AI brings storage admin challenges of trust, tech and liability
Storage admins should stock up on aspirin as the continued enterprise AI adoption throughout 2026 will continue to create new challenges in trust, technology and legal liability.
Storage and data management teams are dealing with an onslaught of challenges as AI adoption increases in the enterprise.
Organizations are interested in using AI applications that draw from unstructured data stores in complex ways, such as agentic AI for multistep decision-making processes, according to industry experts, vendors and practitioners. However, implementing those lofty automation goals that use years of company-compiled data involves three major challenges: data trust, storage technologies and organizational liability.
The overall goal with overlaying AI on top of stored data is to bring machine-readable order to an inherently messy and human decision-making process, said Sanjeev Mohan, founder and principal analyst at SanjMo.
The path to that goal will vary widely depending on an organization's needs, desires and funding, Mohan said.
"The goal is to take unstructured data and make structure out of it," he said.
Trust
Most organizations should be bracing for a "tsunami" of data to process, according to Christophe Bertrand and Scott Hebner, analysts at TheCube Research, in a recent webinar titled "Governance and Compliance in the Age of Data and AI."
Agentic AI implementations, which use a collection of AI services to make decisions based on training data and prior decisions, will create a massive amount of new data if used in conjunction with generative AI, Bertrand said.
Organizations will need to not only find ways of backing up and storing this data, but also find ways to cull bad information or decisions at a rate that human intelligence likely can't keep up with.
When you look at this tsunami of data, it's no wonder nobody is going to trust this stuff.
Christophe BertrandAnalyst, TheCube Research
"When you look at this tsunami of data, it's no wonder nobody is going to trust this stuff," Bertrand said in the webinar. "We have a compliance issue because of the data issue, and now we have an agent issue that's going to compound everything else."
Data spawned from agentic decision trees could also create international liabilities around what data is ingested into these systems, especially among nations with stronger data privacy laws than the U.S., like the EU's GDPR.
"You can deregulate all you want within your own state [or] your own country, but you're going to be bound by other countries' regulations, and that's going to be what prevails," Bertrand said.
As an example, the EU also has an act regulating AI models and their level of risk. Data sovereignty is also becoming a large concern.
Organizations that have fully vetted and trust their own in-house data might still run into issues down the line using popular large language model (LLM) services, SaaS AI services or even their storage partners, he added.
The tsunami of data that AI systems create must be generated, processed, converted and stored, all of which must comply with the laws of the country in which the data is generated. This also increases a system's complexity, making it more difficult for auditors.
Many IT teams can be lax about their enforcement and backup of SaaS data, which can be compromised without their knowledge through attacks on the provider or using tools that might violate an organization's own standards and expectations.
"If you don't know 100% of your data, you don't own it," Bertrand said.
Ultimately, the volume of junk or unnecessary data will require an organization's leadership to establish strong data management and control policies, said Matt McVaney, who was chief revenue officer at BombBomb and is now an independent operating advisor.
AI needs data that matches an organization's overall mission for its customers, McVaney said during an episode of InformationWeek's That DOS Won't Huntpodcast.
Whether that focuses on AI entirely for revenue generation or other purposes, having data that matches customer patterns and needs should be priority No. 1 in any AI data strategy.
"Data is not useful whatsoever unless it drives insights, decisions and actions," McVaney said. "You have to understand the customers, you have to understand their behaviors at a really microscopic layer. If you know what they want or need, that determines everything else thereafter."
AI data customers should also make sure that the technology they're purchasing aligns with their own mission and specific needs around performance, price and capability, said Greg Statton, vice president of AI solutions at Cohesity, a SaaS backup vendor that also sells AI services.
He said standards to which vendors hold themselves accountable might not align with customers or competitors, so buyers should keep their own expectations or vetting standards from third parties, like NIST, in mind.
"As the excitement rises around the new model, agentic framework or standard, people are going to realize all of this won't matter unless the data is there and the data is good," Statton said. "There are too many standards for [the] evaluation of data and too many ways for organizations to have wiggle room in their evaluation outputs. AI tools and applications are never going to be perfect -- never ever."
Find the right technology stack
The next major issue facing storage and data management teams is finding the ideal technology stack to ensure that data from storage can be discovered, prepped and delivered to a variety of AI services.
Most storage and data management platforms have settled on using metadata as the connective tissue for data across various services and processes, such as vectorization, data lakes and agentic AI, according to Mohan.
Although metadata exists within almost all data, created either at the time of data creation or added through software after the fact, there is a lack of standardization across vendors and technologies, he said.
Storage systems might use their own form of metadata, which is then ingested into either unstructured or semistructured data lakes and services such as Kafka, which are then further cataloged in AI processes, Mohan said. Having a formalized tagging standard and technology stack prepared in advance can help mitigate some of those challenges.
"Dozens of these products are capturing some metadata to do their job, but it's an overlap," he said.
The next major challenge facing storage admins will be developing around the black box nature of proprietary and popular LLM services, Hebner said in a follow-up interview with Informa TechTarget.
Although open source LLMs do exist, many organizations opt for proprietary models like Microsoft Copilot, which uses Microsoft's LLM technology, Prometheus. Either for protecting trade secrets or other possibly legal reasons, proprietary models are not viewable like open source variants, but offer faster onboarding and implementation into enterprise workflows.
That approach creates a liability for organizations using such technology, as implementing AI tools without fully understanding every aspect of an agent's decision-making process could create new risks, Hebner said.
"Because of the way they operate as black boxes, they're not really able to explain the rationale of what they're telling you," he said.
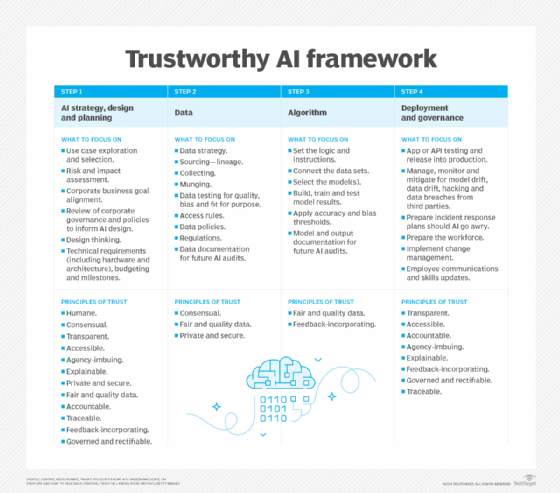
What a trustworthy AI framework should look like when not in a black box format.
These services used without official permission, sometimes called shadow AI, could also pose risks to data sovereignty and security.
Storage services have already been moving toward more abstraction in operation, primarily through the pay-as-you-go managed service model of the cloud, said Mike Matchett, founder and principal analyst at Small World Big Data.
This model will similarly arrive for AI services using storage to create new, initially unknown bottlenecks about how to best optimize hardware and infrastructure, Matchett said. Storage administrators in the future might not actually be all that concerned with the underlying technology over the results, but ignorance about the components and capabilities could create inefficiencies with overspending or underprovisioning.
"Ideally, managing storage at a lower layer becomes built-in," he said. "But every time that level of advancement happens, you gain a lot of efficiencies at the higher level and lose a lot at the lower level. You're paying for what you use, but you have no control over how you use it."
Matchett echoed Hebner's concerns about the black box approach to AI, noting that organizations will need to get comfortable with the loss of visibility in AI decision-making processes.
"You have an agentic AI layer making these decisions that's invisible to the user," he said. "We've ceded all that to the agent. We no longer have the visibility."
Possible liability?
A blank check and the fastest GPUs the cloud can beam down won't absolve an IT employee of legal responsibilities and liabilities surrounding AI. Even AI industry leaders like Google are bracing for legal blowback with indemnification offerings.
AI adoption byproducts like vibe coding have already merged together what were previously several different jobs and responsibilities, letting one employee become coder, designer, UX specialist and more, Mohan said. As these tools evolve and become a larger part of the enterprise, organizations will need to consider who AI agents or employee-generated applications report to, how they're managed, and what their data policy is.
"The steps don't change, [but] the speed we're doing it has changed," Mohan said. "The question is now who owns [an AI] agent and who is using this agent, [as] you've done a little bit of everything."
Agentic AI for expediting automation will become a defining use of enterprise AI in the coming years, Hebner said. Market sentiments reflect his thinking, as a January 2025 survey from Omdia, a division of Informa TechTarget, found that 49% of 653 respondents consider process automation cost savings a pivotal factor in determining AI's effectiveness.
Organizations that use agents and the users who build them will need to understand how each agent comes to a decision and make sure that those paths are documented, he said.
"We're in a changing environment [where] GenAI has largely been used to automate repetitive tasks [for] more of a productivity use case," Hebner said. "More enterprises are reaching a point where they want to use AI for an action path."
Most of this AI responsibility will fall on executive leadership rather than IT employees, Bertrand said in a follow-up interview. AI vision, missions and importance must be dictated and expounded by an organization's top brass rather than individual employees.
"The storage admin is not at the top of the pyramid -- the storage admin is really at the execution level," he said. "While they have a lot of responsibility, [the] governance piece has to come from the top. [Executives] need to get more specific on use cases, capabilities and what [an organization's AI] success actually means."
Those leaders will also need to make sure that they're ready to make a hard decision should a crisis around bad data used in AI arise, McVaney said.
"Ultimately, somebody has to make a call where [data's] going to go and what it's going to be," he said. "You can't have it be a case where there's a battle in the conference room."