Getty Images
Learn to use Kubernetes CRDs in this tutorial example
Custom resource definitions enable IT organizations to create objects Kubernetes doesn't offer by default. Learn how to use them here.

Kubernetes exposes a powerful declarative API system, where the record of intent or desired state is specified by cluster operators in a YAML file or via the REST API, and the controllers work in a control loop to converge intent with the observed state.
At a high level, typically, the Kubernetes resources operate in the following way:
- record of intent created and persisted in the data store; and
- controllers, which are always active, read these records and create, update or delete resources.
This declarative records paradigm is complemented by practices like GitOps, where the entire cluster state and operations can be performed by making changes to these records stored in a version control repository.
Also, Kubernetes stores these records of resources and makes them available via a RESTful HTTP API exposing create, read, update, delete cycle semantics for these objects and resources out of the box.
A Kubernetes resource is a collection of similar objects accessible via the Kubernetes API. Kubernetes comes with several resources by default, such as pods, deployments and ReplicaSets.
What are custom resources?
In a nutshell, custom resources are extensions of the Kubernetes API. But, unlike a normal resource, custom resources are not necessarily available in a default Kubernetes installation.
Custom resources are instead registered dynamically to a cluster. Once the custom resource is registered, end users can create, update and delete its object using kubectl, similar to how users interact with built-in resources, like pods, deployments and services.
Custom resources are used for small, in-house configuration objects without any corresponding controller logic -- and are, therefore, defined declaratively.
What are custom resource definitions?
A custom resource definition (CRD) is a powerful feature introduced in Kubernetes 1.7.
The standard Kubernetes distribution ships with many built-in API objects and resources. CRDs enable IT admins to introduce unique objects or types into the Kubernetes cluster to meet their custom requirements. A Kubernetes CRD acts like any other Kubernetes object: It uses all the features of the Kubernetes ecosystem -- for example, its command-line interface (CLI), security, API services and role-based access control. The custom resource is also stored in the etcd cluster with proper replication and lifecycle management. CRDs eliminate the overhead of self-directed implementation as well.
CRDs are, by themselves, just blobs of data: Their primary purpose is to provide a mechanism to create, store and expose Kubernetes API objects that contain data that suits any requirements not satisfied by default. CRDs do not have any logic attached, nor any special behavior; once they are created, modified or removed, they take no actions on their own.
However, to bring more advanced functionality for these custom resources, implement controllers or operators. These enable IT admins to extend the behavior of Kubernetes without modifications to the underlying code. This functionality interacts well with CRDs, and using these two together, IT teams can implement some relatively advanced features and functionality.
The API server is a component of the Kubernetes control plane that exposes the Kubernetes API. The API server is the front end for the Kubernetes control plane. CRD operations, however, are handled inside kube-apiserver by the apiextensions-apiserver module. This is not a separate process, but a module integrated into kube-apiserver.
Use cases
Imagine a platform team is building an application hosting and CI/CD platform that manages the entire application lifecycle. It is creating a pipeline that will build, test and publish the application; via that pipeline, IT teams deploy the application into the Kubernetes cluster using in-house patterns.
Extending the Kubernetes API to declare custom resources enables IT admins to create opinionated platform resources on top of Kubernetes. Because the APIs are declarative, IT organizations can build and use platforms through self-service activity.
To illustrate how to use CRDs on the Kubernetes API, let's evaluate an example use case: The IT operations team wants to build an application CI/CD platform and expose it as a Kubernetes custom resource. This custom resource requires user input to build and deploy an application on top of Kubernetes. The first section of the tutorial below displays the minimum input for setup:
- appId is the application's unique name, presented as a string identifier.
- code language is any predefined language supported in the framework, such as C#, Python or Go.
- OS options are restricted to Windows or Linux.
- instanceSize should be "T-shirt size" -- predefined CPU and memory sizes, e.g. "small" could mean 100m CPU and 512 mebibyte memory -- for the pods that are spun up. Allowed values are small, medium and large.
- environmentType is metadata that classifies the type of environment for the app. Allowed values are dev, test and prod.
- replicas is the minimum number of app replicas to maintain, which should be set to 1.
Author's note: When establishing user input requirements, often, we develop some syntactic rules for the values we choose to accept as input. CRDs enable us to express these rules in a JavaScript Object Notation (JSON) schema syntax.
Create the custom resource definition
When we create a new CustomResourceDefinition API, the Kubernetes API server creates a new RESTful resource path for each specified version. The CRD can be either namespaced or cluster-scoped, as specified in the CRD's scope field.
As with existing built-in Kubernetes objects, deleting a namespace deletes all custom objects within it. Because CustomResourceDefinitions themselves are not namespaced, they are not deleted with a namespace deletion and remain available to all existing namespaces.
In this tutorial, we define the CRD for an object of kind: MyPlatform. This object stores the required information for the application platform we are building.
We use the API group contoso.com, but this group could also be the domain for your company, for example. This resource will be namespaced; under versions, we start off with v1alpha1 because this will change before hitting production.
Under the v1alpha1 version, we specify a JSON schema that defines the structure of the input. This is referred to as defining a structural schema and follows some rules, which validates user input.
apiVersion: apiextensions.k8s.io/v1
kind: CustomResourceDefinition
metadata:
# name must match the spec fields below, and be in the form: <plural>.<group>
name: myplatforms.contoso.com
spec:
# group name to use for REST API: /apis/<group>/<version>
group: contoso.com
names:
# plural name to be used in the URL: /apis/<group>/<version>/<plural>
plural: myplatforms
# singular name to be used as an alias on the CLI and for display
singular: myplatform
# kind is normally the CamelCased singular type. Your resource manifests use this.
kind: MyPlatform
# shortNames allow shorter string to match your resource on the CLI
shortNames:
- myp
# either Namespaced or Cluster
scope: Namespaced
versions:
- name: v1alpha1
# Each version can be enabled/disabled by Served flag.
served: true
# One and only one version must be marked as the storage version.
storage: true
schema:
openAPIV3Schema:
type: object
properties:
spec:
type: object
properties:
appId:
type: string
language:
type: string
enum:
- csharp
- python
- go
os:
type: string
enum:
- windows
- linux
instanceSize:
type: string
enum:
- small
- medium
- large
environmentType:
type: string
enum:
- dev
- test
- prod
replicas:
type: integer
minimum: 1
required: ["appId", "language", "environmentType"]
required: ["spec"]
We register the above CRD using the kubectl apply command:
kubectl apply -f ./crd.yaml
Once the CRD is registered, verify that by running the kubectl get crds command. Or we could use kubectl api-resources | grep myplatform instead.
Creating the custom resource
With the CRD registered in our cluster, we can create records for the custom resource. The manifest below creates a new instance of our new CRD.
Author's note: The apiVersion, kind or metadata fields are not defined above, as they are defined by default. However, all resources that follow must have these fields defined.
apiVersion: contoso.com/v1alpha1
kind: MyPlatform
metadata:
name: test-dotnet-app
spec:
appId: testdotnetapp
language: csharp
os: linux
instanceSize: small
environmentType: development
replicas: 3
Now, when we issue the kubectl apply -f ./cr.yaml command, it returns an error:

This error specifies that the input object is invalid, as the JSON schema defined this custom resource's spec.environmentType field, which accepts enum values of dev, test and prod. This demonstrates the validations that can be added out of the box with predefined schemas to the custom resource input fields.
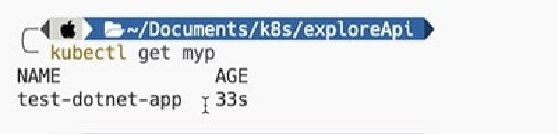
Now, if we fix the above error and then rerun the command kubectl apply -f ./cr.yaml, it creates a custom resource instance or record:
apiVersion: contoso.com/v1alpha1
kind: MyPlatform
metadata:
name: test-dotnet-app
spec:
appId: testdotnetapp
language: csharp
os: linux
instanceSize: small
environmentType: dev
replicas: 3
We can now use the familiar kubectl command to retrieve these records -- remember that myp is the short name for our CRD.
kubectl get myp #