How to implement asynchronous replication in Apache Pulsar
David Kjerrumgaard explains how asynchronous replication works in Apache Pulsar for those still learning to use this platform as part of their data backup strategy.
This article, which was excerpted from Appendix B of Apache Pulsar in Action, discusses asynchronous replication patterns in Apache Pulsar and how to implement them. Follow this link and take 35% off Apache Pulsar in Action in all formats by entering "ttkjerrumgaard" into the discount code box at checkout.
Asynchronous geo-replication patterns
With asynchronous replication, Pulsar provides tenants a great degree of flexibility for customizing their replication strategies. That means that an application is able to set up active-active and full-mesh replication, active-standby replication and aggregation replication across multiple data centers. Let's take a quick look at how to implement each of these patterns inside of Apache Pulsar.
Multi-active geo-replication
Asynchronous geo-replication is controlled on a per-tenant basis in Pulsar. This means geo-replication can only be enabled between clusters when a tenant has been created that allows access to all of the clusters involved. In order to configure Multi-Active Geo-Replication, you need to specify which clusters a tenant has access to via the pulsar-admin CLI, as shown in Listing 1, which shows the command to create a new tenant and grant it permission to access the us-east and us-west clusters only.
Listing 1. Granting tenant access to clusters
$ /pulsar/bin/pulsar-admin tenants create customers \ #A --allowed-clusters us-west,us-east \ #B --admin-roles test-admin-role
#A Create a new tenant named customers
Now that the tenant has been created, we need to configure the geo-replication at the namespace level. Therefore, we will first need to create the namespace using the pulsar-admin CLI tool and then assign the namespace to a cluster -- or multiple clusters -- using the set-clusters command as shown in Listing 2.
Listing 2. Assigning a namespace to a cluster
$ /pulsar/bin/pulsar-admin namespaces create customers/orders $ /pulsar/bin/pulsar-admin namespaces set-clusters customers/orders \ --clusters us-west,us-east,us-central

By default, once replication is configured between two or more clusters as shown in Listing 2, all of the messages published to topics inside the namespace in one cluster are asynchronously replicated to all the other clusters in the list. Therefore, the default behavior is effectively full-mesh replication of all the topics in the namespace with messages getting published in multiple directions. When you only have two clusters, then the default behavior can be thought of as an active-active cluster configuration, where the data is available on both clusters to serve clients, and in the event of a single cluster failure, all of the clients can be redirected to the remaining active cluster without interruption.
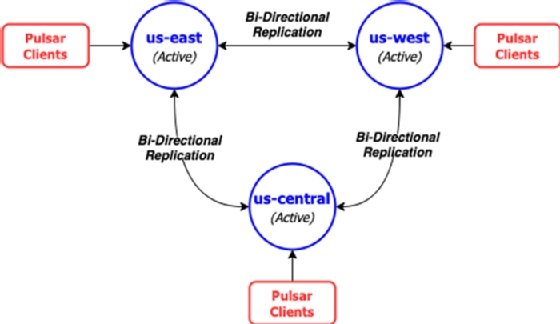
Besides full-mesh (active-active) geo-replication, there are a few other replication patterns you can use. Another common one for disaster recovery is the active-standby replication pattern.
Active-standby geo-replication
In this situation, you are looking to keep an up-to-date copy of the cluster at a different geographical location so that you can resume operations in the event of a failure with a minimal amount of data loss or recovery time.
Since Pulsar doesn't provide a means for specifying one-way replication of namespaces, the only way to accomplish this configuration is by restricting the clients to a single cluster known as the "active" cluster and having them all failover to the standby cluster only in the event of a failure. Typically, this can be accomplished via a load balancer or other network-level mechanism that makes the transition transparent to the clients, as shown in Figure 2. Pulsar clients publish messages to the active cluster which are then replicated to the standby cluster for backup.
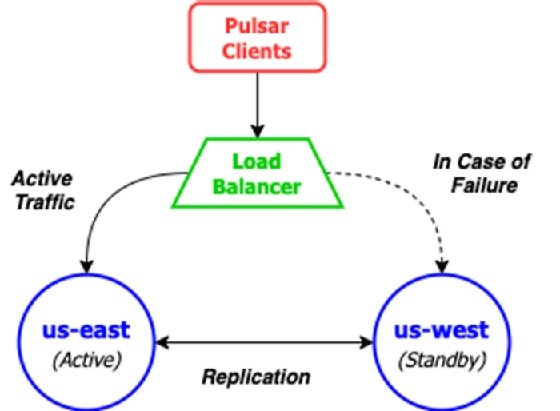
As you may have noticed, the replication of the Pulsar data will still be done bidirectionally, which means that the us-west cluster will attempt to send the data it receives during the outage to the us-east cluster. This might be problematic if the failure is related to one or more components within the Pulsar cluster, or the network for the us-east cluster is unreachable, etc. Therefore, you should consider adding selective replication code inside your Pulsar producers to prevent the us-west cluster from attempting to replicate messages to the us-east cluster, which is most likely dead.
You can restrict replication selectively, by directly specifying a replication list for a message at the application level. The code in Listing 3 shows an example of producing a message that will only be replicated to the us-west cluster, which is the behavior you want in this active-standby scenario.
Listing 3. Selective replication per message
List restrictDatacenters = Lists.newArrayList("us-west");
Message message = MessageBuilder.create()
…
.setReplicationClusters(restrictDatacenters)
.build();
producer.send(message);
Sometimes you want to funnel messages from multiple clusters into a single location for aggregation purposes. One such example would be gathering all the payment data collected from across all the geographical regions for processing and collection, etc.
Aggregation geo-replication
Assume we have three clusters all actively serving the customers in their respective regions, and a fourth Pulsar cluster named "internal" that is completely isolated from the web and only accessible by internal employees that is used to aggregate the data from all of the customer-serving Pulsar clusters as shown in Figure 3. In order to implement Aggregation Geo-Replication across these four clusters, you will need to use the commands shown in Listing 4, which first creates the "E-payments" tenant and grants access to all the clusters.
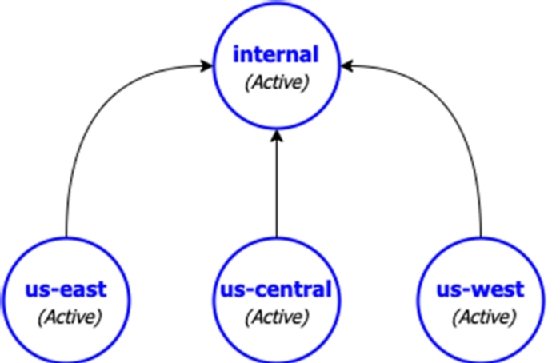
Next you will need to create a namespace for each of the customer services clusters, e.g., E-payments/us-east-payments. You cannot use one such as E-payments/payments because that would lead to full mesh replication if you attempted to use it, since every cluster would have that namespace. Thus, a per-cluster namespace is required in order for this to work.
Listing 4. Aggregator geo-replication
/pulsar/bin/pulsar-admin tenants create E-payments \ #A --allowed-clusters us-west,us-east,us-central,internal /pulsar/bin/pulsar-admin namespaces create E-payments/us-east-payments #B /pulsar/bin/pulsar-admin namespaces create E-payments/us-west-payments /pulsar/bin/pulsar-admin namespaces create E-payments/us-central-payments /pulsar/bin/pulsar-admin namespaces set-clusters \ #C E-payments/us-east-payments --clusters us-east,internal /pulsar/bin/pulsar-admin namespaces set-clusters \ #D E-payments/us-west-payments --clusters us-west,internal /pulsar/bin/pulsar-admin namespaces set-clusters \ #E E-payments/us-central-payments --clusters us-central,internal
If you decide to implement this pattern and you intend to run identical copies of an application across all the customer servicing cluster, then be sure to make the topic name configurable so that the application running on us-east knows to publish messages to topics inside the us-east-payments namespace, etc. Otherwise, the replication will not work.
About the author:
David Kjerrumgaard is the director of solution architecture at Streamlio, and a contributor to the Apache Pulsar and Apache NiFi projects.







