
Getty Images/iStockphoto
UltiHash compresses, deduplicates data on a binary level
In this Q&A, the CEO of UltiHash talks about the continuous compression and deduplication it aims to provide primary storage while reducing storage needs.

Data compression has been around for more than 70 years, but UltiHash is bringing new techniques to the process at a time when companies are managing more data than ever and enterprise AI has exploded.
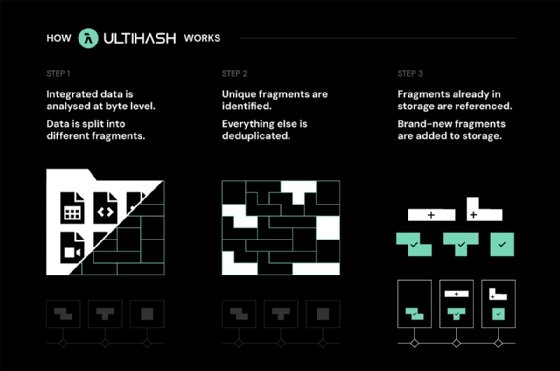
Founded in 2022 in Berlin and based in San Francisco, UltiHash is a storage startup focused on data compression and deduplication for high-performance workloads. Different from other compression and deduplication technology, the vendor's Sustainable Data Grid is designed to continuously compress and deduplicate data on a byte level as new data is stored. The object storage software is in early access as a public beta and works with file and block storage. It will be available through AWS Marketplace followed by an on-premises offering a few weeks later.
Deduplicating data on a binary level helps reduce storage needs even in the case of already compressed data, which the vendor said reduces the environmental stress of storage. UltiHash's deduplication works across local files as well as data in hybrid cloud environments and data lakes.
In this Q&A, UltiHash co-founder and CEO Tom Lüdersdorf talks about the startup's approach to storage, the potential challenges in going to market, why compression is a sustainability argument, and why better compression and deduplication technology might be able to increase the life of hardware.
Editor's note: The following interview was edited for length and clarity.
Can you explain what UltiHash is doing with deduplication and compression?
 Tom Lüdersdorf
Tom Lüdersdorf
Tom Lüdersdorf: When we think of data being shared with multiple parties -- across departments of an organization -- we're setting up a storage layer that can find duplications, [or] redundant fragments, across those environments and match them to another.
This has two effects: The first one is to reduce the hardware consumption that we have on the storage side. [The second] is to reduce the network [infrastructure and costs] required to send data from A to B.
We [are combining compression] with high performance. Often, deduplication and compression have been used in archival scenarios or backups. The downside of traditional deduplication, as well as compression algorithms, is that it consumes computational units, making the entire operation of reading or writing data relatively slow. UltiHash allows you to use deduplication technology in high-performance storage ... for machine learning, AI, data analytics as well as product engineering.
Other primary storage vendors that offer compression tie the technique to higher performance. Does UltiHash offer a better data compression ratio or less performance degradation?
Lüdersdorf: UltiHash does compression on a binary level, and we are looking at redundancies that are beyond what is similar on the content perspective. ... UltiHash goes a step further and looks for a variety of sizes of binary fragments that can be referenced to one another. [For example], you can find applications with a CSV [comma-separated values] file and a TIFF [Tag Image File Format]. Two data formats that are completely independent -- one shows a table of content, the other pixels in an image. Here, we combine deduplication, allowing us to mix data. [This is ideal for environments such as] data lakes where we often have mixed data sources. UltiHash can leverage those redundancies.
It is almost to the bit level, looking to making very small set changes to the size of the binary fragments in order to find the highest amount of redundancy.
Given the granularity, is it more difficult to decompress or retrieve data compared with traditional systems?
Lüdersdorf: The most important thing for our customers is to make sure that reading [data] is fast and there is no loss of data. ... We make sure security is the first given factor in storage and that customers don't have any overheads on reading. Often, with compression algorithms, there is overhead on reading as the data is unpacked. With UltiHash, reading can be fast as we're just looking up fragments that are recompiled and sent to applications.
There is interest in using processing units to offload data compression from the CPUs. Is utilizing DPUs or GPUs in UltiHash's future?
Lüdersdorf: For now, the CPU works great. There is potential to accelerate the compression process with GPUs in the future, if we are doing more complex calculations and comparisons. For the heuristics we are currently using, CPUs are perfectly fine.
You mentioned security earlier. My understanding is that when data is encrypted, the ability to compress data drops off. Is that still the case with UltiHash?
Lüdersdorf: That is still the case. We see higher redundancies on semantically similar data; the beauty of binaries is that they can be matched to another easier. However, we have also done tests on compressed data ... where we can further reduce already compressed data.
It is important to note here that some algorithms claim further compression by adding metadata, but users don't achieve any net savings. That is not the case with UltiHash. We have tested this, especially on image-based formats and video files, which often have compression enabled. In some cases, we see an additional space savings of 10% to 15%. This primarily happens because with deduplication, we can compare multiple files across each other. As the number of files grows, we can find additional binary fragments that can be matched to another, even for compressed files where the binary information is randomized already.
You don't have a specific data compression ratio you can hit?
Lüdersdorf: It depends on what data is stored. The larger the volume of data we are processing, the likelihood of redundancies increases. This comes from the effect that in all industries, the replication ratio of data is increasing. This has been studied over the last five years -- the ratio that every file produced is about six to seven times redundant. Now, we are more at a scale of nine to 10 [times] redundant over the last two to three years.
From a hardware technology perspective, if a customer has RAM, SSDs, HDDs and tape, can UltiHash compress data across all these?
Lüdersdorf: We can work across SSDs and HDDs. We are not working on top of tape at the moment because most of our customers are not building machine learning models on tape. Primarily, we are focused on SSDs.
And whether the data is file, block or object -- are there any problems there for UltiHash?
Lüdersdorf: That's not a problem. We have object storage with UltiHash. This is a proprietary technology that we are using and how we are delivering the data. We are also adopting the [Amazon] S3 API, so we will be offering an S3-compatible API to ensure that all the computing and processing engines on top of it can be used natively with UltiHash.
UltiHash believes this tech has a sustainability story to tell. But does the data compression you're doing drive up compute costs?
Lüdersdorf: The value proposition of UltiHash is the sustainability and resource efficiency of connecting fragments of data across networks. In our case, any savings on the storage or network side is not worth it if computing is higher. ... Often, there is a curve flattening at some point. It is our task to train our algorithm in a way that when the curve flattens, we can still get an additional 2% to 5% of space savings out of it. But not if the computational costs outweigh the savings.
The sustainability savings comes from storing less data, using fewer resources without affecting computation. Could this lead to longer lifecycles of hardware, in theory?
Lüdersdorf: That is one idea. If we are reducing the load on the disk itself, it is prolonging the lifecycle of the disk. ... We see a lot of work on measuring the CO2 footprint and energy consumption. ... But the other part is embodied carbon. Resource efficiency on the hardware side is slowing down, but we don't need the hardware to double in capacity every two years. The software side needs to take over to make sure the exponential growth in data is done proportionately.
What is the biggest challenge you anticipate going to market with your product?
Lüdersdorf: Currently, we cannot fulfill the needs of every possible use case, because we haven't built up this knowledge completely. We are trying to stay targeted on specific industries, on understanding those customers well. This is preventing us from, say, giving the technology out to 10,000 customers and offering support. We want to make sure that if UltiHash is used, it can provide value.
Adam Armstrong is a TechTarget Editorial news writer covering file and block storage hardware and private clouds. He previously worked at StorageReview.com.






