Similarities and differences between ROLAP, MOLAP and HOLAP
Find out the differences between ROLP, MOLAP and HOLAP and their advantages and disadvantages. Learn about data quality and the evolution of data warehouse applications.
 |
|
This section from Data Warehouse Design: Modern Principles and Methodologies discusses the differences between ROLP, MOLAP and HOLAP and the advantages and disadvantages of each. Get a definition of data quality and learn about data warehouse data quality, plus find information on the evolution of data warehouse applications and securing databases and data warehouses.
Table of contents:
![]() An introduction to data warehousing
An introduction to data warehousing
![]() Data warehouse architectures, concepts and phases
Data warehouse architectures, concepts and phases
![]() The advantages of multidimensional databases and cube modeling
The advantages of multidimensional databases and cube modeling
![]() Best practices for data warehouse access and reports
Best practices for data warehouse access and reports
![]() Similarities and differences between ROLAP, MOLAP and HOLAP
Similarities and differences between ROLAP, MOLAP and HOLAP

1.8 ROLAP, MOLAP and HOLAP
These three acronyms conceal three major approaches to implementing data warehouses, and they are related to the logical model used to represent data:
- ROLAP stands for Relational OLAP, an implementation based on relational DBMSs.
- MOLAP stands for Multidimensional OLAP, an implementation based on multidimensional DBMSs.
- HOLAP stands for Hybrid OLAP, an implementation using both relational and multidimensional techniques.
|
||||
The idea of adopting the relational technology to store data to a data warehouse has a solid foundation if you consider the huge amount of literature written about the relational model, the broadly available corporate experience with relational database usage and management, and the top performance and flexibility standards of relational DBMSs (RDBMSs). The expressive power of the relational model, however, does not include the concepts of dimension, measure, and hierarchy, so you must create specific types of schemata so that you can represent the multidimensional model in terms of basic relational elements such as attributes, relations, and integrity constraints. This task is mainly performed by the well-known star schema. See Chapter 8 for more details on star schemata and star schema variants.
The main problem with ROLAP implementations results from the performance hit caused by costly join operations between large tables. To reduce the number of joins, one of the key concepts of ROLAP is denormalization—a conscious breach in the third normal form oriented to performance maximization. To minimize execution costs, the other key word is redundancy, which is the result of the materialization of some derived tables (views) that store aggregate data used for typical OLAP queries.
From an architectural viewpoint, adopting ROLAP requires specialized middleware, also called a multidimensional engine, between relational back-end servers and front-end components, as shown in Figure 1-32. The middleware receives OLAP queries formulated by users in a front-end tool and turns them into SQL instructions for a relational back-end application with the support of meta-data. The so-called aggregate navigator is a particularly important component in this phase. In case of aggregate views, this component selects a view from among all the alternatives to solve a specific query at the minimum access cost.
Figure 1-32: ROLAP architecture
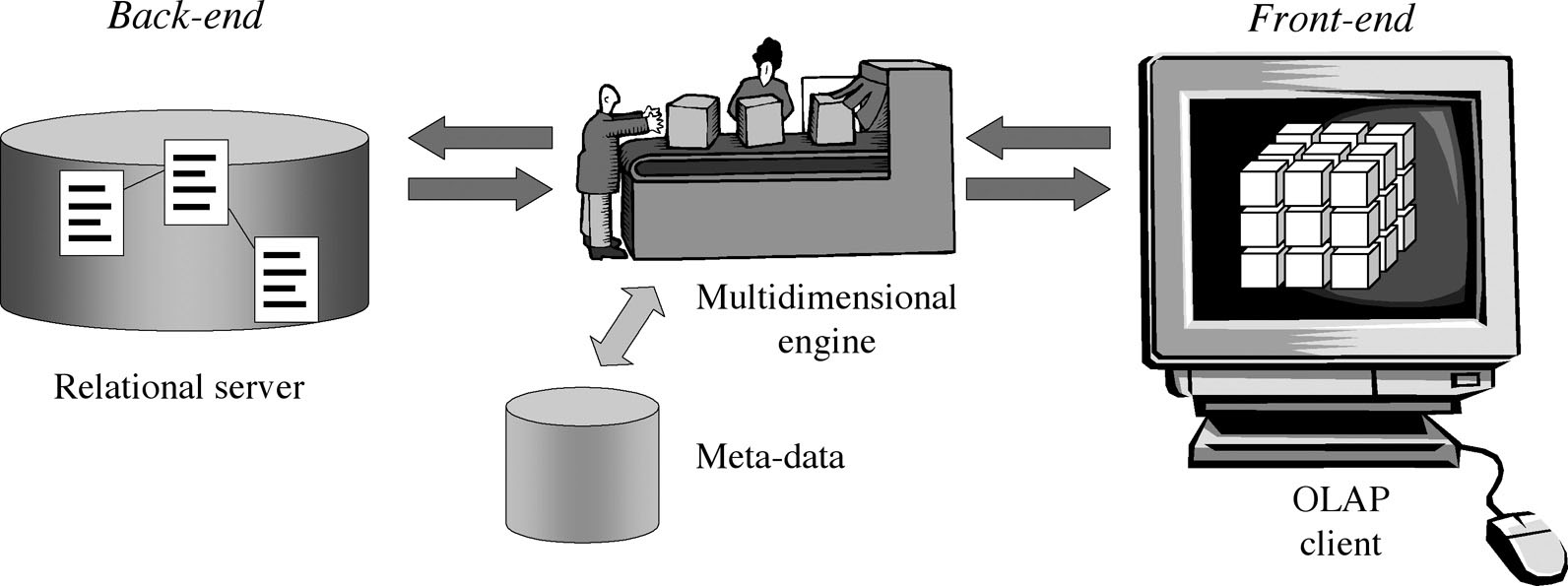
In commercial products, different front-end modules, such as OLAP, reports, and dashboards, are generally strictly connected to a multidimensional engine. Multidimensional engines are the main components and can be connected to any relational server. Open source solutions have been recently released. Their multidimensional engines (Mondrian, 2009) are disconnected from front-end modules (JPivot, 2009). For this reason, they can be more flexible than commercial solutions when you have to create the architecture (Thomsen and Pedersen, 2005). A few commercial RDBMSs natively support features typical for multidimensional engines to maximize query optimization and increase meta-data reusability. For example, since its 8i version was made available, Oracle's RDBMS gives users the opportunity to define hierarchies and materialized views. Moreover, it offers a navigator that can use meta-data and rewrite queries without any need for a multidimensional engine to be involved.
Different from a ROLAP system, a MOLAP system is based on an ad hoc logical model that can be used to represent multidimensional data and operations directly. The underlying multidimensional database physically stores data as arrays and the access to it is positional (Gaede and Günther, 1998). Grid-files (Nievergelt et al., 1984; Whang and Krishnamurthy, 1991), R*-trees (Beckmann et al., 1990) and UB-trees (Markl et al., 2001) are among the techniques used for this purpose.
The greatest advantage of MOLAP systems in comparison with ROLAP is that multidimensional operations can be performed in an easy, natural way with MOLAP without any need for complex join operations. For this reason, MOLAP system performance is excellent. However, MOLAP system implementations have very little in common, because no multidimensional logical model standard has yet been set. Generally, they simply share the usage of optimization techniques specifically designed for sparsity management. The lack of a common standard is a problem being progressively solved. This means that MOLAP tools are becoming more and more successful after their limited implementation for many years. This success is also proven by the investments in this technology by major vendors, such as Microsoft (Analysis Services) and Oracle (Hyperion).
The intermediate architecture type, HOLAP, aims at mixing the advantages of both basic solutions. It takes advantage of the standardization level and the ability to manage large amounts of data from ROLAP implementations, and the query speed typical of MOLAP systems. HOLAP implies that the largest amount of data should be stored in an RDBMS to avoid the problems caused by sparsity, and that a multidimensional system stores only the information users most frequently need to access. If that information is not enough to solve queries, the system will transparently access the part of the data managed by the relational system. Over the last few years, important market actors such as MicroStrategy have adopted HOLAP solutions to improve their platform performance, joining other vendors already using this solution, such as Business Objects.
1.9 Additional Issues
The issues that follow can play a fundamental role in tuning up a data warehouse system. These points involve very wide-ranging problems and are mentioned here to give you the most comprehensive picture possible.
1.9.1 Quality
In general, we can say that the quality of a process stands for the way a process meets users' goals. In data warehouse systems, quality is not only useful for the level of data, but above all for the whole integrated system, because of the goals and usage of data warehouses. A strict quality standard must be ensured from the first phases of the data warehouse project.
Defining, measuring, and maximizing the quality of a data warehouse system can be very complex problems. For this reason, we mention only a few properties characterizing data quality here:
- Accuracy : Stored values should be compliant with real-world ones.
- Freshness: Data should not be old.
- Completeness: There should be no lack of information.
- Consistency: Data representation should be uniform.
- Availability: Users should have easy access to data.
- Traceability: Data can easily be traced data back to its sources.
- Clearness: Data can be easily understood.
Technically, checking for data quality requires appropriate sets of metrics (Abelló et al., 2006). In the following sections, we provide an example of the metrics for a few of the quality properties mentioned:
- Accuracy and completeness: Refers to the percentage of tuples not loaded by an ETL process and categorized on the basis of the types of problem arising. This property shows the percentage of missing, invalid, and nonstandard values of every attribute.
- Freshness: Defines the time elapsed between the date when an event takes place and the date when users can access it.
- Consistency: Defines the percentage of tuples that meet business rules that can be set for measures of an individual cube or many cubes and the percentage of tuples meeting structural constraints imposed by the data model (for example, uniqueness of primary keys, referential integrity, and cardinality constraint compliance).
Note that corporate organization plays a fundamental role in reaching data quality goals. This role can be effectively played only by creating an appropriate and accurate certification system that defines a limited group of users in charge of data. For this reason, designers must raise senior managers' awareness of this topic. Designers must also motivate management to create an accurate certification procedure specifically differentiated for every enterprise area. A board of corporate managers promoting data quality may trigger a virtuous cycle that is more powerful and less costly than any data cleansing solution. For example, you can achieve awesome results if you connect a corporate department budget to a specific data quality threshold to be reached.
An additional topic connected to the quality of a data warehouse project is related to documentation. Today most documentation is still nonstandardized. It is often issued at the end of the entire data warehouse project. Designers and implementers consider documentation a waste of time, and data warehouse project customers consider it an extra cost item. Software engineering teaches that a standard system for documents should be issued, managed, and validated in compliance with project deadlines. This system can ensure that different data warehouse project phases are correctly carried out and that all analysis and implementation points are properly examined and understood. In the medium and long term, correct documents increase the chances of reusing data warehouse projects and ensure project know-how maintenance.
Note Jarke et al., 2000 have closely studied data quality. Their studies provide useful discussions on the impact of data quality problems from the methodological point of view. Kelly, 1997 describes quality goals strictly connected to the viewpoint of business organizations. Serrano et al., 2004, 2007; Lechtenbörger, 2001; and Bouzeghoub and Kedad, 2000 focus on quality standards respectively for conceptual, logical, and physical data warehouse schemata.
1.9.2 Security
Information security is generally a fundamental requirement for a system, and it should be carefully considered in software engineering at every project development stage from requirement analysis through implementation to maintenance. Security is particularly relevant to data warehouse projects, because data warehouses are used to manage information crucial for strategic decision-making processes. Furthermore, multidimensional properties and aggregation cause additional security problems similar to those that generally arise in statistic databases, because they implicitly offer the opportunity to infer information from data. Finally, the huge amount of information exchange that takes place in data warehouses in the data-staging phase causes specific problems related to network security.
Appropriate management and auditing control systems are important for data warehouses. Management control systems can be implemented in front-end tools or can exploit operating system services. As far as auditing is concerned, the techniques provided by DBMS servers are not generally appropriate for this scope. For this reason, you must take advantage of the systems implemented by OLAP engines. From the viewpoint of users profile–based data access, basic requirements are related to hiding whole cubes, specific cube slices, and specific cube measures. Sometimes you also have to hide cube data beyond a given detail level.
Note In the scientific literature there are a few works specifically dealing with security in data warehouse systems (Kirkgöze et al., 1997; Priebe and Pernul, 2000; Rosenthal and Sciore, 2000; Katic et al., 1998). In particular, Priebe and Pernul propose a comparative study on security properties of a few commercial platforms. Ferrandez-Medina et al., 2004 and Soler et al., 2008 discuss an approach that could be more interesting for designers. They use a UML extension to model specific security requirements for data warehouses in the conceptual design and requirement analysis phases, respectively.






