IT incident management
What is IT incident management?
IT incident management is a component of IT service management (ITSM) that aims to rapidly restore services to normal following an incident while minimizing adverse effects on the business.
An incident is an unexpected event that disrupts the normal operation of an IT service. The IT incident management process begins when an end user reports an issue and concludes when a service desk or help desk team member resolves it.
IT incident management helps keep an organization prepared for unexpected hardware, software and security failings and reduces the duration and severity of disruptions from these events. It can follow an established ITSM framework, such as the Information Technology Infrastructure Library (ITIL) or COBIT, short for Control Objectives for Information and Related Technologies. It can also be based on a combination of guidelines and best practices established over time.
Types of incidents
Incidents are generally categorized using low, medium and high priority:
- Low-priority incidents don’t interrupt end users, who typically can complete work despite the issue.
- Medium-priority incidents are issues that affect end users, but the service disruption is either slight or brief.
- High-priority incidents are issues that will affect large amounts of end users and prevent a system from functioning properly.
Incidents are classed as hardware, software or security, although a performance issue can often result from any combination of these areas. Software incidents typically include service availability problems or application bugs. Hardware incidents typically include downed or limited resources, network issues or other system outages. Security incidents encompass attempted and active threats intended to compromise or breach data. Unauthorized access to personally identifiable information and records is a security issue, for example.
Roles in incident management
IT incident management typically consists of three tiers of support, often organized within the help desk or service desk structure. Most organizations use a support system, such as a ticketing system, for categorizing and prioritizing incidents. IT staff respond to each incident according to its prioritization level.
Common roles within the sphere of IT incident management include the following:
- Incident manager. An incident manager enforces the proper incident response and management processes across IT support and IT service delivery teams. This person can be involved in the organization's choice of ITSM framework. They work to improve how the company prevents and handles incidents over time, through risk mitigation strategies and ongoing process improvements. The incident manager acts as a communication bridge between end users and technical specialists during disruptions, such as an email outage. The incident manager, along with the service desk staff, produces incident reports for critical business and IT services and they might lead a post-mortem on major incidents. They also maintain a knowledge base of problems and incidents.
- Service desk manager. The service desk manager frequently participates in the incident management process, primarily serving as first-line support. Their duties include incident logging and categorizing the incidents. In small and medium-sized organizations, service desk managers sometimes take on the incident manager role.
- Service desk analysts. Service desk analysts handle initial incident reports, log incidents and provide initial diagnosis and resolution. They also escalate issues as needed.
- Level 1 support. Level 1 support typically provides basic support or assistance, such as password resetting or computer troubleshooting. Level 1 support involves incident identification, incident prioritization, logging and categorization, incident resolution and escalation to Level 2 support when appropriate. It involves technical staff trained to solve common incidents and fulfill basic service requests.
- Level 2 support. Level 2 support goes through a similar process for more complex issues that need more training, skill or security access to complete. Level 2 support includes IT staff with specific knowledge of the system in question.
- Level 3 support. Major incidents are given Level 3 support. This category includes incidents that disrupt a business's operation, are marked as a high priority and require an immediate response. Level 3 support team members are generally specialists in the subject matter of the incident. For example, a Level 3 support team could include the chief architect and engineers who work on the product or service's daily operation and maintenance.
- Facilities manager. The facilities manager oversees the maintenance of the physical environment housing the IT infrastructure. This can include managing elements such as power and cooling systems, regulating building access and monitoring environmental conditions.
- Change management team. This team evaluates and sets up changes required to resolve incidents. A key focus of the change management team is to ensure that the changes adhere to organizational policies and best practices.
In DevOps organizations, software developers are considered responsible for production-ready code under the mantra of "you build it, you own it." In the event of a software incident, the developer should provide incident response and management.
IT incident management process
In practice, IT incident management often relies on temporary workarounds to ensure services are up and running while IT staff investigates the incident, identifies its root cause, and develops and rolls out a permanent fix. Workflows and processes in IT incident management differ depending on each IT organization and the issue they’re addressing.
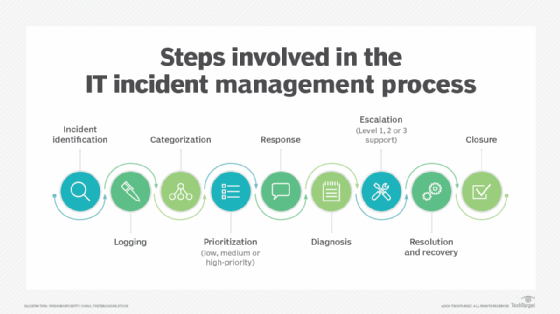
A common framework to understand IT incident management is through analyzing the ITIL process. ITIL, trademarked by Axelos, is a widely used ITSM framework. ITIL incident management uses a workflow for efficient resolution: incident identification, logging, categorization, prioritization, response, diagnosis, escalation, resolution and recovery, and incident closure.
Typical steps involved in an IT incident management process include the following:
- Incident identification. Most IT incident management workflows begin with users and IT staff pre-emptively addressing potential incidents, such as a network slowdown. These incidents can also be reported through notification and alert monitoring tools.
- Logging. Once an incident is identified, it’s logged into the incident management system. This entails capturing relevant details such as the nature of the incident, how it's affecting the services, and what its initial diagnosis or assessment is. Documentation helps IT staff find previously unseen and recurring incident trends, address them, and review and log the incident for future reference. If a temporary workaround is in place, once the disruption to end users is mitigated, IT staff can develop a long-term fix.
- Categorization. Incidents are categorized based on their type, severity and effect on business operations. For example, they could be categorized as low-, medium- or high-priority incidents.
- Prioritization. After categorization, incidents are prioritized according to their urgency and importance. For example, Level 1, or low-priority incidents, are typically assigned to less experienced technicians, whereas higher-level incidents, such as Levels 2 and 3, are assigned to more experienced staff members.
- Response. The next step is to respond to the incident promptly and create an incident response plan. This might involve opening incident tickets and communicating proactively with end users and stakeholders to provide updates on the incident status, resolution progress and any actions required from their end.
- Diagnosis. After the incident response, the IT team investigates the incident to determine its root cause and develop a resolution plan. This could involve analyzing logs, conducting tests or engaging with relevant stakeholders.
- Escalation. The first level of support performs the initial triage. If the incident can’t be resolved within a specified timeframe, it’s escalated to the higher tiers of support.
- Resolution and recovery. Once the root cause is identified and the issue is escalated appropriately, the IT support team takes the necessary measures to resolve the incident and restore services to normalcy. This might involve applying fixes, hardware and software upgrades and creating workarounds.
- Closure. After the incident is resolved, it’s formally closed in the incident management system. This includes documenting actions taken and lessons learned during the process as well as updating relevant knowledge bases.
A focus on IT incident management processes and established best practices can minimize the duration of an incident, shorten recovery and resolution time and help prevent future issues. Clear, transparent and timely communication throughout the process should be maintained with stakeholders, including end users, IT staff and management. This ensures that everyone is aware of the status of the incident and its resolution.
What are the benefits of IT incident management?
IT incident management offers the following key benefits that contribute to the efficient functioning of an organization's IT services:
- Enhanced efficiency and productivity. Incident management processes let help desk agents handle each incident promptly and consistently, improving efficiency and productivity. For example, with a well-defined IT incident management process, when a service experiences downtime, the incident is promptly logged, classified and directed to the relevant support team by service desk agents for expedited resolution.
- Improved transparency and visibility. By following a structured incident management process, affected parties, customers and stakeholders are updated on the status of their tickets in real time, enhancing transparency in the resolution process.
- Minimized downtime. Automated monitoring tools, alert systems and proactive monitoring practices identify issues promptly, helping IT teams initiate the incident response process without delay. By promptly addressing and resolving incidents, critical services and systems remain operational and downtime is minimized.
- Improved customer satisfaction. Incident management processes help maintain service levels and meet agreed-upon service level agreements. Transparent communication, effective escalation and rapid resolution of incidents enhance overall customer satisfaction.
- Enhanced collaboration and communication. Effective incident management improves stakeholder collaboration and enhances communication through well-defined roles and centralized communication channels, such as ticketing systems and regular status updates.
- Continuous improvement. Incident management encourages a culture of continuous improvement by analyzing incidents, learning from them, and using the insights to enhance processes and overall IT service delivery. By addressing underlying causes and using corrective actions, organizations can proactively prevent similar incidents in the future, leading to more reliable service delivery and increased customer satisfaction.
- Early risk identification. Incidents often highlight potential risks in IT systems. Effective incident management identifies these risks, enabling the early adoption of preventive measures to reduce the likelihood of future incidents.
Is incident management related to ITIL?
Incident management is a part of the ITIL framework. The following are some differences and similarities between the two concepts:
- ITIL is a set of detailed practices for ITSM that focus on aligning IT services with the needs of the business.
- Incident management is a key process within ITIL, aimed at restoring normal service operations as quickly as possible while minimizing the effect on business operations. It’s defined as one process area within the broader ITIL and International Organization for Standardization 20000 environments.
- The ITIL incident management process is designed to ensure that improvement potentials are derived from past incidents and to supply incident-related information to other service management processes.
- Incident management is focused specifically on the management of IT incidents.
- ITIL offers a thorough framework for incident management, from which organizations can follow or borrow to create their own IT and incident management processes.
- Incident management teams are the frontline support when incidents occur, and their role is to identify and repair incidents to restore the defined service levels as quickly as possible.
Incident management tools
Help desk and incident management teams rely on a mix of tools to resolve incidents, such as monitoring tools to gather operations data, root cause analysis systems, and incident management and automation platforms.
Common types of incident management tools include the following:
- Monitoring tools. Monitoring tools typically detect outages, trigger alerts and diagnose incidents. These tools also enable IT staff to pull operations data from across multiple systems, such as on-premises or cloud-based hardware and software.
- Root cause analysis tools. Root cause analysis tools help sort through operational data, such as logs that systems management, application performance monitoring and infrastructure monitoring tools collected. Root cause analysis tools help IT staff understand how a system operates and where any incidents reside.
- Incident response tools. These tools correlate with monitoring data and facilitate response to events, typically with a sophisticated escalation path and method to document the response process. Many incident management products establish escalation policies as well as create automated workflows, alerting users of incidents based on preconfigured parameters.
- ITSM service desk tools. These tools log data such as what the incident was, what caused it and what steps were taken to solve the incident. For example, root cause analysis and auditing tools log and prioritize IT incidents using a self-service portal. They can log incidents by instance, classify them by level of effect and urgency, escalate them as required and perform analysis for future improvements.
- Artificial intelligence and virtual agents. AI and virtual agents are transforming incident management procedures. AI analyzes historical incidents to improve prediction, detection and resolution. Meanwhile, virtual agents, such as chatbots, provide instant responses to common inquiries and perform basic troubleshooting, freeing human agents to address more complex issues.
- AIOps. AIOps integrates machine learning and big data to automate IT operations, enhancing the incident management process. By analyzing vast data sets in real time, AIOps identifies patterns and anomalies that could signal potential incidents. It can recommend options based on historical data, thereby improving incident resolution efficiency and enabling proactive incident prevention and mitigation.
- VDocumentation. Automated community-created sets of VMware PowerCLI scripts that can record changes in vSphere environments, facilitating incident documentation for post-mortem analysis. For example, teams can schedule PowerCLI scripts to run monthly, capturing incidents for detailed review.
According to Gartner, the market includes vendors offering ready-to-use workflows to support different business requirements beyond IT. The list includes the following 10 vendors in alphabetical order:
- 4me.
- Atlassian.
- BMC Software.
- Freshworks.
- Ivanti.
- ManageEngine.
- OpenText.
- ServiceNow.
- SolarWinds.
- TeamDynamix.
Best practices in IT incident management
There are several best practices that organizations can follow to effectively respond to unplanned IT events or service interruptions:
- Define severity and priority levels. IT teams should define severity and priority levels before an incident occurs, as this makes it easier for incident managers to gauge priority quickly.
- Use incident tracking and ticketing systems. IT teams should set up reliable incident tracking and ticketing systems to log, monitor and manage incidents throughout their lifecycle.
- Record all activities. IT incident management teams should always document everything in a single tool with as much detail as possible, regardless of the event's level, urgency or caller's position. Monitoring every occurrence reduces the time it takes to respond and resolve it. Automated systems are also available for log reconciliation.
- Distinguish incidents from problems. It's essential to distinguish between incidents and problems. Incidents refer to unplanned events or service interruptions, while problems are the not-yet-known root cause behind one or more incidents.
- Establish clear communication channels. Clear communication channels should be maintained with stakeholders, including end users, IT staff and management to provide updates on incident status and resolution progress.
- Ensure team alignment. Incident management teams should standardize procedures to guarantee that each member follows identical protocols and appropriate responses for every incident. This fosters consistent and uniform service quality across the board.
- Identify escalation procedures. Escalation paths should be defined for incidents that can’t be resolved by front-line support teams. Teams should also ensure that escalations are handled promptly and efficiently.
- Use automation for incident management. In addition to following best practices, turning to automation can help sustain service continuity and reliable support during sudden incidents.
- Test incident response plan. The most effective method for practicing incident response is by simulating real incidents. Instead of merely discussing these steps, this approach lets IT teams systematically go through each step and execute it.
Despite being used interchangeably, the terms incident management and incident response have distinct connotations. Learn the key differences between these terms to effectively manage security incidents.







