
Getty Images/iStockphoto
Compare running Kubernetes on VMs vs. bare-metal servers
Planning to run a cloud-native application with Kubernetes? Compare the advantages and drawbacks of deployments on VMs and physical servers.

When running cloud-native applications orchestrated with Kubernetes, organizations must decide whether their deployments should use physical servers or VMs.
There's no universal best choice -- the answer depends on factors such as scale, costs, resources and performance needs. Let's explore the pros and cons of each deployment method.
Overhead and performance
Deploying cloud-native applications with Kubernetes on physical servers -- also known as bare-metal servers -- eliminates the overhead associated with a hypervisor. In a bare-metal deployment, all hardware resources are devoted solely to the containerized workloads. Every CPU cycle goes to business applications. In addition, network packets and storage reads and writes are processed directly without hypervisor intervention.
But this advantage of bare-metal servers doesn't necessarily rule out VM deployments. Advances in VM optimization over the past 20 years have significantly reduced the overhead required for today's hypervisors. Organizations might find that the flexibility of virtualized platforms outweighs the small amount of overhead hypervisors add.
VMware, for example, claims that its vSphere 7 server virtualization software can deliver 8% better performance than a bare-metal server when running Kubernetes workloads natively on an ESXi hypervisor. The ESXi CPU scheduler ensures that pods' memory accesses are within their nonuniform memory access domains, which VMware claims improves localization compared with Linux's process scheduler.
Running Kubernetes in VMs also enables IT teams to choose multiple node sizes for different deployment types. In a bare-metal deployment, the entire server has resource groups available to the running pods. On VMs, it's simpler to contain resources within each VM, and hypervisors usually manage resources well across the environment. On the other hand, when all workloads are running in Kubernetes on bare-metal nodes and there are no other VM-hosted workloads to consider, Kubernetes offers more fine-grained control down to the pod level.
Deployment and manageability
A clear point in favor of VMs is their ease of deployment. Although VM platforms require the additional work to install both a hypervisor and VMs on the underlying hardware, hypervisor deployments are usually quick, and updates are less frequent than for many other OSes.
Once hypervisors are in place, VM deployments are independent from hardware. When hardware is added, all VMs remain intact and can move easily between hypervisors. This simplifies platform management and eliminates workload downtime during hardware maintenance.
VMs can deploy as Kubernetes nodes using templates with a preinstalled Linux OS. IT teams willing to pay a premium for simplicity can purchase a license for vSphere with VMware Tanzu, which enables pods to run directly on ESXi. This is a useful option for organizations that already run vSphere with VMs and want to add Kubernetes workloads to their environment.
This doesn't create a fully compliant Kubernetes cluster, as certain features -- such as customized resources and third-party plugins -- can't be realized on the platform. However, vSphere with VMware Tanzu does enable fully compatible Kubernetes clusters to deploy inside VMs on top of ESXi as Linux machines, making Kubernetes clusters easily scalable.
The following image shows a Kubernetes deployment with three master nodes and 12 worker nodes controlled through the vSphere Client.
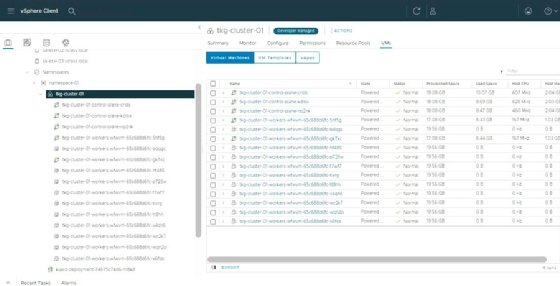
For organizations starting out with Kubernetes, running cloud-native applications in VMs alongside existing workloads seems logical: There's no need to purchase dedicated hardware resources, and new hardware added to the platform can be used for all workload types. With bare-metal servers, just Kubernetes with containers runs on those hosts.
Another benefit of deploying Kubernetes in VMs is that the administrators managing the hypervisor can become familiar with the new platform over time, rather than get started with a full-blown bare-metal deployment from day one.
High availability
Hypervisors protect the VMs and can be restarted quickly and automatically on another host in case of a failure. But IT teams should be cautious when placing multiple VMs on the same hypervisor: When that machine fails, the consequences are much more serious compared with losing a single bare-metal host, as more workloads are lost. This limitation can usually be overcome with anti-affinity rules that separate VMs on different hosts.
To further ensure high availability, configure the environment to avoid trying to overcome failures in both the Kubernetes and VM layers. In the event of a failure, only one platform at a time should attempt to get workloads up and running again.
Large-scale deployments benefit from bare-metal servers
Kubernetes originated within Google, which runs data centers at a huge scale. Most organizations don't handle deployments of that size, but when Kubernetes forms the heart of an entire infrastructure on hundreds or even thousands of hosts, bare-metal servers are likely the best choice.
Bare-metal servers eliminate the costs associated with licensing hypervisors. Organizations with large-scale deployments also typically have on board skilled administrators who are dedicated to working with a single platform.
Once large numbers of bare-metal servers are in place, Kubernetes can balance workloads on those hosts and handle failures. This homogeneous environment is usually simpler to manage. In a more heterogeneous environment, running Kubernetes in VMs makes more sense than integrating it into the existing environment.







