CQRS (command query responsibility segregation)
What is CQRS (command query responsibility segregation)?
CQRS (command query responsibility segregation) is a programming design and architectural pattern that treats retrieving data and changing data differently. CQRS uses command handlers to simplify the query process and hide complex, multisystem changes.
When the CQRS pattern is combined with the event sourcing pattern, it guarantees an audit log of changes to the database that can help maintain transactional consistency. Moreover, its read model can contain, or be used to generate, a materialized view pattern of write model data.
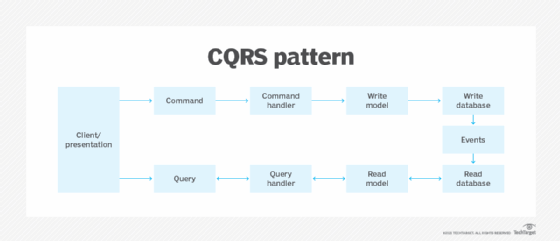
CQRS is a software architecture pattern in which the responsibilities of a system's commands and queries are segregated by vertically slicing the application logic. You can think of the pattern as a way to separate read and update operations for a data store. The goal of CQRS is maximizing application performance, security and scalability.
In CQRS, a command conveys the user's intent. It is an instruction the user provides to the system to perform a certain task. A command does not generate a result and is part of the write model. A query is a user's request for information. It returns a result but does not change the state and is part of the read model.
Greg Young developed the CQRS design pattern in 2010, around the same time as event sourcing emerged. As he defined the pattern: "[CQRS] uses the same definition of commands and queries that Meyer used and maintains the viewpoint that they should be pure. The fundamental difference is that, in CQRS, objects are split into two objects, one containing the commands, one containing the queries." Young was referring to Bertrand Meyer, who developed CQRS' predecessor, the command query separation (CQS) pattern.
CQRS vs. CQS
Although related to and inspired by CQS, CQRS is different in that objects are split into two objects: one containing commands and one containing queries. Separate model representations for queries and commands make the approach highly suitable for event sourcing or task-based user interface (UI) applications. In contrast, the CQS application architecture pattern is mainly about separating the logic for queries that don't update a system's observable state from the logic of commands that do perform state updates.
Bertrand Meyer first referred to CQS in his book, Object-Oriented Software Construction. It is also part of his work on the Eiffel programming language. He proposed separating methods that change state from those that don't. This enables queries to be confidently used in many situations. They can also be introduced anywhere, and their order can be changed as needed.
Learn more about the most popular programming languages in the world.
When to use the CQRS pattern -- and when not to
The CQRS pattern is useful in all these scenarios:
- Collaborative domains. Numerous users can view the same data concurrently.
- Task-based UIs. Users are led through a series of steps to finish a task.
- High-traffic systems. Evenly distributing the workload between read/write operations improves performance and scalability in high-traffic systems.
- Querying from repositories. Query the data users need to view from repositories.
- Complex business logic. Separating read/write processes can help streamline application design if it contains complicated business logic.
- Optimizing read operations. CQRS can create dedicated read models to optimize the read operations, especially if an application has many such operations.
- Different data models for reads/writes. Through CQRS, multiple data models can be established for each operation by separating the read/write models.
- Support for event sourcing. CQRS can be combined with event sourcing patterns to develop a system that can handle many events and queries.
It's important to consider CQRS' unique requirements and limitations and assess thoroughly whether this pattern is appropriate for its particular use cases. Use it only in restricted situations where it's necessary. It's useless for systems that follow the create, read, update and delete mental model.
How the CQRS pattern is executed
The most common way to deploy CQRS is the command pattern, which is the software system that defines a high-level interface. At runtime, the base class takes the command, creates the appropriate object handler -- perhaps update, delete or create -- and calls a method to execute the command.
Before and after execution, the base class can log that the method was called. The log can be replayed from and to any point in time. Once the interface and dispatch code exist, the computer program to take the events and replay them is called a for loop. It reads a file from a certain point, and then, for each line, it calls the command on that line with the data on that line. The complexity hidden inside the command handler is limited or encapsulated by the handler.
The handlers call each step of the process to create, update or delete a logical item in the system. They can dispatch the first request and monitor to see when that action completes, handling errors and rollbacks if needed. The handler sets up a long-running, two-phase commit (saga pattern) post in which it writes the results to the event log. This log contains a record of every system change. If this log is created in a consistent way that a program can read and replay, it enables event sourcing.
CQRS example: Customer order process
When a customer looks at an order, a straightforward process is executed: a read from a database. The read could be from a NoSQL key-value store, like Redis, that stores all customer information. A microservice picks up the information, and a webpage displays it. The Redis team, working with the front-end developers, can handle the read side easily.
The operation's write side is much more complex and contains several different steps and dependencies. For example, if an order is canceled before it is shipped, the following occurs:
- The return must be canceled in the cache and returned in the main source system of record.
- If there is a data warehouse, the record must be deleted from it and other auxiliary systems.
- The physical warehouse and shipping must be notified to not ship the item.
- Credit card charges must be reversed, inventory counts in the warehouse must be changed and the supplier's refill order must go down by one.
Since a single change (order cancellation) must be copied to so many places, the update, delete and create sides of the operation must interact with either an enterprise service bus (ESB)or a command handler, such as the saga pattern. CQRS helps create the logic to handle these complex transactions.
Challenges of CQRS
Some challenges associated with CQRS are the following:
- Complexity. CQRS creates complexity on top of the codebase. Instead of a simple relational database, like a Structured Query Language database, the application now has command handlers, dispatching and logging, all of which increase the potential for error.
- Messaging. CQRS doesn't require messaging, but it's typical to use messaging to process commands and broadcast update events, with the application having to handle message failures or duplicate messages.
- Conversion. It can be challenging to convert to CQRS currently online running noncomplex systems like those that don't have a complex transition log or systems that use overnight batch mode to do updates.
- Eventual consistency. Separating the read/write databases can cause the read data to become stale. Updating the former to reflect changes in the latter can cause data consistency issues. It can be difficult to detect when a user issued a request based on outdated data from the reading database.
- Delayed data synchronization. Changes made in the write mode can take some time to reflect in the read mode, which can cause issues if a user queries the read mode before change synchronization.
- Cost. CQRS patterns can increase hardware costs. Cloud utilization costs can also increase since additional database technologies are required for deployment.
Combining CQRS with other patterns: CQRS and event sourcing
The CQRS pattern is frequently used with the event sourcing pattern. The latter is an approach to a series or sequence of events. Events are user-generated actions, such as clicking a mouse button or pressing a keyboard key. CQRS-based systems use separate read/write data models, where each model is tailored to relevant tasks and often located in physically separate data stores.
In CQRS, the system tracks past changes in data states and alerts users on how to handle them. Every step of the data transformation process is recorded, not just the most recent state. Since the system itself can be recreated as the collection of all the changes over time, it creates a new view of data in the system: the transaction log. This log is not just a text file, but an actual set of commands that can be replayed to recreate the change. In some cases, the event log can be "played backward" to undo large changes.
Setting up event sourcing requires capturing the changes, along with building the software to replay those changes. Deployed carefully, command handlers can write to a log, creating the transaction log for event sourcing. Running each line in the log through a command handler executes event sourcing.
The CQRS and event sourcing patterns have considerable overlap. The command in CQRS is one way to create event sourcing. CQRS works well with event sourcing since it divides the system by business operations and events are the result of those operations.
What are some related patterns?
CQRS is compatible with domain-driven design -- an explicit domain model -- event sourcing and the command pattern. An ESB might deliver the messages to perform the create, update and delete. The general pattern is service-oriented architecture.
While CQRS can be useful in constructing an event-driven architecture, bad practices can turn it into more of a nuisance. Explore common CQRS pattern problems, and see how they can be mitigated.







