
Getty Images
The 5 SOLID principles of object-oriented design explained
In this primer on SOLID, we'll examine the five principles this development ideology embodies, the practices they encourage and the reasons these concepts matter.

Anyone at least somewhat familiar with the basics of object-oriented programming likely knows that this development style has more to do with the underlying design practices than any type of specific language or framework choice. And while there are numerous claims and umpteen opinions regarding proper object-oriented design, the SOLID principles have established their authority as definitive rules that all developers in the field should follow.
The only way to truly understand SOLID principles, however, is to both learn the individual design practices they encourage and gain an understanding of why we talk about them alongside each other. To start, we'll examine each of the five SOLID principles of object-oriented design -- not so much to understand how they differ, but more so to illustrate the underlying concepts that make them inextricably connected.
What are the SOLID principles of object-oriented design?
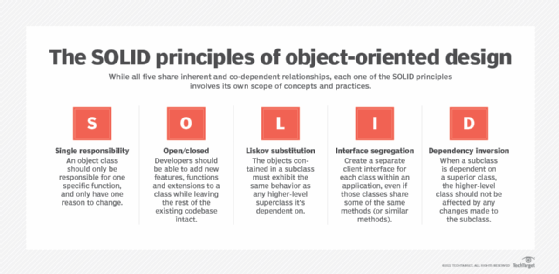
There are five specific aspects of object-oriented programming that each SOLID principle addresses, with each letter representing one principle. Thankfully, this acronym makes the five principles relatively easy to memorize:
- Single responsibility
- Open/closed
- Liskov substitution
- Interface segregation
- Dependency inversion
None of these principles are truly exclusive. On the contrary, one could argue that they are mutually inclusive. Some of these represent multiple strategies that each play a part in pursuing a single goal. Or, in other cases, they are byproducts: Proper adherence to one of these SOLID practices may naturally beget another.
For example, interface segregation is, in many ways, a reflection of the single-responsibility principle -- by implementing the latter correctly, the former will typically follow. Likewise, the dependency inversion principle is often easy to adhere to, provided that developers follow both the open/closed and Liskov substitution principles closely.
Let's break down each one, so we can better understand what we're really talking about when it comes to the five SOLID principles of object-oriented design.
Editor's note: The summaries included at the beginning of each principle's section are those given by Robert C. Martin, who is commonly credited with first applying these principles to the discipline of object-oriented programming.
1. Single responsibility
"Gather together those things that change for the same reason, and separate those things that change for different reasons."
Single responsibility embodies one of the basic tenets of object-oriented design. According to this principle, each object class (that is, the specific methods, variables and parameters defined within the object) added to a codebase should be responsible for only one specific job or function. In other words, classes should have only one reason to change: To reconfigure an individual process.
Unfortunately, it's possible to take this concept too far. Some might interpret the single responsibility principle to mean that every method that performs operations unique from the rest should have its own class. This, however, is a mistake. Over-parsing these methods will only spawn redundant classes that simply achieve the same goal in slightly different ways. At the very least, this will unnecessarily clutter your code. At worst, you'll end up creating a complex and tangled web of tightly coupled classes that will need to update in tandem.
Instead, developers should focus on the method's overall output, rather than the fact that it operates slightly differently from other methods. If two unique methods both support the same higher-level process, they belong in the same class -- regardless of the specifics behind their respective operations.
2. Open/closed
"Software entities (classes, modules, functions, etc.) should be open for extension, but closed for modification."
The open/closed principle's impact on design is relatively straightforward: Developers should be able to add new features to a codebase while leaving existing code intact. Practically speaking, the prospect of never needing to update a system's existent, underlying code to add a complex feature may seem impractical. Yet there are plenty of commonplace approaches that accomplish this, such as the plug-in architecture model and container-based deployment.
Theoretically, developers can implement the open/closed principle without concern for single responsibility. However, this is counterproductive to the overall point of SOLID, which is to logically isolate classes and their respective code segments as efficiently as possible. Stuffing classes with multiple responsibilities only increases the chance you'll need to update multiple parts of the codebase whenever a new feature enters the mix. In other words, you're essentially trading one problem (immutability) for another (coupling).
3. Liskov substitution
"Objects of a superclass shall be replaceable with objects of its subclasses without breaking the application."
If the Liskov substitution principle seems complex, don't worry -- this is a concept many developers struggle with at first.
As most experienced developers know, classes sometimes contain other classes. For the sake of this explanation, we'll identify a class that contains other classes as a superclass, and the classes within the superclass as subclasses. Keep in mind, however, that these terms designate the specific relationship between two or more classes (just like a person could be "taller" or "shorter" than someone else). For instance, a superclass could very well be a subclass of a superior class -- we would simply change the designations to illustrate the relationship.
Using these designations, we can summarize the Liskov substitution by saying that the objects contained in a subclass must exhibit the same behavior as those in the superclass. Specifically, this can mean that the methods associated with a subclass's objects shouldn't call any variables, demand any parameters or return any data types that methods in the superclass don't. Or, if the subclass object accepts something as an input for processing, the superclass must be capable of accepting that same input and processing it the same way. No matter the specific case, the behavior must be the same.
One major objective of Liskov substitution is to decrease the amount and frequency of crash-inducing runtime errors. If a requesting client calls a subclass, it's foreseeable that it will also call the superclass at some point. It's also possible that the client will try to relay requests to a superclass in the event of a failure. If that subclass demands parameters, variables or anything else that the superclass doesn't, the requesting service will likely assume it must pass the same inputs to that superclass. Since it's inputting data the superclass doesn't recognize, the request will return an exception.
4. Interface segregation
"Clients should not be forced to rely on interfaces they don't use."
For the purposes of this principle, an interface is defined as the sets of statements, functions and other code-based data that passes any needed instructions back and forth between two or more software components. Many methods will require clients to provide certain inputs, and individual methods will need instructions on what to do. This is the interface's job.
Imagine there is a class, which we'll call Class A, that operates through a single interface. Following the single responsibility principle, a developer decides to create a new class, Class B, which extends the capabilities of Class A. Since the two classes produce similar outputs, using only slightly different methods, the developer may feel comfortable placing both classes under a single operating interface.
This would be a mistake. Any client who wants to access just one of these classes will have to pass parameters for methods it doesn't need, resulting in needless data exchanges. What's more, any update to Class B will then require a change to the interface, which may also entail a change to Class A (blatantly violating the open/closed principle). Instead, create an operating interface for each class -- clients can still access the two methods through a larger, encapsulating interface that sits above the rest.
5. Dependency inversion
Technically, dependency inversion comprises two separate principles:
- "High-level modules should not depend on low-level modules. Both should depend on abstractions."
- "Abstractions should not depend on details. Details should depend on abstractions."
In essence, if any module in a software design is dependent on a higher-level component, that superior component should not feel the effects of any changes to its dependent. While the terms module and component can mean any number of things in software development, we'll stick to illustrating this principle in terms of class dependencies.
At first glance, this may appear to be simply a matter of reversing problematic coupling and ensuring that dependencies only flow to higher-level classes. With dependency inversion, however, the objective is to add another interface that decouples the dependency entirely. This additional interface is called an abstraction.
This new abstraction will serve as the glue that connects lower-level and higher-level classes, while it also provides each the flexibility to change without affecting the other. Since the superior class can handle any job required of the lower class, it can use this newly abstracted interface to perform those tasks. Otherwise, the higher-level class will use its own interface to perform the more complex jobs it's required to handle. As long as the abstractions remain intact, each class is free to change as it likes without interfering with the other's operations.
There are all sorts of examples of these abstracted interfaces at the software architecture level. One of the most prominent examples, as of late, are the API gateways that developers use to decouple the components within a microservices architecture. However, these abstractions take many forms, and it's safe to say that there will be more in the future.
Fred Churchville is the former site editor for SearchAppArchitecture. He started working at TechTarget shortly after graduating with a degree in journalism, and he exclusively covered the application architecture, development and management space.






