Fixing a critical bug in IT takes coordination and patience
Critical bugs are unavoidable, but IT staff can take measured steps to ease the process. The best approach combines respect for the IT staff and systems with the issue's severity.
The moment IT staff see a notable software bug on the local news station, they know it's going to be a long day in the IT department.
Soon, a flood of emails flows in as executives, customers and managers all want answers as soon as possible. For the most part, IT teams roll software bug remediation into their traditional maintenance cycle. But it's the critical bugs that make the news and grab people's attention.
Even if an organization's IT systems are up to date, a newsworthy bug is going to be an issue regardless. And if the IT team is seeing the news, so is the organization's executive team.
Here are some important steps IT operations teams can take to manage critical bug response and remediation.
Organize staff first
A critical bug that affects multiple systems requires all IT staff hands on deck. However, the key is not the number of hands, but rather how they're used. Any panicked or rushed decisions are liable to result in errors and chaos, which will only exacerbate -- and further extend -- the problem.
For IT staff, handling the situation to control the narrative requires defined communication and investigation.
1. Communication
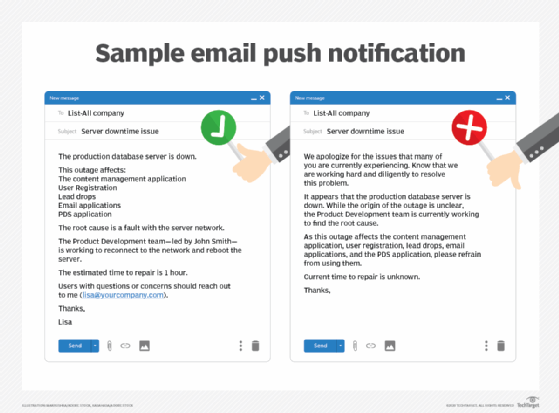
Establish a dedicated person, or team of people, to communicate the situation to users, management and business leaders. This can be a rotating responsibility or a dedicated role, but it is a vital one.
The rest of the IT team will work on other aspects of a critical bug fix and won't have time to field questions from users, managers and executives. A known, central source for information prevents constant work interruptions for staff attacking the problem.
The dedicated contact should deliver a vetted but thorough message to loop people into the situation. The message might vary between audiences, from users to executives, but shouldn't stray far. Be transparent without oversharing -- and that goes for messages to executives too. IT won't know all the details right away, and it's OK to say that. It's better than lying and causing more issues.
2. Investigation
Investigate the bug itself alongside its total area of effect on systems and applications. Ideally, at least two IT pros should conduct this process in concert.
The information-gathering stage is critical to formulate a plan for remediation. As staff learn more about the bug and create options for resolution, communicate these updates on a schedule via the assigned delegate. Then those affected by the bug will not look for per-second updates, but on a 15- or 30-minute -- or even longer -- schedule.
The two big questions to answer are what was affected and to what extent. It can take time to pull together this information, but it forms the basis for all communications about the issue.
Critical bug fix walkthrough
One of the first rules in IT on a Friday afternoon and before a holiday weekend is: Do no harm. In other words: Do not make any kind of change that could break any part of the IT ecosystem. Apply this rule to patch and mitigate the damage while fixing the bug. Actions that cause more issues or break applications lead down an ugly path.
While most OS fixes won't break applications, it can happen, so IT operations teams must prepare for that scenario -- before the scenario is upon them. In a dire situation, it's tempting to target front-facing and mission-critical infrastructure first.
IT teams are as important as the infrastructure is to recovery efforts, but they can't work 24/7.
Don't.
Instead, apply the fix to a few low-level servers as a safe test bed. Test the patch before any production deployment to ensure it doesn't take down critical infrastructure. Before testing a fix on anything, verify system backups are up to date.
Normally, it's not possible to take down all systems simultaneously to make wide-scale changes. Create a plan to follow during the testing stage that outlines the order in which IT admins should update internet-facing servers and critical infrastructure, with other systems following behind as possible.
Mitigate the risk exposure as quickly as possible without causing harm. Once external-facing servers are updated, focus on internal systems -- but also pause to take a breath. IT teams are as important as the infrastructure is to recovery efforts, but they can't work 24/7, nor should they.
If the organization's IT team is big enough, consider rotating staff responsibilities. However, accept the fact that a critical bug fix can be a process that takes several days to complete. And while management might be upset about that time frame, it is not a failure of the IT team. The fewer staff members in an IT department, the more difficult it can be to perform emergency problem resolutions quickly.
The goal of a critical bug fix is to patch or correct everything that went wrong. But some segments of the organization's ecosystem might be too old or demonstrate another issue that can't be addressed at this time. These weak spots lower an environment's overall security posture. Migrate those trouble spots to an isolated, supported location, where IT staff can work on them -- safely -- as soon as possible.
If the IT team can't correct the issue, consider a next-generation firewall -- preferably one that protects sensitive workloads and that IT admins can fix themselves. However, this option far eclipses the scope of an emergency server update.
And, of course, there is always the choice to take no further steps after the critical bug fix, but an IT environment is only as secure as its weakest link. If the IT team doesn't know where those weak points are, the next vulnerability could prove just as critical.