Prioritizing alerts with server monitoring tools
Setting and prioritizing alerts with server monitoring tools can help an administrator respond quickly to critical problems without being bothered by insignificant alarms.

Today’s servers are equipped with a dizzying array of sensors and can produce an incredible variety of alerts. However, one important lesson that administrators learn early on is that alerts are not created equal--not every alert that server monitoring tools generate is actually important. If servers are configured to notify you every time an alert is triggered, you would receive so many nuisance notifications that truly important alerts might go unnoticed. This tip will help administrators determine which alerts are really important and how they want server monitoring tools to notify them of such alerts.
A note on setting up and configuring alerts
Before we get started, I want to point out that there really is no right or wrong way to configure alerts. The recommendations in this tip are based on my two decades of IT experience, but ultimately, they boil down to personal preference. While I hope that you will find my recommendations to be helpful, each administrator needs to configure server alerts in a way that meets their own organization’s unique requirements.
The other thing to point out is that there are many different ways an administrator can generate alerts. Some servers can generate alerts at the hardware level. These capabilities can be helpful, but they are far from being the only available alerting mechanism. Server monitoring tools from server vendors can provide a wealth of information, as can OS-level server monitoring tools, such as Microsoft’s System Center Operations Manager. Because there are so many different options for server monitoring and alerting, I am going to take a generalized approach to the subject rather than focusing on specific server monitoring tools.
Prioritizing server alerts
The key to effective server monitoring is to prioritize the alerts that server monitoring tools generate. I recommend classifying each type of alert as high, medium or low priority.
I like to treat high-priority alerts as anything that is absolutely critical. For example, running out of disk space on a server would be a critical event. The failure of a clustered application server would also be a critical event.
Medium-priority alerts are a bit more difficult to define. The events that I consider medium priority would likely be defined as high priority by some organizations. I tend to treat an event as being medium priority if the condition that caused the alert does not actually result in an outage. For example, if one node in a cluster drops offline for an unknown reason, but the cluster as a whole continues to function, then I treat that as a medium priority. Of course, this has a lot to do with the type of environment that I work in. I have worked for large companies that would treat a cluster node failure as a critical event.
If you happen to work for an organization that cannot tolerate any downtime, then it may be wise to configure these types of alerts based on whether or not a potential single point of failure exists. For example, suppose that you have a RAID array that can handle the failure of two disks without dropping offline. If a single disk in the array were to fail, then you might treat the event as a medium-priority alert since the array can still tolerate another disk failure without data loss. However, if two disks were to fail, then you could treat that as a high priority, because the failure of an additional disk would bring down the entire array.
While I tend to think that this is a great way to prioritize alerts, it is much more difficult to configure alerts based on the number of components that have failed than it is to simply trigger an alert when a failure occurs. Depending on the type of monitoring that you are doing, and the features available in your particular monitoring software, setting up this type of alert might not even be an option.
Configuring the alerting mechanism
Once you have determined how the various types of alerts should be classified, you will need to decide how you want to be notified of alerts. My personal preference is to have server monitoring tools send high-priority alerts to my cell phone via a text message. I have my cell phone on me most of the time, so sending critical alerts to my phone is the best way to make sure that I will receive the alert as quickly as possible.
Since medium-priority alerts are important, but not absolutely critical, I prefer to send those alerts to my e-mail. As you can see in Figure A, Windows Server has native e-mail alerting capabilities, which means that you can easily send e-mail alerts based on any event that may occur within the operating system.
Figure A
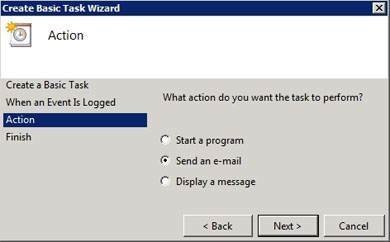
Windows is able to natively send e-mail alerts.
I tend to check my e-mail several times a day, which means that an alert sent to my email will not go unnoticed, but I probably won’t see it as quickly as I would if the alert were sent to my cell phone. This is an important distinction, because the last thing that I want to be bothered with is a non-critical server alert if I am out with friends on the weekend. Of course, this is just one example of how alerts could be sent. Many other options exist. For example, a company named Server Density offers an iPhone server monitoring app with full alerting support.
Clearly, the subject of what constitutes a high-priority alert is certainly open for debate. One last thing to think about, however, is that high-priority alerts may not always be tied to system failures. For example, most servers can trigger an alert whenever the system case is opened. If nobody is supposed to be opening server cases except for you, then a case alarm could very well be a high-priority alert. Likewise, an excessive temperature alert could also be considered to be high priority, because if the server gets too hot, it will eventually lead to a shutdown.
About the author: Brien Posey is a seven time Microsoft MVP with two decades of IT experience. During that time he has published many thousands of articles and has written or contributed to dozens of IT books. Prior to becoming a freelance writer, Posey served as CIO for a national chain of hospitals and healthcare facilities. He has also worked as a network administrator for some of the nation’s largest insurance companies and for the Department of Defense at Fort Knox.






