singkham - Fotolia
A guide to GPU implementation and activation
Data center GPU usage goes beyond hardware. Admins must work with vendors and developers to have the right software architecture and code to benefit from GPUs.

Graphics processing unit hardware is straightforward to install on most general-purpose servers, but its benefits are not automatic; they require the combined support of a software framework, drivers, hypervisor extensions and a GPU-enabled application to unlock any benefits.
A graphics processing unit chip can contain one or more separate GPU cores -- similar to CPU chips. However, the GPU chip itself is almost never enough to fulfill GPU roles, so the latest GPU chip sockets are rarely directly integrated onto server motherboards.
Graphics tasks can require multiple GPU chips with many cores, as well as extensive quantities of high-performance memory that is separate from main memory resources, powerful cooling and sophisticated I/O architecture to exchange data efficiently between the GPUs, graphics memory and the rest of the server. This means the GPU is part of a graphics subsystem that admins must install on one or more enterprise servers.
GPU implementation techniques
There are two main ways to enable GPU resources. The first approach is to install the GPU subsystem as an aftermarket upgrade onto one or more existing servers. Organizations typically opt to add aftermarket GPUs early in the adoption cycle when IT operations and developers are experimenting with GPU capabilities and benefits; this implementation is usually on a smaller scale.
The Nvidia Tesla V100 is available as a full-length, full-height GPU subsystem admins can install in a server motherboard's PCIe slot. The V100 includes 640 Nvidia Tensor cores, 5,120 Nvidia compute unified device architecture (CUDA) cores and 32 GB of high-performance dedicated graphics memory.
The biggest challenge with aftermarket GPU implementation is the additional power demands from the GPU subsystem. The Tesla V100, for example, requires an additional 250 watts of power from the server, and some GPUs can demand over 300 additional watts of power; the PCIe slot itself is not capable of channeling that much power.
Because the latest servers rarely oversize the physical power supply to any significant degree, it's easy for an organization to discover that a server lacks the power supply capacity -- and separate accessory power connectors -- to support the GPU subsystem after installation.
The second approach is to include GPUs as part of the organization's regular server refresh cycles. This approach lets admins buy or lease new servers from the vendors that preinstall and test the desired GPUs and suitable power supplies.
Preinstalled GPUs are a more desirable option for larger and more extensive GPU deployments. GPU vendors work closely with major server vendors to validate GPU-based systems. As an example, admins can preconfigure Dell PowerEdge servers with various AMD and Nvidia GPUs.
The actual choice of GPU vendor depends on how the infrastructure consumes the GPU resources and the associated use cases. There are three basic approaches to GPU implementation for workloads: dedicated, teamed and shared.
In the dedicated model, a GPU is dedicated to a workload or VM. This 1-to-1 ratio is often found in general-purpose high-performance computing or machine learning tasks where GPUs are used regularly, but the workload's GPU demands are moderate to heavy.
The teamed model assigns two or more GPUs to a workload or VM in a many-to-one ratio. This model is used in the most demanding situations such as genomic sequencing, Monte-Carlo simulations and GPU-enabled databases, and they often employ the most sophisticated GPUs with the most cores.
A shared model allows a single GPU to be shared across multiple workloads or VMs as a one-to-many ratio. This is possible in relatively light GPU use cases such as virtual desktop development and testing, light scientific problems or the inference cycles of machine learning. This lets organizations use lower-end or less-expensive GPUs with fewer cores.
Making GPUs work
Physical GPU subsystem installation is the easiest part of the process. However, simply plugging in a GPU has no effect on the server's workloads. In order for a workload to benefit from GPUs, the host system requires a comprehensive software stack that includes drivers, libraries and toolkits to help applications talk to the GPU. Admins must confirm the workload code uses GPUs.
GPU instruction sets differ from those used for everyday CPUs. To reap the benefits of a GPU, the workload -- and software -- must include code that specifically reads the GPU's functions. Underlying GPU drivers and libraries that comprise the GPU software stack all serve to see those instructions, redirecting those instructions and associated data to and from the GPU.
Thus, GPU implementation, use and provisioning are really a matter of software. Admins must consider the software components involved in GPU use before installation.
Programming extensions and interfaces
GPUs rely on software to facilitate GPU-based application development and functionality to simultaneously access the hardware's cores and threads.
Nvidia's CUDA provides libraries, compiler directives such as OpenACC, and compiler extensions for common programming languages such as C and C++. CUDA supports other computing interfaces such as OpenCL, OpenGL Compute Shaders and Microsoft's DirectCompute. Admins can wrap each interface in common languages such as Python, Perl, Fortran, Java, Ruby and Lua.
Admins not only need CUDA and corresponding drivers on the actual host server in order to operate the GPU, but they may require other supporting software such as OpenACC and OpenCL.
Virtualization support
Admins can virtualize GPU cores and provision virtual GPU (vGPU) workloads as other resources. Virtualization offerings such as VMware vSphere can support GPU virtualization but may require one or more additional software interfaces.
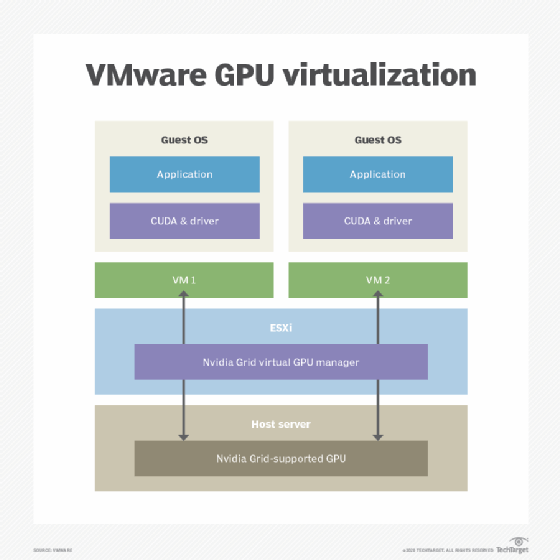
Nvidia vGPU software options include Nvidia Virtual Compute Server and Nvidia Quadro Virtual Datacenter Workstation. These tools, sometimes referred to as hypervisor extensions, allow GPU access and management within the VMware vSphere ESXi hypervisor, and they even support enhanced functionality within the virtualized architecture such as live migration through VMware vMotion. Though migration targets must have compatible GPU configurations and available GPU resources.
Application compatibility
In-house GPU-enabled software development is an effective way to tailor a GPU-intensive workload to an organization's unique requirements. But the work may not always be desirable -- or necessary -- for GPU implementation. Hundreds of professional, GPU-enabled applications are available to tackle tasks such as advanced mathematics, simulations and machine learning.
Admins can use canned application code to verify application compatibility with the underlying server and GPU hardware. The software vendors also outline the minimum and recommended system requirements for the software and compatible GPUs. GPU vendors often provide an application catalog to highlight compatible offerings from their software partners. In either case, it's vital to test the application carefully and ensure GPU compatibility.
Resource management practices
GPUs are valuable compute resources, and it is important to exercise the same kind of careful resource management applicable to CPUs and memory resources. By under-provisioning too few GPUs, the application may not perform at its optimum level, while over-provisioning wastes GPU resources and doesn't improve the workload.
Admins may subject cloud-based GPU-enabled clusters to processing quotas, to ensure that a compute cluster always has a minimum number of instances running to maintain workload performance. The Google Cloud Platform is one example where admins must set a Compute Engine GPU quota in a desired zone before they can create GPU-enabled cluster nodes -- such as Google Kubernetes Engine clusters. Data center automation and orchestration tools can help implement similar objectives.