NVIDIA, AMD, and Intel: How they do their GPU virtualization
With three companies competing in the virtual GPU market, let's take a look at the key features between them and how they virtualize GPUs.

With all the conversation around GPU these days, especially because NVIDIA has competition now, I wanted to spend a bit of time looking at all three platforms. This isn’t a benchmarking article, but hopefully you’ll get an idea of what the landscape looks like faster than you would collecting resources yourself. A big shout-out goes to Randy Groves of Teradici, who put a lot of this information into a BriForum session that was quite possibly one of the best I’ve ever seen.
What makes a GPU?
Before we get into the GPUs themselves, let’s talk about the bits of the cards that we care about. In general the largest portion of the GPU is dedicated to shaders, which perform all the calculations to draw a model or 3D shape on the screen. The more you have, the more you can do. The faster they are, the faster you can do things. Shaders, for the most part, ARE the GPU.
Shaders aren’t just for graphics, and you may have heard of GPGPU (General Purpose GPU). Since GPUs contain many shaders, and shaders are floating point processors, they can perform many computational operations at the same time–parallel computing. Vendors enable this differently, both in physical and virtual implementations. When you hear the term CUDA or OpenCL, that means that the shaders in the GPU are capable of doing GPGPU tasks that can be accessed via the CUDA or OpenCL parallel programming APIs.
We’re talking about “traditional” GPU workloads, though, so none of that really relates to us, but it’s worth getting out there in a concise way.
In addition to shaders, GPUs also consist of video decoders and encoders. In general, these represent a relatively small portion of the chip. How they are used depends on whether the application or media player you’re using supports hardware accelerated encoding/decoding, and whether or not the GPU supports the CODEC that is being used.
Approaches to virtualized GPUs
In general, there are three fundamental types of virtualized GPUs: API Intercept, Virtualized GPU, and Pass-through.
API Intercept
The oldest of these, API Intercept, works at the OpenGL and DirectX level. It intercepts commands via an API, sends them to the GPU, then gets them back and shows the results to the user. Since this is all done in software, no GPU features are exposed. This also means that the software capabilities tend to lag behind the GPU in terms of what APIs are supported.
API Intercept typically has good performance when it works, but doesn’t have great application compatibility for mid-range to intense 3D apps. As of now it is the only method that supports vMotion.
Virtualized GPU
This is the hottest spot in desktop virtualization today, spare maybe storage and hyperconverged infrastructure. With Virtualized GPU, users get direct access to a part of the GPU. This is preferable to API Intercept because the OS uses the real AMD/NVIDIA/Intel drivers, which means applications can use native graphics calls as opposed to a genericized subset of them.
Virtualized GPU has better performance than API Intercept. Though it gives applications direct access to the CPU, the users are only getting a portion of the CPU, so it can still be limited in certain situations. That said, the application compatibility is good, but vMotion is not supported.
Pass-through
Pass-through, which if memory serves has been around for longer than Virtualized GPU, connects virtual machines directly to a GPU. If you have two cards in your server, then you get to connect two VMs to GPUs while everyone else gets nothing. This is great for the highest-end workloads, since VMs get access to all of the GPU and its features and application compatibility is great.
That said, Pass-through is the most expensive by far, and other than the high-end use case, the only other use cases are either GPGPU or as a reward for good performance at work (“Great job, Emily! You get to use the pass-through GPU-enabled VM for a week!”).
Types of GPUs
We’ll focus on vGPU, since that’s the most widely applicable GPU technology to desktop virtualization today. There are three different companies making virtual GPUs: Intel (GVT-g), AMD (MxGPU), and NVIDIA (vGPU). They each have a different term, but they’re really just product names. What sets them apart is how they do their virtualization.
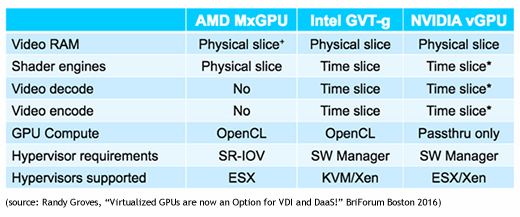
Video RAM
Though they do all give a physical slice of VRAM to each virtual machine. The key difference with how each handles VRAM is that since AMD’s MxGPU is 100% hardware-based, the individual virtual machines framebuffers (which is what lives in the VRAM) are physically isolated from one another, whereas with NVIDIA and Intel, the isolation is done by software. This is probably not an issue for most people, but could be important in situations where framebuffer security is a requirement.
Shader Engines
AMD differs from the others in how it slices up the shader engines, too. With MxGPU, virtual machines get a dedicated, physical slice of the shaders, whereas Intel and NVIDIA time slice VMs across all of their shaders. The difference is that time slicing gives the users 100% of the GPU for a proportional amount of time, whereas AMD gives users a proportional amount of GPU 100% of the time.
If users on Intel or NVIDIA GPUs aren’t using the GPU, that frees up more longer slices of time for users that are using the GPU, so the fewer the users the better the performance. With AMD, if a user isn’t using the GPU, those dedicated shaders go unused. That said, since the slicing NVIDIA and Intel do is done in software, the GPU can’t be turned back over to the pool until the last command command you sent to it has finished executing. That means that misbehaving applications could starve other VMs of GPU resources.
Video Encoding/Decoding
Here’s a situation where everyone is different. AMD doesn’t have any video encoding or decoding capabilities in MxGPU. Intel and NVIDIA both time slice their encoding/decoding hardware, but NVIDIA has an advantage over Intel in that they use a different time slicer for each component (shaders, video encoding, and video decoding). This adds some flexibility, for example, because a user who is only encoding a video is not affecting the GPU or video decoding users.
GPU Compute
We’ll gloss over this section since we already talked about GPGPU before (and because it’s not that relevant here), but the differences here are basically that AMD and Intel both support OpenCL APIs through virtual machines, while NVIDIA only supports GPGPU use cases in pass-through mode.
Hypervisor Requirements and Hypervisor Support
Both Intel and NVIDIA require a software manager to be installed into the hypervisor. This isn’t a big deal since both GPUs are certified to run on certain platforms (more on that in a minute), but it is an extra step. AMD utilizes SR-IOV, which essentially means that they designed their card to present itself to the BIOS in such a way that the BIOS treats it as if it’s several cards, which means you don’t need a software component in the hypervisor itself.
Over time, you can expect broad support for all cards on all hypervisors, but for now there are limitations. AMD is currently only certified on ESX, Intel supports KVM and XenServer, and NVIDIA supports both ESX and XenServer. Notably, Hyper-V isn’t supported at all, though you’d have to expect that to change soon. With Ignite coming up next week, maybe we’ll see some support then?
Wrap-up
This seems like a good place to stop for now, but there is a lot more information to be generated and collected when it comes to virtual GPUs. In future articles, we’ll take a look which approach to GPU makes the most sense for different types of applications, performance data, overall cost, and what our options are from DaaS providers (which until now has been pretty limited).






