
animind - Fotolia
Expand your edge data center vocabulary
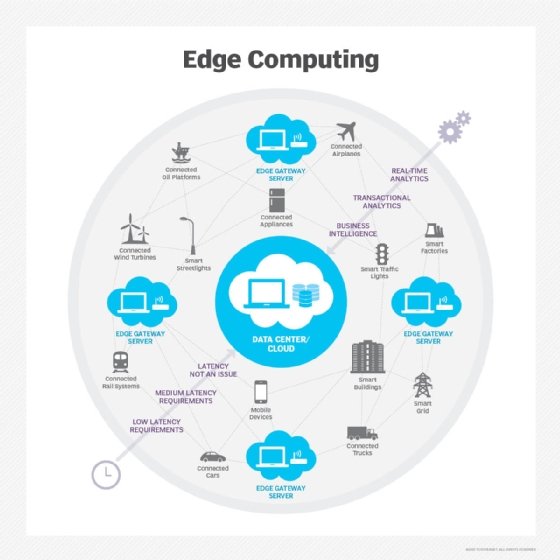
Data, devices and distributed computing are all important parts of edge setups. Learn about edge computing components and how you might see them in your organization.

Organizations are using edge data center deployments to bring processing hardware to the data source. The technology helps reduce bandwidth and throughput issues across all infrastructures and connected devices. With the emergence of IoT and newer cloud computing models, you might hear more talk surrounding edge in your organization.
Implementing this tech doesn't automatically mean you'll be installing data centers at every corner, but it does require you to track performance and maintain all connected data processing devices that sit on the outer edges of your organization's network. You also must be aware of any security and licensing concerns.
Learning about the following concepts will not only make installation easier, but it'll also inform you of any potential issues when bringing computing hardware to the edge.
Raw data: This data is collected but not applied to any specific use case; sometimes, it is automatically filed into a database before any type of processing. It is sometimes called cooked data once it is analyzed and processed. This raw data can come from a variety of devices and infrastructure components that are a part of the company's IT network.
Intelligent device: This is any equipment, machine or instrument that has its own computing capability. Aside from personal computers, examples include cars, home appliances and medical equipment.
With all the hype surrounding IoT and the number of intelligent devices that consumers and businesses use, the industry is working to solve networking connectivity issues with edge data centers. This has brought about device relationship management software and a new version of the Internet Protocol known as IPv6.
Remote office/branch office (ROBO): This is a corporate site located outside the company's headquarters. It can run similar to the main office but is often smaller and may house a specialized service or business unit. These buildings generally have less hardware on-site and don't have full-time backup and recovery staff, which makes them ideal for edge computing deployments.
These ROBO setups can be hard for your IT department to manage because they're not accessible on a daily basis for staff to troubleshoot issues and ensure smooth operations. Still, setting up monitoring and management resources is essential to get an accurate picture of all company-owned and -operated infrastructure in these edge data center locations.
distributed computing: This setup uses shared software resources across multiple computing systems to allocate processing needs. Using multiple distributed computing systems helps you improve efficiency and performance because you can pool resources so they don't max out processing units or graphics cards.
For businesses, this setup usually means placing different business processes throughout the IT framework. There is the three-tier model, the client/server communications model and grid computing. Each option provides different configurations for data collection protocols and processing speeds, which can vary depending on the needs of your edge data center deployments.
Lights-out management (LOM): With the right tech, LOM lets admins remotely monitor and manage servers. Hardware for this setup comes in a module and logging software, which tracks microprocessor utilization and temperature within the edge data center.
Possible remote operations include OS reinstallation, alarm setting, fan speed calibration, troubleshooting, rebooting and shutting the servers down. All activity is collected into an event log for as-needed admin review.
configuration drift: Because edge data centers are not always on-site, they sometimes fall through the cracks when it comes to maintenance. Configuration drift is the result of inconsistent or ad hoc infrastructure updates across the network and poor documentation. Along with increasing potential security vulnerabilities, this haphazard process can cause disaster recovery and high availability system shutdowns.
Database tools and software can help prevent configuration drift and security issues. It's also helpful to keep detailed logs of hardware network addresses, active software versions and recently applied updates.







