Databricks adds vector search, new LLM support to AI suite
The data lakehouse pioneer is targeting model accuracy with the GA of vector search capabilities that help customers find the data needed to train advanced analytics applications.
Databricks on Wednesday made vector search generally available in a move aimed at helping customers develop accurate generative AI models and applications.
In addition, the vendor added capabilities to Model Serving, its environment for developing and managing AI and machine learning models. Among them are support for more large language models (LLMs) and a new user interface, designed to enable users to better develop and manage accurate generative AI models and applications.
Collectively, the new capabilities are important, given that the enterprises that use platforms from vendors such as Databricks are investing heavily in building generative AI applications, according to David Menninger, an analyst at ISG's Ventana Research.
"Our research shows that half of enterprise AI budgets are going toward generative AI," he said. "So, these features are important, not so much with their magnitude, but with their relevance."
Based in San Francisco, Databricks is a data lakehouse pioneer whose platform combines the structured data management capabilities of a data warehouse with the unstructured data management capabilities of a data lake.
In addition, the vendor has made generative AI development a priority over the past year and through a combination of acquisitions and product development created an environment where customers can build and manage AI models and applications.
Perhaps Databricks' most significant acquisition was its $1.3 billion purchase of MosaicML in June 2023, with Mosaic's capabilities now the foundation of Mosaic AI. Product development, meanwhile, has included the introduction of retrieval-augmented generation (RAG) capabilities to help users train models with their own proprietary data.
Vector search
Generative AI has the potential to be a transformative technology for analytics by enabling more people within organizations to work with data and helping those already using BI as part of the jobs to more efficient. However, it has been plagued by a lack of accuracy.
LLMs, which have extensive vocabularies and can infer intent, enable true natural language processing. That greatly reduces the need to know and write code to interact with data, eliminating one of the major barriers to widespread BI adoption and enabling data experts to work more quickly.
However, unless trained with pertinent data, generative AI models can deliver inaccurate responses. That means that for a language model to deliver accurate responses about an individual business -- whether a fine-tuned LLM or a purpose-built small language model -- it has to be trained on that business' data.
One of the most effective means of training a model with proprietary data is vector search.
Vector embeddings are numerical representations of data. Using them, enterprises can search for and discover similar data within potentially billions of other data points. That similar data can then be combined to form a data set that can be used to train a generative AI model.
In addition, using vector embeddings, enterprises can give structure to unstructured data such as text, images and audio files that without structure cannot be included in the data sets used to train models. An estimated three-quarters or more of all data is unstructured. Without vector embeddings, that data is inaccessible and models don't benefit from its information.
As a result of the ways vector embeddings can help feed the RAG pipelines that inform generative AI models, vector search and storage are now critical data management capabilities.
Vendors including tech giants AWS and Oracle have made vector search a priority, as have more specialized vendors such as Couchbase and MongoDB.
Databricks first unveiled vector search in December as part of a suite for building RAG pipelines. Now it is available and fully supported by the vendor in a move that is significant not only because it adds a key new capability but also because it enables existing Databricks customers to use such capabilities from a trusted vendor, according to Kevin Petrie, an analyst at BARC U.S.
"The GA of vector search is a big deal because many companies already manage data science projects on Databricks," he said. "As they tackle GenAI, they need help feeding language models their own domain-specific data."
Vectors do just that, Petrie continued, noting that vectors are the means for training models to accurately understand the unique characteristics of an individual organization.
"BARC research shows that many companies prefer to use established vendors for new initiatives, including those that relate to GenAI and vector databases," he said. "So Databricks is moving quickly to fill this market need."
Menninger similarly noted that the significance of Databricks making its vector search capabilities generally available is that they will help simplify generative AI development for its users.
Enterprises are implementing vector search with or without Databricks. Obviously, it is easier and less complex to have a single vendor solution than a multi-vendor solution.
David MenningerAnalyst, ISG's Ventana Research
Numerous other vendors now provide similar capabilities. But the fewer platforms that enterprises have to piece together to develop RAG pipelines, the easier it is for those enterprises to manage their AI operations.
"Enterprises are implementing vector search with or without Databricks," Menninger said. "Obviously, it is easier and less complex to have a single vendor solution than a multi-vendor solution."
Model Serving update
While vector search aims to help customers discover and operationalize data to feed RAG pipelines, new capabilities in Model Serving are designed to enable users to develop, deploy and manage customized AI models.
First introduced in March 2023, Model Serving not only provides an environment for developing and managing models but it also enables Databricks customers to deploy those models as REST APIs on the vendor's lakehouse platform.
By doing so, Model Serving simplifies model development and management by eliminating the need for complex machine learning infrastructures made for specialized tools from various vendors. Users no longer need to use batch files to move data into a cache within a data warehouse to build a model and then move the model from the data warehouse to an application where it can be used for analysis.
Instead, users can do all their development, training and managing in a single environment that includes integrations with Databricks' MLflow Model Registry for deployment and Unity Catalog for governance.
One of the key additions to Model Serving is support for a broader array of LLMs to provide users with more choice as they determine which generative AI models best suit their needs, according to Petrie
In addition to models from OpenAI, Mistral AI, Cohere, Ai21labs and those included in Amazon Bedrock, Model Serving's Foundation Model API now supports Databricks' own DBRX, Claude3 from Anthropic, Google Gemini and Meta's Llama 3.
"Experts across the industry are chanting the mantra that 'no single model will rule them all,'" Petrie said. "This is because different language models, especially small, domain-specific models, have different strengths, weaknesses and target use cases. GenAI adopters need to experiment with multiple models to find the right fit and stay flexible to switch models when requirements change."
Menninger likewise said model choice is important because models have different strengths. But beyond that, he noted that as each new model is released, it seemingly betters the performance of those previously released.
By providing integrations with models from numerous prominent vendors -- along with open source models -- Databricks is enabling customers to keep up with the pace of LLM innovation.
"The world of LLMs is evolving so rapidly that no clear leader has emerged," Menninger said. "There are many reasons to choose one model over another, including accuracy, cost, specificity, latency, sovereignty and governance. As a result, enterprises need options."
In addition to adding more model choice, new capabilities in Model Serving include the following:
A personalized homepage, now in preview, that tailors a user's experience based on common actions and workloads and includes a "Mosaic AI" tab that enables easy access to models.
Integration with Databricks Vector Search.
Secrets UI, a new interface that makes it easier to add functions to enable easy communication between Model Serving and an organization's external systems.
Function Calling, a feature now in private preview that allows LLMs to generate responses based on structured data more quickly by connecting to external services.
Guardrails, also in private preview, to help customers filter out harmful or sensitive content.
Added governance and auditability capabilities, including support for inference tables that help monitor and debug models, no matter where the model is served once it is deployed.
New governance capabilities, in particular, are important, according to Menninger.
Some vendors leave AI governance up to their customers, he noted. But just as data governance was critical once analytics expanded beyond the realm of data experts to include self-service users, as AI use increases, more AI governance is needed to protect organizations from violating fast-changing regulations and ensuring that sensitive data remains private.
"We are in the middle of our assessment of vendors … and the governance capabilities of vendors vary widely," Menninger said. "Many leave the process of governance in the hands of the customer, providing suggestions and guidance but no tools. I believe enterprises will appreciate the governance and auditability features."
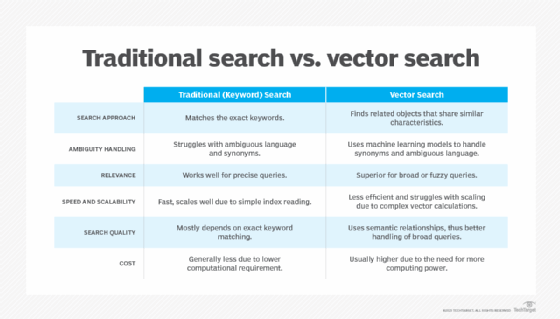
A comparison of vector search and keyword search.
Looking ahead
With vector search and the new Model Serving capabilities now available, Databricks has plans to unveil more new features in June at its Data + AI Summit in San Francisco, according to Craig Wiley, the vendor's senior director of product.
Just as generative AI has been a significant focus for Databricks for well over a year, it features prominently on the vendor's roadmap.
In particular, Databricks plans to continue trying to improve the accuracy of generative AI models, and do so with strong data governance and lineage capabilities, according to Wiley.
"Our focus in generative AI is on helping customers derive value from their data by building and deploying intelligent applications … that not only understand their data but also ensure proper governance," he said. "A major challenge in building and deploying these applications is maintaining high enough quality for customer-facing environments. This is an area where we will continue to invest."
AI governance is another area Databricks will likely focus on, according to Petrie.
"I'll be interested to see how Databricks strengthens its governance controls to help companies make GenAI inputs more trustworthy," he said. "I think Databricks customers will appreciate more guidance in this area, both in terms of software and services, and possibly including partner offerings."
Eric Avidon is a senior news writer for TechTarget Editorial and a journalist with more than 25 years of experience. He covers analytics and data management.