Linux clusters vs. grids
Can Linux clusters outperform grid computing? Expert Ken Milberg compares them -- covering Beowulf, HPC, Linux Virtual Server and the Globus Toolkit for grids -- and chooses a winner.
When most people think of Linux clusters, they think they are used for load-balancing purposes only. Yet, that's not the only functionality that makes Linux clusters on par with mainframes or high-end, mid-range Unix servers for many jobs. In this tip, I'll examine Linux cluster options and similar server approaches, like grid computing.
First, let me define the basic cluster, which is a server farm that acts as a front-end and distributes data to backend servers. Some types of clusters are high-availability (HA) clusters and high-performance computing (HPC) clusters. HA clusters are deployed for the purpose of improving accessibility to the application, in the event of a hardware failure. They do this by incorporating redundant nodes that provide the capability. HPC clusters are used to increase performance by splitting tasks across many different nodes in a cluster. They are typically used in scientific computing.
Grids vs. clusters
So what makes grid clusters different from grid computing? The easiest way to set grid computing apart may be to say that a grid is composed of many clusters, unlike a typical cluster, which is one set of nodes in one location. Essentially, the grid connects these clusters since they do not actually fully trust one another. They operate more like a network of systems, rather than one server, and work best in environments that actually do not have to share data during the computation of processes. Clusters manage the allocation of these jobs and systems.
Presently, there are many popular grids and clusters available for Linux. Perhaps one of the most well-known cluster configurations is the Beowulf cluster. The Beowulf cluster is a group of computers running Linux, or other Unix-like operating systems such as BSD, that are networked and contain shared libraries. The latter allows processing to be shared by the clustered nodes. Unlike a cluster of workstations, the Beowulf cluster behaves more like a single computer. It is not any one software package, but the technology which allow Linux boxes to form a type of supercomputer. The beauty of the Beowulf cluster comes from its inherent simplicity. All of it nodes are dedicated to the cluster and server no other purpose. The nodes all run open source software and are used for High-Performance Computing (HPC).
Load-balancing and high-availability clusters
How does this compare to an high-availabilty (HA) cluster? Let's discuss the Linux-HA project. The Linux-HA project essentially offers an availability solution for Linux-based systems. The Linux-HA project's Heartbeat software is used to manage its high-availability, and can be used to build either large or small clusters. Heartbeat implements serial and UDP heartbeats with IP address takeover, which includes a resource model. There are several noteworthy features of Heartbeat:
- Resources can be restarted or moved to any node on a failure.
- Heartbeat allows users to remove failed nodes from the cluster, while also providing a GUI to control and monitor resources.
- It provides special resource scripts for Apache, Oracle and other applications that assist with the failover processes.
Unix brethren should think about Veritas Clustered Services or IBM's HACMP, when thinking Linux-HA.
Possibly the best example of load balancing cluster solutions is Linux Virtual Server. Linux Virtual Server is a scalable server built atop a cluster of real servers with the load balancer running on Linux. The architecture is transparent and users run Linux Virtual Server as if it was on one high-performance virtual server. In this respect, it sounds much like the Beowulf cluster, with a load balancer thrown in for good measure.
One can use IP Virtual Server (IPVS) to build the load balancer. IPVS implements transport-layer load balancing inside the Linux kernel (a part of the Linux kernel since 2.4). When it does this, it directs requests for TCP/IP traffic to the real servers, while making it appear that the virtual services reside on one box, or IP address. This can be done with NAT, IP tunneling or direct routing.
What distinguishes LVS from Beowulf, is that Beowulf is a group of networked computers, each helping the other to calculate data. With LVS, these clustered computers have no real knowledge of any of the servers in the LVS; all they know about are the client connections. To reiterate, LVS is a load balancer which allows multiple requests to be serviced among a set of boxes.
There are also hybrid solutions out there. For instance, Ultra Monkey, is an example of a project whose purpose is to create a load balanced, high-availability solution. It uses the fast load balancing of the Linux Virtual Server and the high-availability provided by the Linux-HA project. Like the other projects mentioned, all software in Ultra-Monkey is open source and there is no customer kernel required to run the system.
Grid clusters and the Globus Toolkit
Now, we'll discuss grid clusters. The Globus Alliance is a community of organizations and people who develop the grid technologies. The grid technologies enable us to share the database, storage and computers across geographic sites and smaller clustered systems. The Globus Toolkit is open source software that is used to help build grid systems.
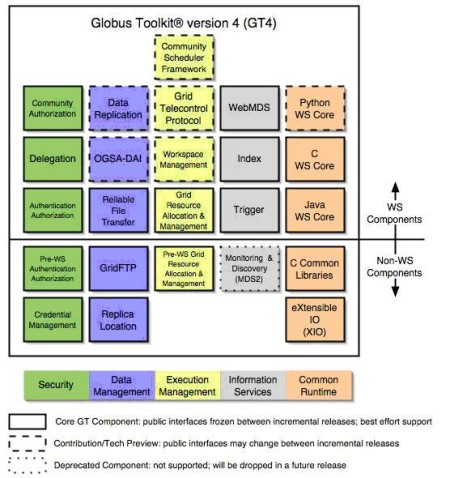
The toolkit contains software services and libraries for resource monitoring, discovery, management, security and file management, resource management, data management, communication, fault detection and portability. The toolkit is packaged as a set of components that can be used either independently or together to allow users to develop applications. The core services of the toolkit permit people to access remote resources as if they were located within their own computer.
There are plenty of examples of grid systems, many of which are based on the Globus Toolkit. IBM defines grid computing as "….all or some of a group of computers, servers and storage across an enterprise, virtualized as one large computing system". As a major user of grid technology, IBM's intraGrid, is actually based on the Globus Toolkit. It is a research and development grid that allows IBM to leverage many worldwide assets. Their WebSphere-based portal also uses the Globus Java CoG Kit to pre-select candidate queues for submitting simulations, based on cluster loads and job characteristics. IBM also uses grid technology for tying their design centers together for e-business on demand. This allows IBM to manage multiple entities as a single entity.
It is clear that we are much further along with general clustering than with true grid systems. Grid systems are inherently much more complicated, as they involve the networking of clustered systems into powerful types of information engines.
What did you think of this tip? Email us and let us know. Don't forget to check out our blog, the Enterprise Linux Log.






