transaction log and writing to the data model directly.
If the transaction logs and write processes ever go out of sync, data stores may likely encounter critical timing and lockout issues, similar to the classic problem of using an operational data store as a data warehouse. Furthermore, the delays in new writes may cause increasingly severe performance problems for end users.
Incompatibility with legacy systems
Finally, one of the biggest challenges imposed by a CQRS implementation is finding a way for the new code to work with unmovable legacy components. Because it is commonly associated with a move to microservices, a CQRS implementation could be part of an overall legacy system migration. However, this will often still require a rewrite, possibly for each table the existing system interacts with, in order to introduce an event-sourcing model.
It's still possible to switch directly from a database-centric command approach (e.g., "insert a comment into comment_table") to a workflow-based approach (e.g., "add comment") that aligns business logic with event-driven application logic. But, while this might not immediately seem like a significant modification to the process, teams that remain beholden to directly manipulating database models or tying reads and writes together into one execution typically won't add much to their software besides undesirable levels of code complexity.
Tips to get started with a CQRS implementation
To be successful, a CQRS implementation needs to mitigate the problem of delayed results and enforce strong rules that bar improper use. To get the most value, development teams should enforce a task-based project workflow based on defined business goals and domains, as this will help significantly when it comes to navigating debugging processes while simultaneously maintaining dynamic levels of traffic.
Instead of coding new base classes to build your own customized implementation of CQRS, it's typically better to use one of the existing frameworks for CQRS available through both open source and proprietary channels. These prebuilt frameworks are typically designed to complement certain languages, such as Python, C# or Java.
Using one of these existing CQRS frameworks can help significantly shorten the implementation schedule, prevent bugs in base elements of the architecture and allow programmers access to community-based support. However, even with these existing frameworks, it's best to get some upfront experience before attempting a big conversion like this. Start by implementing CQRS on a small set of relatively new applications or data sets, looking particularly for places where the classic Create, Read, Update and Delete (CRUD) cycle model isn't cutting it.
Team structure matters in CQRS
Conway's Law states that an organization's overall software architecture typically reflects the existing team structure of the organization, including how those teams communicate. This law is more observation than science, but there are still plenty of examples to back up the belief. Companies that have one team for both front-end and back-end development, for instance, will likely produce software with tighter component coupling than those that assign separate teams for each. While that's not inherently a bad thing, that team structure may likely stand in the way of any eventual effort to decouple the front and back end.
In CQRS, team structure matters because the pattern separates writes from actual data processing. This separation often creates two different kinds of specialists: those who manage the procedural commands and those who work exclusively with the data model. Changes to the model -- for example, adding the ability to store multiple credit cards -- will require coordination between these two teams.
To help ensure that collaboration happens, it helps to introduce a process that keeps implicit database schemas in sync. Creating an entire change control board is likely too heavy-handed an approach, but maintaining a published schedule of application changes and assigning a steward role responsible for monitoring those changes could help keep things in line. Remember to also monitor all levels of testing, including unit, API, functional and system tests while maintaining a focus on metrics for performance, workload levels and user experience.
Author's note: Matthew Groves (@mgroves) and Steve Poling (@stevepoling) assisted with readability for tough sentences for this article and review.







