How machine learning streamlines location data with the Kalman filter

We have spoken about machine learning and the internet of things as tools to optimize location analytics in logistics and supply chain management. It’s an accepted fact that technology, especially cloud-based, can benefit companies by optimizing routes and predicting the accurate estimated time of arrivals (ETAs). The direct business value of this optimization lies in the streamlining of various fixed and variable costs associated with logistics.
Companies can track the fuel consumption based on distance traveled while calculating instances of acceleration and hard braking. Moreover, companies can use real-time tracking to ensure that different service-level agreements (SLAs), such as elimination of nighttime drive or excessive speed variations, are met. Countries like the United States now mandate electronic logging devices be fitted with the trucks to track active driving hours and patterns.
All this tracking and optimization of factors is dependent on the assumption that the information being captured is accurate. Wrong data around distance traveled can show an inflated or under-par fuel consumption. Here, each situation might lead the company to assume a problem and spend hours fixing something that doesn’t exist. Moreover, the real problem might then be lost and might not get solved. In terms of SLAs, the companies may either erroneously record SLA breaches (or not record them altogether), leading to misunderstandings and invoicing errors.
It is extremely important to focus on clean and accurate data while using it to make business decisions.
The challenges of capturing location data
Let’s quickly understand the constraints while capturing location and movement data:
Tracking hardware
Trackers send out location-based pings in the form of signals. These signals are received by the company and fed into their logistics management system (LMS). The LMS records the movement of resources from the point they leave the originating warehouse until the point they reach their destination. Many companies don’t have the technology to track the resources in real time. However, they enlist the services of tracking and optimization professionals to help them manage their resources.
These tracking companies utilize the location data points (latitude-longitudes) of the resources movement to create a journey map for the trip. This is where errors first get showcased.
While the tracker is sending out location pings, the tracker might send erroneous pings, which could offset the actual route of the resource. For example, the reported location of a vehicle might be 10 meters to the left of its actual position. In the next second, it might be 10 meters to the right. These random fluctuations arise from internal hardware constraints or surrounding network problems (of the vehicle). When this (wrong) data is reported and processed, it gives the illusion that either a. the vehicle traveled more distance that it did, or b. the vehicle sped from one point to another in a short period.
In both scenarios, the proceeding information might lead the company to make an inefficient decision.
Tracking software
At the level of the software used to read and process the location information, there must be a built-in capability to clean and organize the incoming data. However, most tracking companies fail to differentiate between good tracking data and bad tracking data. This leads them to showcase ETAs that are predicted based on wrong data. This means that the delivery would either arrive later than expected or earlier. Hubs keep their own loaders-unloaders free around the time of delivery, and when the ETAs aren’t met, they lose on their time.
Even at the planning stage, the bad data creates forecasting problems, which mean that companies won’t be able to accurately map their costs to their active resources, leading to over or under capacity.
Now, that you know why good data is essential to optimization, here’s how LogiNext solved these problems using the Kalman filter.
Kalman filter: How it works
The Kalman filter is an innovative data cleansing method discovered initially by NASA for its Apollo missions. Since then, the filter has been randomly used for route and location corrections. The idea is that the filter recognizes sudden deviations (impulses) from the average data and marks the possibility of that data being erroneous. When this possibility or probability increases a preset threshold, then the filter auto-adjusts the information to be closer to the points reported before and after the erroneous data.
Tracking errors and corrections
This gives a more accurate set of information. The filter works as a preliminary validation engine for the incoming location information.
We updated and improved the Kalman Filter to add a learning ability to its original filtering process. This means that as the filter processes information, it learns from it and becomes more efficient the next time it is run. If at first run the filter worked with 70% efficiency, then the next time it would run at 72%, then at 78% and then further or until the engine is aware of each possible deviation and error points up to even a few yards. Even when a vehicle is moving at a regular speed or accelerating, the filter would be able to perfectly analyze whether the route (along with historical and current traffic and weather conditions) justifies the recorded tracking points.
In simple words, the updated Kalman Filter would tell whether the information being fed into the LMS is absolutely accurate or not. All bad data is dumped into a different database (which is again used as a benchmark to adjust all following information). The filter may recognize, for example, that when a vehicle moves along Route A while crossing a specific territory in the evening between 4:00-5:00 pm, the tracking information recorded tends to fluctuate due to detention, speeding, network issues or any other reason. It would clean and adjust the information to make it consistent and usable.
Applications of the Kalman filter in logistics management
Here is some of the actual tracking information received from erroneous hardware or infrastructure:
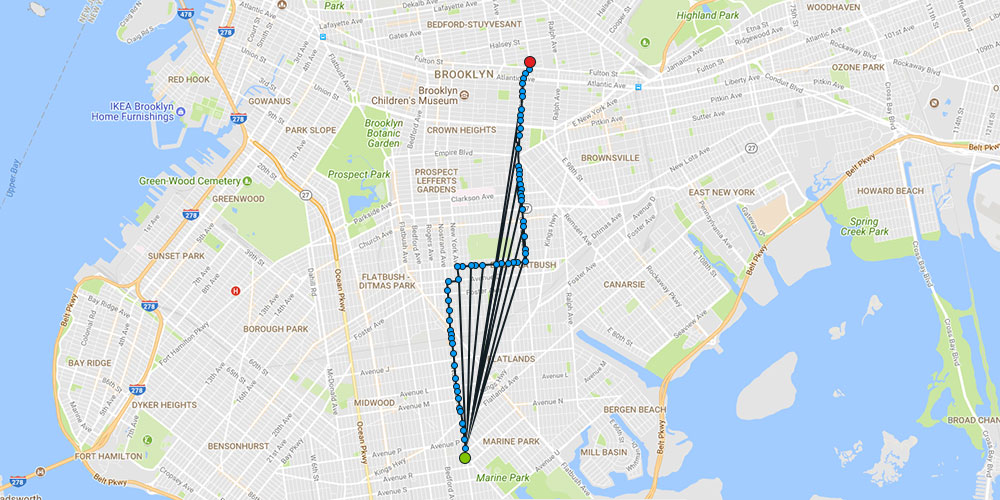
Kalman filter before corrections
It can be seen that the overall distance recorded would be higher than the actual distance the vehicle traveled. Even the ETA might be recalibrated, which might create warehousing and workforce problems (as mentioned earlier). With connectivity between hardware within vehicles, cellphone towers, servers and so forth improving every day, there still exist some processing errors that come up from time to time creating bad data. This bad data, when fed into the ERP of a company, then leads to errors and over or underestimations in planning. This leads to excess or shortage of resources or inventory, further leading to losses and inefficiency. This would eventually affect the end customer or client and damage the brand value of the company.
The covering layer of software must compensate for these errors. Hence, our machine learning enabled the Kalman Filter to run in real time along with real-time tracking of resources and fleet. This updated version of the filter is light and can be run instantaneously as the tracking information comes in. There is almost no lag between data reception, cleaning, adjustment and reporting. This means that when the manager views the traffic information in her dashboard, what she views is the accurate location, orientation and speed of each vehicle at any moment in time.
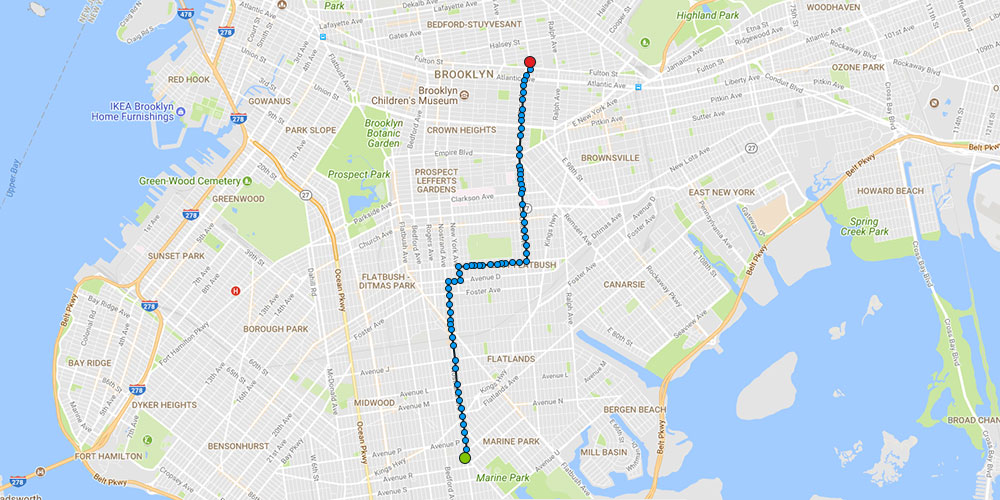
Kalman filter after corrections
As a part of the analytic reports, trip information such as route deviations, detention, delays and speed are all absolutely accurate. As we have seen earlier, this filter gets better the more it is run. So, each progressive report would be far more accurate than the previous one.
Accurate information helps companies take proper strategic decisions with a higher probability of success. It’s simple: if we work with the right information, the planning would be more precise, with a higher chance of on-time deliveries, lessened delays, greater resource utilization and higher customer and client satisfaction.
The updated Kalman filter, hence, adds to the growing progress towards creating more and more value for industry 4.0 using the internet of things.
All IoT Agenda network contributors are responsible for the content and accuracy of their posts. Opinions are of the writers and do not necessarily convey the thoughts of IoT Agenda.