The ins and outs of unstructured data protection
Protecting unstructured data requires a few extra considerations for backup admins. Growing storage capacity requirements and regulatory compliance are critical.

Perhaps ironically, unstructured data protection often requires significant structure.
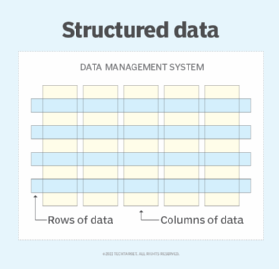
Data exists in two forms: structured and unstructured. Structured data appears in specific formats, such as columns and rows. Unstructured data has no specific format. While the two require different formatting, structured and unstructured data typically require the same backup technologies and processes.
However, there are factors that backup admins must consider when they handle unstructured data. Unstructured data files can be of any size and often can have millions or even billions of bytes per file. Reliable unstructured data protection requires that organizations have both thorough knowledge of the information contained in unstructured data files and a plan for retrieval and security.
Structured vs. unstructured data backup
Structured data typically exists in database management systems and relational database management systems. The organized structure makes it easy for users to retrieve specific data, as well as rearrange it to create additional value.
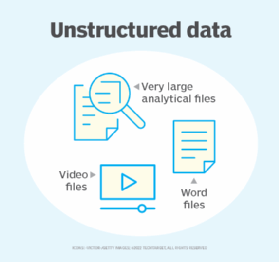
Unstructured data, which makes up the majority of data in use today, can include a wide variety of information types, such as Word documents, Excel spreadsheets, PowerPoint presentations, emails, photos, videos, audio files, social media, logs, sensor data and IoT data.
Unstructured data is typically stored as objects, in that it can be of any type or format. The storage system encapsulates the data with a wrapper, typically metadata for placement in a storage device. Storage and backup admins can use the metadata to identify a file but do not get details about the inner components and where specific items might be located.
An organization might combine unstructured data with structured data components to generate semistructured data to get the benefits of both types. The addition of structured data elements to unstructured data is rapidly growing in popularity in the IT space since it helps identify and increase the value of unstructured data.
Unstructured data protection requires backups that are essentially the same as structured data, with the caveat that the amount of data can affect the process and storage requirements. This may translate into the need for more storage arrays on-site, as well as the expanded use of cloud storage. Depending on the need to retrieve and use unstructured data -- for example, immediately, within a week, within 30 days or over 90 days -- the backups are likely to be on different storage media.
An organization may back up frequently accessed data or data it needs to use in the near future on-site in hard disk or flash drives. By contrast, unstructured data that the business needs less frequently or has archived can go on off-site cloud or tape storage, where retrieval might take more time due to physical distance or lags in cloud performance.
Managing unstructured data
Any user who has permission to access unstructured data files can access and view them. They may need additional permissions and authorizations to modify unstructured data. One of the challenges with unstructured data is to identify what the file contains and when the organization may need it.
An expansive overall data management program is essential to address both structured and unstructured data. Structured data has a relatively easy management process because of the organized format. Finding the business value in unstructured data files requires stronger data management capabilities. Data mining is one process that admins can use to examine large unstructured files and locate useful content.
Specialized software programs are also available to dissect unstructured data files, organize them in a usable way and then manipulate the data in ways that benefit the business. Unstructured data backups should occur regularly to protect prior versions and to be used for future reference. This, of course, affects how much data storage -- whether on-site or remote -- the organization needs.
Protecting unstructured data
Encryption and other techniques can enhance structured data security and protect critical data, such as personal health information or personally identifiable information (PII). Unstructured data can also contain this information, so it is critical to protect it just as thoroughly. However, this type of data can be more challenging to find. The loose format of unstructured data may make it easier to lose track of what information it contains. It is vital for an organization to know what is contained in its unstructured data so it can locate that information when necessary.
Knowledge of unstructured data is important from legal and compliance perspectives. Data privacy regulations, such as the California Consumer Privacy Act and the European Union's GDPR, require that organizations store PII on primary storage. This means that the organization must be able to identify PII and other important data, as well as identify how it is to be used and where it is located. This also applies to backup activities, whether the backups are local or remote.
Considering the explosion of unstructured data and its uses, existing legacy data management techniques may be inadequate. Fortunately, both vendor-developed and open source data management products for unstructured data are available and should be an integral part of data management and data backup programs. Cloud service providers may also have tools for effectively managing unstructured data.
Dig Deeper on Disk-based backup
-
![]()
Is your cloud storage ready for AI workloads?
By: Chris Tozzi
-
![]()
NasuniIQ brings visualisation of massive unstructured datasets
By: Antony Adshead
-
![]()
Cubbit DS3 Composer brings DIY cloud to object storage pool
By: Antony Adshead
-
![]()
Toyota car plant outage shows database capacity planning is vital
By: Antony Adshead