
Getty Images
Use AWS Glue workflows to convert semistructured data
New to AWS Glue? Learn about the tool and how to incorporate it into DevOps workflows with examples that look at data transformation and machine learning.

AWS Glue is an orchestration platform for ETL jobs. It is used in DevOps workflows for data warehouses, machine learning and loading data into accounting or inventory management systems.
Glue is based upon open source software -- namely, Apache Spark. It interacts with other open source products AWS operates, as well as proprietary ones -- notably Amazon S3 object storage and the Amazon DynamoDB database.
Glue is not a database; it's a schema -- also called metadata. It holds data tables that describe other data tables. Glue provides triggers, schedulers and manual ways to use those schemas to fetch data from one platform and push to another.
Glue does transformations with its web-based configuration and with Python and Scala APIs. To illustrate how your IT team can use Glue for its extract, transform and load (ETL) jobs, let's go over some of the basic workflow components. Then, we'll walk through how to use the service to organize semistructured data for analysis and to support and train a machine learning model.
Glue workflow
With Glue, the workflow generally follows these steps:
- Load external data into Amazon S3, DynamoDB or any row-and-column database that supports Java Database Connectivity, which includes most SQL databases. It supports JSON, XML, Apache Parquet, CSV or Avro file formats.
- Glue uses Apache Spark to create data tables in VMs that run Glue in Apache Hive format, atop a Hadoop file system.
- Load more data from another source.
- Run a transformation -- such as joins, drops, aggregation, mapping -- on the combined data sets from steps 1 and 2.
- Load data into a data warehouse such as Snowflake or Amazon Redshift, or use an API or bulk loader to move it into SAP.
Because this is a workflow, Glue can run jobs, foregoing the need for DevOps tool such as SaltStack. For example, admins could write code in Spark or Python to do this, and then use Salt to orchestrate jobs, but Salt does not have a database. This would create disjointed operations. With Glue, it all runs under the same code and context.
Glue-DevOps examples
Now that we've reviewed how Glue works, let's look at two use cases -- data transformation and a machine language workflow -- to better understand its practical application.
Author's note: To save money, download Glue locally and run it on your own machine to do part of the workload.
ETL programming
Glue has an Apache Spark shell that can be run with the command gluepyspark. It works like PySpark, the Python shell for Spark.
Run gluepyspark to start a Spark instance. Then, either write Python code in that shell or use it in batch mode and submit ETL jobs with gluesparksubmit.
Spark uses DataFrames, which facilitates SQL operations on data created from JSON, CSV and other file formats. Spark DataFrames are different from NumPy DataFrames, which are required for most machine learning SDKs. This limits Glue to one machine learning operation, discussed below.
Spark DataFrames have one big drawback: They require a schema first. Glue introduces the Dynamic Frame, which infers a schema where possible.
For example, here is how you would open a JSON file in Glue to create a Dynamic Frame:
from pyspark import SparkContext
from awsglue.context import GlueContext
glueContext = GlueContext(SparkContext.getOrCreate())
inputDF =
glueContext.create_dynamic_frame_from_options(connection_type = "s3",
connection_options = {"paths": ["s3://walkerbank/transactions.json"]},
format = "json")
Then, run SQL and Python operations on it to aggregate or otherwise transform the data to push it to the next system, like the data warehouse.
Glue FindMatches machine learning
As the name implies, the FindMatches ML Transform feature in AWS Glue finds matching data sets. IT teams can use this to group related items, or to deduplicate repeat records -- both common operations in ETL jobs.
To use Glue for machine learning, train the model with feature-label data, just like any other supervised learning tool. Then run test data through it and Glue assigns a label ID to records. It finds records that you defined as being equivalent in the training data.
Like other Glue jobs, admins can configure much or most of this in the Glue Console.
Begin by adding the transformation first step in the console, as seen in Figure 1.
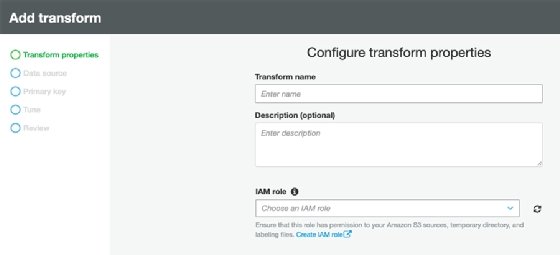
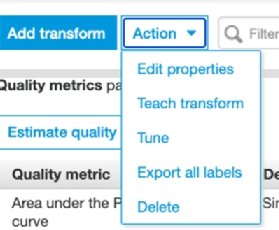
Then complete other tasks. For example, tune the model, make other changes or export the results.
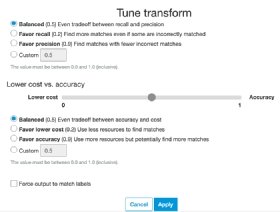
The screen in Figure 3 shows tuning parameters defined by AWS. There is a tradeoff between recall and precision. Pick the one you prefer and the degree to which you want to optimize that metric.
Recall and precision have mathematical definitions. Here's a simple way to know the difference:
- True positives / (true positives + false positives)
- True positives / (true positives + false negatives)
Create labels to detect and tag data by uploading a training set. AWS calls it a labeling file. Essentially, it's a feature label set -- see Figure 4 -- where labeling_set_id is the label, and the label is the basis for all classification problems.
In Figure 4, we train the model to classify the first two rows as being in the same group LBL123 and the last one in the group LBL345. These records could be anything, such as transactions, customers or scientific data.
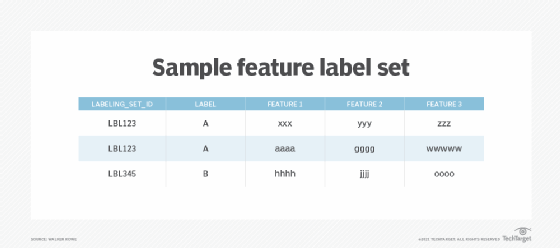
Notice there are no obvious similarities between the features, but that's the point. We use machine learning to identify relationships that might not be obvious at first glance. And those similarities will depend on the use case and how your organization defines them.
Dig Deeper on Systems automation and orchestration
-
![]()
Sagacious software: WisdomAI analytics agents act autonomously, with context
By: Adrian Bridgwater
-
![]()
Sample Questions for AWS' Machine Learning Associate Certification
By: Cameron McKenzie
-
![]()
Certified AWS Data Engineer Exam Dumps and Braindumps
By: Cameron McKenzie
-
![]()
Free AWS Data Engineer Associate Practice Exams
By: Cameron McKenzie



