
What is data vaulting and how does it shape modern backups?
Data vaulting methods, such as air gapping and active archives, help isolate and protect data backups from malicious deletion or accidental data loss.

Data vaulting is a form of data isolation that creates a copy of data that is disconnected from the production and core backup environments. Simply put, it is the creation of a backup copy that is inaccessible from what has historically been the core attack surface of enterprise IT environments. In a time when ransomware attacks continue to grow more sophisticated, data vaulting is essential.
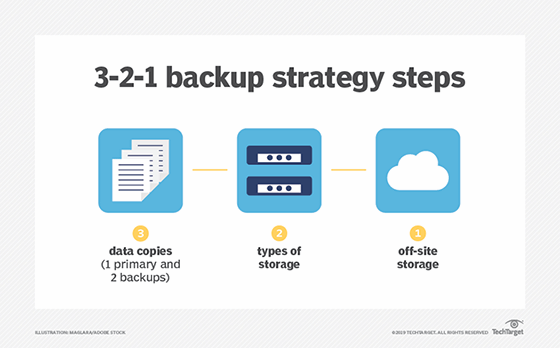
For many customers, data vaulting is necessary to adhere to the 3-2-1 backup rule. A loose definition of this rule states that, to protect data, organizations must have multiple copies of backups stored in multiple places.
There are multiple approaches to data vaulting, and implementation will look different for every organization. Regardless of how an organization incorporates data vaulting, it is a key component to protecting backups today.
Data vaulting methods
From a technical standpoint, there are two core approaches that customers can take to create a data vault. The first is to create an air-gapped copy that has network isolation from the production and the core backup environments. This should mitigate -- and, ideally, eliminate -- external connections and management interfaces that could be compromised by outside attackers.
Air gaps may be physical, where the data copy is located on a physically disconnected storage system that exists within the customer's data center or is hosted off-site or by a third party. Air gaps also may be logical, with the air-gapped data copy located on public cloud storage that is managed either by the customer via data protection software or by a service provider.
The second main approach is to create an active archive that stores data in a read-only format and enables controlled access by applications and users.
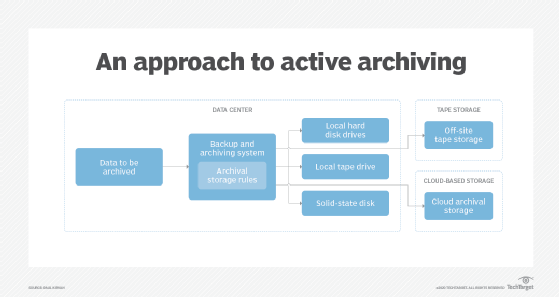
According to IT analyst firm Evaluator Group, there are a few table-stakes capabilities that organizations must include in data vault implementation. These include the ability to apply immutability and write once, read many designations alongside automated control over data copy and movement procedures.
To avoid malicious penetration of the environment, the data vault should have access control capabilities, including security credentialing, such as multifactor authentication. Monitoring and reporting are critical to ensure the health and availability of backups, as well as uncovering potential breaches. Organizations may use machine learning and analytics to detect signs of penetration or corruption and conduct security checks to validate data integrity. Automated recovery from the vault helps to securely restore operations as quickly as possible.
Why data vaulting?
These days, the major draw to implement a data vault is for resiliency against ransomware. Increasingly often, ransomware attackers are targeting primary backup environments. They understand that the customer is more likely to pay the ransom if it does not have backups to recover from. Often these attacks are sleepers, designed to lay dormant for a period of time to avoid detection and exceed the ability to restore data to a near-term recovery point.
Another challenge is that attackers are going a step further with data extortion, threatening to expose and sell data if the ransom is not paid. For these reasons, it is critical to take all measures possible to inhibit attackers from accessing backup copies in the first place. A data vault becomes an important safeguard from this standpoint because, unlike the primary backup environment, it is not inherently designed for accessibility in order to facilitate recovery.







