IoT data analytics spurred on by big data's expansion
Data from the Internet of Things creates opportunities to analyze equipment performance and track the activities of drivers and users of wearable devices. But IoT data analytics requires significant IT provisions.
Every day, Intelligent Mechatronic Systems Inc. collects 1.6 billion data points from hundreds of thousands of automobiles in the U.S. and Canada. The cars are equipped with devices that track driving distance, acceleration, fuel use and other information on how the vehicles are being operated -- data that IMS uses to support usage-based insurance programs and fleet and traffic management initiatives. Until the middle of this year, the data was stored in a MariaDB relational database, but the open source software imposed rigid limits on how the data could be structured, which complicated efforts to analyze it.
"We knew there was inherent value in the data," said Christopher Dell, senior director of product development and management at Intelligent Mechatronic Systems (IMS). "We just didn't know how to unlock that value."
So in August 2015, after a yearlong project, IMS added an Apache Cassandra NoSQL database along with data integration and analytics tools from Pentaho. Now, data flows through the MariaDB system into Cassandra, giving the Waterloo, Ontario, company's data scientists more flexibility in formatting the information. That setup lets the analytics team perform finer-grained analysis of customer driving behavior in search of patterns and trends that could help insurers fine-tune their usage-based policies and rates.
In addition, Dell said the new technologies should allow IMS to better handle future data growth, which is expected to be generated by two developments. The company hopes a newer smartphone app for collecting vehicle data will make its subscriber base "skyrocket." There's also an ongoing move to combine driving information with other types of data from the Internet of Things (IoT), such as weather records and telematics captured by so-called smart home systems.
Christopher Dell
Like IMS, organizations looking to collect and analyze IoT data often find they first need to beef up their IT architectures. That applies to companies on both the consumer and enterprise sides of the IoT fence: The challenges of pulling in and processing large amounts of data from onboard diagnostics gear, industrial sensors, fitness trackers, phones and other devices know no business boundaries. Upgrades typically include big data management technologies such as Hadoop, the Spark processing engine and NoSQL databases, plus advanced analytics tools that can support machine learning and other algorithm-driven applications. And in many cases, a mix of technologies is needed to meet all IoT data analytics needs.
Big data expansion
Cisco Systems Inc.'s WebEx unit installed a Hadoop cluster three years ago to store data from mobile devices and PCs that connect to its Web and video conferencing services. After initially developing some standalone analytics applications for individual departments, WebEx in early 2014 adopted a unified strategy for tracking usage, analyzing performance and diagnosing technical problems at its end and on customer networks. But this year, Cisco -- based in San Jose, Calif. -- had to expand the Hadoop system and augment it with additional big data tools. The expansion was prompted by new types of analytics as well as an increasing data load that amounts to multiple terabytes daily, with the total collected approaching a petabyte.
We knew there was inherent value in the data. We just didn't know how to unlock that value.
Christopher DellSenior director of product development and management, Intelligent Mechatronic Systems
Joe Hsy, director of WebEx's cloud services platform and tools, said his team added 30 nodes to the Cloudera-based cluster in the fall, boosting the total to more than 100 nodes. And last summer, WebEx began using the Apache Kafka message-queuing technology to more quickly feed telemetry data into the Hadoop cluster and other systems to support real-time performance monitoring and alerting. In addition, the conferencing unit is starting to use Spark to filter streams of incoming data into subsets for analysis and to power a prototype machine learning application aimed at improving its ability to detect fraudulent phone calls. The infrastructure also includes Cassandra, used to store event logs for diagnostics, and Oracle databases that hold meeting-history data. At the front end, WebEx primarily relies on Platfora's Hadoop-based analytics tools, plus Tableau and Excel for business users.
The growing number of technology options enables organizations like WebEx to do more with IoT data than they could previously. But managing Hadoop, Spark and related open source tools can be a challenge, Hsy said, pointing to bugs and administration shortcomings partly due to the fast pace of development and updates on those technologies and commercial versions of them.
Looking for a balance between new features and stability, WebEx typically stays one release behind the latest version of the technologies it's using. "We're an operations team, so we can't be cutting edge," Hsy said. But he added that keeping an eye on development plans and big data trends is crucial in such a fast-moving environment. "That's a big part of what we have to do as a team -- not only keep the systems running but look to the future to what's coming next."
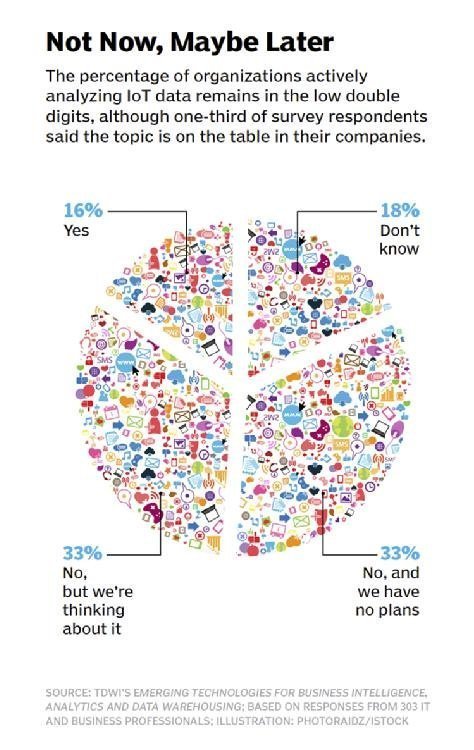
IoT data analytics is still the province of early adopters. According to a TDWI survey conducted in May 2015, only 16% of the 303 respondents said their organizations were analyzing IoT data. Another 33% said possible initiatives were being considered [see Figure 1]. But in its fourth annual "hype cycle" report on the IoT, published in July, consulting and market research firm Gartner predicted that most IoT data analytics technologies and processes are still five to 10 years away from mainstream adoption. There's a good reason for that. Gartner analysts wrote that IoT deployments pose "formidable" challenges and typically require investments in a "daunting array" of technologies, plus new data management and analytics skills.
Figure 1
Parsing petabytes of data
For many companies, the volumes of data that the IoT can deliver take them into an entirely new processing realm. "We're collecting data at fairly extraordinary rates, at least in my world," said John Dyck, global director of software business development at Rockwell Automation Inc.
Over the past three years, the Milwaukee-based company has built a new architecture based on Microsoft's Azure cloud platform to capture data on equipment and plant operations from manufacturing control systems at customer sites. According to Dyck, more than 100 companies in the oil and gas industry and various manufacturing verticals are currently using the cloud setup; Rockwell manages and analyzes the data for about two-thirds of them, while the others handle these tasks themselves.
The data Rockwell stores in the cloud architecture already measures "in the single-digit petabytes overall," Dyck said. The amount generated by individual plant-floor devices is easy to handle. But collecting information from a thousand pieces of equipment in a factory multiple times per second -- and repeating that process across multiple facilities and different customers -- is "a whole different story," he noted. "It took us a while to address that and work through it."
John Dyck
Eventually, the company created a schedule akin to a shipping manifest for managing the collection process; it also built in buffering and store-and-forward mechanisms that help ensure data is gathered "even when the network pipeline gets narrow or goes offline," Dyck explained. And after initially relying solely on Microsoft's relational Azure SQL Database, Rockwell last year added HDInsight -- the vendor's Hadoop distribution -- as a second-stage repository to boost its ability to handle all the incoming data.
The industrial automation company also is tapping the Hadoop system, along with Microsoft's Azure Machine Learning analytics technology, to help move beyond conventional performance monitoring and develop predictive models that can expose possible equipment failures before they occur. Rockwell is running pilot projects on that with a half-dozen customers, Dyck said. In the past, he added, predictive maintenance "was almost a pipe dream" because most manufacturers left the data generated by different devices in isolated databases. But now, with access to larger pools of data, Rockwell's data scientists are building automated algorithms that, Dyck said, "are making predictions we can be confident about."
Such algorithms require a mix of current and historical data, and getting the historical data out of all those isolated manufacturing databases requires a robust architecture. "If it takes you six months to ingest three years of history, that's kind of a deal-breaker," acknowledged Alex Bates, co-founder and CTO at software vendor Mtell. In March 2015, the company announced a platform combining a predictive maintenance application with a data repository based on the Hadoop distribution from MapR Technologies.
Of course, not all the data that's there for the taking on the IoT is necessarily golden. Like IMS, Automatic Labs Inc. sells devices that plug into the onboard diagnostics port in cars and collect data to track vehicle performance metrics. The devices send back everything that's made available through the port, amounting to millions of rows of data per day, according to Rob Ferguson, the San Francisco company's vice president of software engineering.
Rob Ferguson
The data goes into an Amazon Simple Storage Service (Amazon S3) repository for processing and analysis on a pair of cloud-based clusters running Databricks' version of Spark. But not all of the data is used. "Right now, we collect more data than we know what to do with," Ferguson said.
He added that Automatic Labs wants to hold onto as much of the information as possible, partly to enable more advanced analytics applications for new usage-based insurance and fleet management services it's launching. But to keep the size of the company's S3 stores from getting out of hand, Ferguson's team filters out some data "in cases where we're getting more noise than signal." For example, he said voltage data has been skewed by the growing use of hybrid cars such as the Toyota Prius.
As for IMS, the billions of data points it's collecting from cars don't add up to a huge amount of bytes. Dell said the company has a total of 75 terabytes in its systems. Initially, however, IMS spread the data across separate environments for the different insurers it works with. Pulling all that information together into the Cassandra database and making it consistent without affecting the data's integrity "was more of a challenge than we expected upfront," he noted.
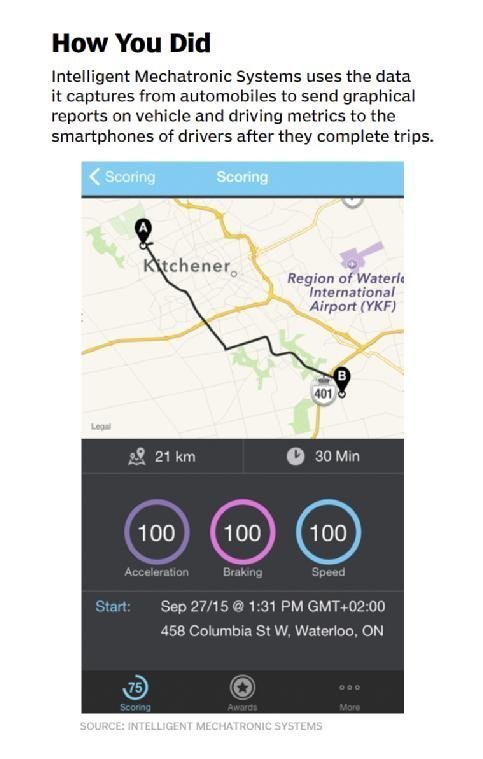
Now, the company is using the centralized repository to push forward on new analytics initiatives. In addition to the trip reports it sends to the smartphones of drivers [see Figure 2], IMS released in September a set of analytics tools and dashboards that allow insurers to track their usage-based insurance programs and identify driving behaviors that could trigger changes to insurance policies.
Figure 2
Dell's team also launched a 1.0 version of the analytics tools for internal business users in operations and finance. "We kept it fairly locked down on what they could do," he said, adding that he wanted to make sure the upgraded architecture could handle the additional workload. He's planning a second release in early 2016 that will give internal users more freedom to run queries against the Cassandra system. And with the new database in place and tested out, Dell said he's now confident that IMS "won't have to pull data into another data store to do analytics."
For many other organizations trying to tap into IoT data analytics, though, the challenges of combining various big data platforms and analytics tools into an architecture that can stand up to the flood of information are just beginning.
Next Steps
Smart-phone apps for collecting vehicle data
Managing the data collection process
Comparing cloud storage architecture to local data storage
Learn why IOT companies are struggling with back-end integration


 Christopher Dell
Christopher Dell
 John Dyck
John Dyck
 Rob Ferguson
Rob Ferguson