
your123 - stock.adobe.com
Minding the gap between prototype and production
Five software releases targeting one problem: getting from "it works" to deployed.

Developers build features. Platform engineers build the environments, guardrails and automation that these features must survive in. And in between sits DevOps, trying to keep delivery moving while security reviews, compliance signoffs, infrastructure handoffs and configuration drift quietly slow everything down.
This month's releases from GitLab, Dynatrace, Red Hat, SUSE and Nutanix all target that gap. Not by adding more features, but by tightening the connective tissue between developer workflows and the platform guardrails they run on.
The common thread is operational friction reduction: context-aware automation, pre-validated stacks and governance embedded directly into the infrastructure rather than enforced through tickets and tribal knowledge. The seemingly mundane work that determines whether a two-week project actually ships or quietly stretches into a multi-quarter ordeal.
GitLab Duo Agent Platform: Context is everything
Consider this scenario: A SaaS company starts seeing random failures in its software build process for a core API. About a third of builds fail during testing, with no obvious pattern. The usual response? Engineers burn hours digging through logs and retrying builds, hoping to spot something useful.
GitLab's root cause analysis agent takes a different approach. Instead of treating each failure in isolation, it connects the dots. It traces the problem back to a change made a few days earlier in a shared infrastructure setup. That change quietly adjusted how much memory different components are allowed to use.
The result: the API's test environment is now competing for memory with a newly added monitoring component, causing tests to fail at random. The agent pinpoints the conflict, proposes a corrected configuration, links the issue back to the original change for context and alerts the platform team lead -- before the problem becomes a multi-day investigation.
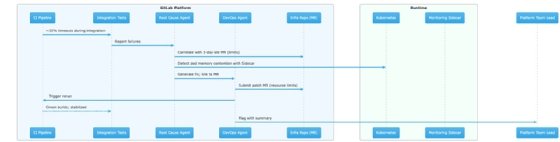
The GitLab Duo Agent Platform aims to address something that's been measured repeatedly but rarely solved: developers spend only a fraction of their time actually coding. The rest goes to defining infrastructure, wrangling Kubernetes, writing deployment scripts, conducting root-cause analysis and coordinating across teams. GitLab's approach is to put agents on these overhead tasks and give them access to the full project context, including past issues, merge requests, pipelines, security findings and compliance requirements.
What makes this interesting is how it complements rather than competes with IDE-centric frameworks like Cursor, Copilot and Windsurf. Those tools excel at code-level assistance. GitLab adds higher-level business context: why a feature is being developed, what security vulnerabilities were flagged during the last sprint and which deployment patterns have historically caused pipeline failures. The natural next step would be integration between these layers, allowing DevOps agents to delegate development tasks to IDE agents and vice versa.
GitLab's single-platform strategy pays a new dividend: its AI agents can see the full project context, issues, pipelines, security findings and deployment history that siloed tools can't easily access.
Dynatrace acquires DevCycle: Observability that takes action
Dynatrace acquired DevCycle to add feature flag management to its observability platform. Here's what that enables:
A new recommendation engine feature rolls out to 5% of users. Within 40 minutes, Dynatrace correlates a memory consumption pattern -- heap usage climbing linearly rather than stabilizing. Before the container hits out of memory limits and starts crashing -- which would trigger traditional alerts -- the platform automatically rolls back the feature flag to 0% and tags the deployment for review. The 95% of users on the stable path never experience degradation.
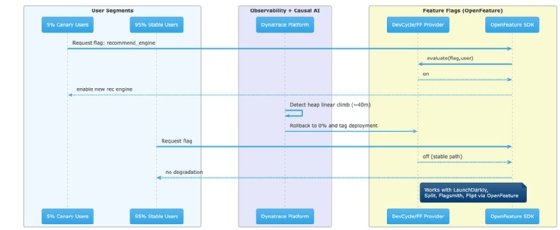
Feature flags are a great mechanism for tightening feedback loops because they tie a very specific action -- the release of a feature -- to its direct correlation with measurable outcomes: latency, error rates, conversion and revenue. That attribution is the missing link that lets observability move from "alerting humans to problems" to "resolving them automatically."
DevCycle's support for the OpenFeature standard matters here. It means the platform can connect to any compliant feature flagging system -- LaunchDarkly, Split/Harness, Flagsmith, Flipt -- giving teams flexibility without rewriting instrumentation code. DevCycle is less about simple feature flagging and more about correlating releases with downstream business impact. That's what Dynatrace's causal AI engine needs to take action with confidence about blast radius and expected outcome.
Red Hat Enterprise Linux for Nvidia: Making AI workloads boring
A financial services firm runs inference workloads across multiple data centers using a mix of Nvidia GPUs. Each cluster was configured by different teams at different times -- multiple slightly different driver versions, multiple different container runtime configurations, multiple different approaches to GPU memory management. When a new model deployment causes memory fragmentation issues in one data center, the team can't reproduce it elsewhere. They can't even determine whether this is a model problem, a driver problem or configuration drift.
This is the "AI works in the lab" versus "AI runs in production" gap that is frequently stalling enterprise AI adoption. Most organizations have spent years building operational discipline around their core infrastructure -- change management, security baselines, lifecycle support, validated configurations. AI workloads have largely bypassed all of that, treated as special projects with bespoke configurations managed by teams who optimize for model performance rather than operational sustainability.
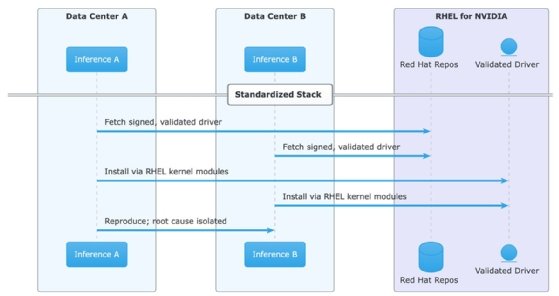
Red Hat Enterprise Linux for Nvidia brings AI infrastructure into the same governance model enterprises already use for everything else. Validated drivers distributed through Red Hat repositories mean security teams can actually approve them. Day-zero support for new Nvidia architectures means organizations aren't waiting months after hardware delivery for a supported software stack. Confidential computing support means regulated industries can run AI workloads with cryptographic attestation.
The goal here isn't faster AI. It's AI that can make it through enterprise procurement, security review and change management without becoming a multi-year infrastructure project.
SUSE on AWS European Sovereign Cloud: Sovereignty without starting over
A defense contractor runs mission-critical simulation workloads that require both significant compute scale and strict data-residency controls. Their current setup splits the difference awkwardly: sensitive data stays on-premises in a private data center, while less sensitive compute jobs burst to the public cloud. This creates a constant classification exercise that slows every project. Engineers spend more time arguing about what data can touch which environment than actually running simulations.
The AWS European Sovereign Cloud eliminates that split. The contractor can run its entire workload stack -- including SUSE Linux environments validated for its industry -- on infrastructure with no dependencies on non-EU systems. In extreme scenarios, authorized EU-resident AWS employees have independent access to source code replicas to maintain operations even if communications with the rest of AWS are disrupted. The sovereignty controls are baked into the infrastructure, not bolted on as policy exceptions.
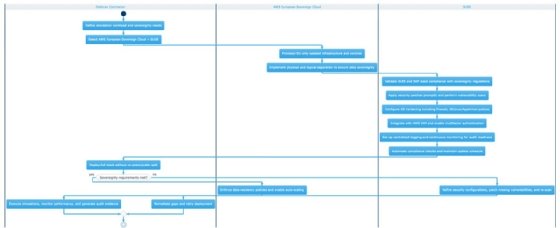
European enterprises moved to the public cloud for obvious reasons: scalability, operational efficiency and access to managed services. But the regulatory environment has shifted faster than their architectures. GDPR was the starting point; the Network and Information Security Directive 2, the Digital Operational Resilience Act and the EU Cloud Sovereignty Framework have raised the bar further. Beyond compliance, there's growing unease about dependency on infrastructure that could, theoretically, be subject to foreign jurisdiction.
SUSE's role as a launch partner of AWS European Sovereign Cloud matters because sovereignty isn't just about where the data center sits, but about the full stack. Organizations running SAP workloads on SUSE Linux Enterprise Server need assurance that their entire environment meets sovereignty requirements, not just the hypervisor layer. The alternative -- standing up sovereign infrastructure from scratch with different tooling -- is exactly the friction that keeps sensitive workloads trapped on aging on-premises hardware.
Nutanix Enterprise AI: Making AI workloads look like every other workload
A regional bank wants to deploy an agentic AI system that handles customer service inquiries -- pulling context from transaction history, account status and compliance rules to resolve issues without human escalation. The AI team builds a working prototype on a cloud GPU instance in three weeks. Then reality sets in: compliance requires that customer data never leave the bank's on-premises environment, security needs FIPS-validated cryptography and the infrastructure team has no experience running GPU workloads on their existing clusters. The project stalls for six months while teams argue about architecture.
This pattern -- AI prototype to production purgatory -- has a specific shape for most enterprises. It's not a technology problem; it's an operations problem. Data science teams can spin up impressive demos on cloud GPU instances, but moving those workloads into environments that meet security, compliance and operational requirements requires a different skill set entirely. Most organizations don't have Kubernetes experts who also understand GPU scheduling, model serving and inference optimization.
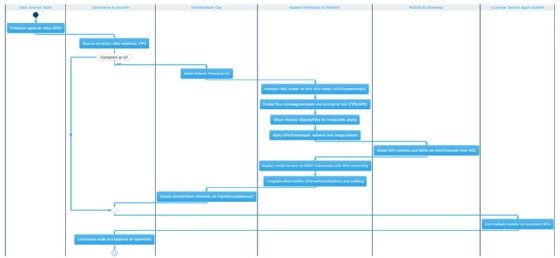
Nutanix's approach with its Enterprise AI platform is to make AI workloads look like every other enterprise workload: something that runs on infrastructure you already manage, with tools you already know, governed by policies you already enforce. The Nvidia AI Enterprise integration -- NIM microservices for optimized inference, NeMo for model customization -- provides the AI-specific capabilities, but packaged to run on any CNCF-certified Kubernetes environment. Organizations can deploy inference endpoints at the edge, in their data centers or in the public cloud using the same operational model.
For agentic workflows specifically, this matters because agents typically need access to multiple models -- a reasoning model, a retrieval model and maybe a code-generation model -- and managing those as discrete services with consistent APIs simplifies orchestration considerably.
The common thread
The unifying theme across these releases is a clear acknowledgment that enterprise friction is no longer a technology gap. Enterprises aren't blocked by a lack of capable models, observability platforms or sovereignty options. Those pieces largely exist. The real bottleneck has shifted to how these capabilities are operationalized, integrated and governed at scale.
Torsten Volk is principal analyst at Omdia covering application modernization, cloud-native applications, DevOps, hybrid cloud and observability.
Omdia is a division of Informa TechTarget. Its analysts have business relationships with technology vendors.
Dig Deeper on DevOps
-
![]()
GitLab CIO rejects ‘tokenmaxxing’ as it rebuilds work around agentic AI
By: Aaron Tan
-
![]()
KubeCon EU 2026: AI tightens the dev-prod loop
By: Torsten Volk
-
![]()
Dynatrace bets on causal intelligence for AI observability
By: Torsten Volk
-
![]()
Dynatrace AI agents draw on new observability integrations
By: Beth Pariseau



