Apache Pulsar vs. Kafka and other data processing technologies
David Kjerrumgaard looks at how the distributed messaging platform Apache Pulsar handles storage compared to Apache Kafka and other data processing technologies.
This article discusses how Apache Pulsar handles storage and compares it to how other popular data processing technologies, such as Apache Kafka, deal with storage. Follow this link and take 35% off Apache Pulsar in Action in all formats by entering "ttkjerrumgaard" into the discount code box at checkout.
Scalable storage
Apache Pulsar's multilayered architecture completely decouples the message serving layer from the message storage layer, allowing each to scale independently. Traditional distributed data processing technologies such as Hadoop and Spark have taken the approach of co-locating data processing and data storage on the same cluster nodes or instances. That design choice offered a simpler infrastructure and some possible performance benefits due to reducing transfer of data over the network, but at the cost of a lot of tradeoffs that impact scalability, resiliency and operations.
Pulsar's architecture takes a very different approach that's starting to gain traction in a number of cloud-native solutions. This approach is made possible in part by the significant improvements in network bandwidth that are commonplace today: separation of compute and storage. Pulsar's architecture decouples data serving and data storage into separate layers: Data serving is handled by stateless "broker" nodes, while data storage is handled by "bookie" nodes as shown in Figure 1.
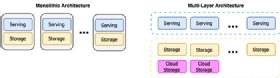
This decoupling has many benefits. For one, it enables each layer to scale independently to provide infinite, elastic capacity. By leveraging the ability of elastic environments (such as cloud and containers) to automatically scale resources up and down, this architecture can dynamically adapt to traffic spikes. It also improves system availability and manageability by significantly reducing the complexity of cluster expansions and upgrades. Further, this design is container-friendly, making Pulsar the ideal technology for hosting a cloud native streaming system. Apache Pulsar is backed by a highly scalable, durable stream storage layer based on Apache BookKeeper that provides strong durability guarantees, distributed data storage and replication and built-in geo-replication.

A natural extension of the multilayered approach is the concept of tiered storage in which less frequently accessed data can be offloaded to a more cost-effective persistence store such as S3 or Azure Cloud. Pulsar provides the ability to configure the automated offloaded of data from local disks in the storage layer to those popular cloud storage platforms. These offloads are triggered based upon a predefined storage size or time period and provide you with a safe backup of all your event data while simultaneously freeing up storage capacity on the local disk for incoming data.
Comparison of Apache Pulsar vs. Kafka
Both Apache Kafka and Apache Pulsar have similar messaging concepts. Clients interact with both systems via topics that are logically separated into multiple partitions. When an unbounded data stream is written to a topic, it is often divided into a fixed number of equal sized groupings known as partitions. This allows the data to be evenly distributed across the system and consumed by multiple clients concurrently.
The fundamental difference between Apache Pulsar and Apache Kafka is the underlying architectural approach each system takes to storing these partitions. Apache Kafka is a partition-centric pub/sub system that is designed to run as a monolithic architecture in which the serving and storage layers are located on the same node.
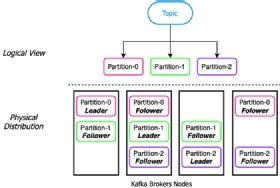
Partition-centric storage in Kafka
In Kafka, the partition data is stored as a single continuous piece of data on the leader node, and then replicated to a preconfigured number of replica nodes for redundancy. This design limits the capacity of the partition, and by extension the topic, in two ways. First, since the partition must be stored on local disk, the maximum size of the partition is that of the largest single disk on the host machine (approximately 4 TB in a "fresh" install scenario); second, since the data must be replicated, the partition can only grow to the size of smallest amount of disk space on the replica nodes.
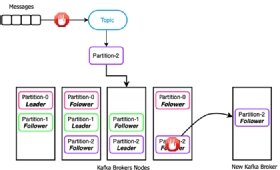
Let's consider a scenario in which you were fortunate enough to have your leader be placed on a new node that can dedicate an entire 4 TB disk to the storage of the partition, and the two replica nodes each only have 1 TB of storage capacity. After you have published 1 TB of data to the topic, Kafka would detect that the replica nodes are unable to receive any more data and all incoming messages on the topic would be halted until space is made available on the replica nodes, as shown in Figure 3. This scenario could potentially lead to data loss, if you have producers that are unable to buffer the messages during this outage.
Once you have identified the issue, your only remedies are to either make more room on the existing replica nodes by deleting data from the disks, which will result in data loss, since the data is from other topics and most likely has not been consumed yet. The other option is to add additional nodes to the Kafka cluster and "rebalance" the partition so that the newly added nodes will serve as the replicas. Unfortunately, this requires recopying the entire 1 TB partition, which is an expensive, time-consuming and error-prone process that requires an enormous amount of network bandwidth and disk I/O. What's worse is that the entire partition is completely offline during this process, which is not an ideal situation for a production application that has stringent uptime SLAs.
Unfortunately, recopying of partition data isn't limited to only cluster expansion scenarios in Kafka. Several other failures can trigger data recopying, including replica failures, disk failures or machine failures. This limitation is often missed until users experience a failure in a production scenario.
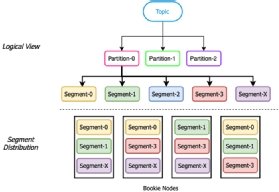
Segment-centric storage in Pulsar
Within a segment-centric storage architecture, such as the one used by Apache Pulsar, partitions are further broken down into segments that are rolled over based on a preconfigured time or size limit. These segments are then evenly distributed across a number of bookies in the storage layer for redundancy and scale.
Using the previous scenario we discussed with Apache Kafka in which one of the bookies disks fills up and can no longer accept incoming data, let's now look at the behavior of Apache Pulsar. Since the partition is further broken down into small segments, there is no need to replicate the content of the entire bookie to the newly added bookie. Instead, Pulsar would continue to write incoming message segments to the remaining bookies with storage capacity until the new bookie is added. At that point, the traffic will instantly and automatically ramp up on new nodes or new partitions, and old data doesn't have be recopied.
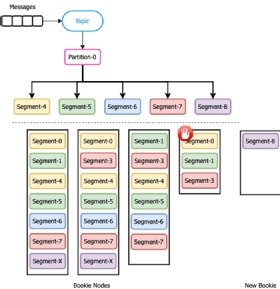
As we can see in Figure 5, during the period when the fourth bookie stopped accepting segments, incoming data segments 4, 5, 6 and 7 were routed to the remaining active bookies. Once the new bookie was added, segments were routed to it automatically. During this entire process, Pulsar experienced no downtime and was able to continue serving producers and consumers. As you can see, Pulsar's storage system is more flexible and scalable in this type of situation.
About the author
David Kjerrumgaard is the director of solution architecture at Streamlio, and a contributor to the Apache Pulsar and Apache NiFi projects.
Dig Deeper on Data warehousing
-
![]()
18 top big data tools and technologies to know about in 2026
By: Mary Pratt
-
![]()
Why Apache Kafka is the AI workflow you (probably) already have
By: Adrian Bridgwater
-
![]()
Confluent launches Private Cloud for simplified, scalable & secured streaming
By: Adrian Bridgwater
-
![]()
How Confluent is maintaining its edge in event streaming
By: Aaron Tan



