Storage software is a primary performance concern when using NVMe. Discover three workarounds vendors use to fix the problem that exists between NVMe flash and storage software.
NVMe has a lot to offer enterprise storage systems. The technology improves flash storage performance by increasing command count and queue depths while using PCIe as its primary interconnect. It is a protocol that works both inside a server and outside, and it is networkable for shared storage environments.
The NVMe performance improvement most organizations will see is a reduction in latency. That latency reduction is so significant that the protocol exposes other weaknesses in the storage infrastructure.
Storage ecosystem problems
Storage architectures typically contain storage media, in this case, NVMe flash; storage software to drive the storage system; and the storage network, which externally connects storage to other elements in the data center like servers. In the HDD era, and even in the SAS-based flash era, the performance of these components could hide behind the latency of the storage media. With NVMe flash, however, media latency is almost eliminated, and the resource overhead created by these components is exposed.
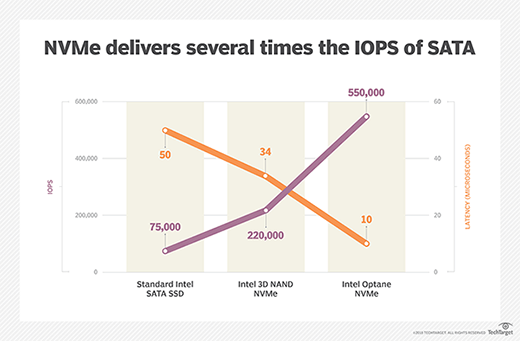
An easy way to verify this latency gap is to examine the raw performance of an NVMe-based flash drive. Many NVMe drives claim more than 500,000 IOPS. Yet most storage systems, even though they have 24 of these drives, deliver only 10% of the potential raw performance of a single drive. A typical name brand NVMe array with 24 NVMe drives may have the raw potential to deliver almost 12 million IOPS, but once the overhead of the storage ecosystem is factored in, it often only delivers less than 1 million IOPS.
NVMe performance gap workarounds
CPU power continues to increase, and, with NVMe over fabrics on the horizon, most networking issues with NVMe-based flash storage will be resolved. That leaves storage software as the primary area of performance concern in the storage ecosystem when using NVMe.
Vendors use a number of workarounds to fix the software problem that exists between NVMe flash and the storage software. The most common one is to put the latest and most powerful processors in the storage system so the storage software can process I/O and manage features more quickly. The problem is that companies like Intel continue to improve processing power by increasing the number of cores and not the power per core. If the storage software is not multithreaded, there will be little benefit to using more powerful processors.
A second workaround is for vendors to move their storage software into field-programmable gate arrays (FPGAs) or even silicon. Moving software to hardware is the opposite strategy of the software-defined data center concept gaining in popularity nowadays, but it may be the most viable method for organizations with pressing storage I/O performance problems. The FPGA provides storage software with dedicated processing power that isn't as core-based.
A third workaround is to limit the role of software and to reduce the number of features it provides. The reasoning is that most high-performance applications have similar capabilities built into them, so offloading the storage management performance load to those applications better distributes the performance issue. The challenge is that not all applications support the advanced storage features demanded by enterprises. In addition, each application executes these features differently, so the lack of standardization leads to greater storage management complexity.
Fixing the NVMe performance storage problem
The process of fixing storage ecosystem performance so it catches up with NVMe performance is a time-consuming one. Storage developers need to rewrite their storage software, potentially from the ground up, to be truly parallel. Most vendors today claim some level of multithreading, but, in many cases, it is because they dedicate certain tasks to specific cores, which is not the most efficient use of available CPU power. With core counts now reaching into the twenties, there are often more cores than there are tasks. Instead, vendors should stripe I/O functions across cores so that all cores are used equally every time.
With the exception of AI and machine learning workloads, most organizations don't have the application horsepower to tap into the full performance of NVMe-based systems or networks.
The second step, which is potentially even more time-consuming, is to reevaluate and rewrite many of the basic storage algorithms that have not changed in decades. Vendors need to consider rewriting core functions like RAID, metadata tracking for snapshots, deduplication, replication and thin provisioning to ensure they are optimized for the high core count of today's processors and the very low latency of current storage media.
What to do now?
With the exception of AI and machine learning workloads, most organizations don't have the application horsepower to tap into the full performance of NVMe-based systems or networks. The exception is enterprises looking to increase the number of virtual machines per physical server. As the VM ratio per server continues to increase, the I/O load becomes considerable. NVMe storage and NVMe over fabrics networking deliver the I/O capabilities to meet the performance challenge of these very dense VM-to-physical server ratios. If vendors fix the storage software problem, densities of hundreds of VMs per physical server become possible.
Most NVMe systems coming to market are trying to push performance by using more powerful processors. Some organizations will pay a premium for this approach, but it should sustain them until software catches up with hardware. Others may find it in their best interest to continue to use SAS-based all-flash arrays, as they more than likely meet near-term performance needs while also being less expensive.
Finally, enterprises should be on the lookout for storage software offerings coming to market that are highly parallelized and where work has been done to optimize storage algorithms. These should be able to deliver needed performance with substantially fewer NVMe drives.