Vector search now a critical component of GenAI development
The feature's ability to make unstructured data discoverable as well as locate similar data points among potentially billions make it ideal for helping train generative AI models.
Vector search is nothing new. Its role as a critical data management capability, however, is a recent development due to the way it enables discovering data needed to inform generative AI models.
As a result, a spate of data management vendors, from data platform providers such as Databricks and Snowflake to specialists including Dremio and MongoDB, introduced vector search and storage capabilities in 2023.
Vector databases date back to the early 2000s. Vectors, meanwhile, are simply numerical representations of unstructured data.
Data types such as names, addresses, Social Security numbers, financial records and point-of-sale transactions all have structure. Because of that structure, they can be stored in a database and other data repositories, and easily searched and discovered.
Text, however, has no structure. Neither do audio files, videos, social media posts, webpages or IoT sensor data, among other things. But all that unstructured data can be of great value, helping provide information about a given subject.
To prevent unstructured data from getting ingested into a data warehouse never to be seen again -- to make it discoverable amid perhaps billions of data points -- algorithms automatically assign vectors when unstructured data is loaded into a database, data warehouse, data lake or data lakehouse.
That vector then enables large-scale similarity searches rather than only searches for exact matches, which is significant, according to Sahir Azam, chief product officer at NoSQL database vendor MongoDB.
You can take any source of knowledge and turn it into a complex mathematical representation, which is a vector, and then you can run similarity searches that basically find objects that are related to each other without ever having to manually define their characteristics. That's extremely powerful.
Sahir AzamChief product officer, MongoDB
"You can take any source of knowledge and turn it into a complex mathematical representation, which is a vector, and then you can run similarity searches that basically find objects that are related to each other without ever having to manually define their characteristics," he said. "That's extremely powerful."
Alex Merced, developer advocate at data lakehouse vendor Dremio, likewise pointed out the vital role vector search plays in enabling analysis.
"Vector search allows you to [ask questions of data] without having to wait for a dashboard to be built," he said. "That can be transformative. People want the same data at their fingertips that they [previously] had to have had researched. Vector search allows you to do that."
Historically, vector search and storage were mainly used by search-driven enterprises that collected vast amounts of data. Like graph technology, they were used to discover relationships between data. For business applications, they included geospatial analysis.
Eventually, vector search and storage evolved to include AI model training. But they were still not mainstream capabilities.
Generative AI (GenAI) has changed that over the past year.
Large language models (LLMs) rely on data to generate query responses. Vectors provide a fast and effective way to discover that needed data.
GenAI explosion
When ChatGPT was released by OpenAI in November 2022, it represented a significant improvement in LLM technology. Right away, it was obvious that generative AI could help users of analytics and data management tools.
For well over a decade, analytics use within organizations has been stagnant at around a quarter of all employees. The tools themselves are complicated and require significant training to use -- even those with some natural language processing (NLP) and low-code/no-code capabilities.
LLMs change that by enabling conversational language interactions. They are trained with extensive vocabularies and can determine the meaning of a question even if it isn't phrased in the business-specific language required by previously existing NLP tools.
In addition, LLMs can generate code on their own and be trained to translate text to code. That can eliminate some of the time-consuming coding that eats up much of data engineers' and other data workers' time as they integrate data and develop data pipelines.
However, to be a truly transformative technology for a business, generative AI needs to understand the business.
LLMs such as ChatGPT and Google Bard are trained on public data. They can be questioned about ancient Rome or the American Revolution, but they have no idea whether a manufacturer's sales were up or down in Iowa during the spring, and they certainly can't explain why those sales headed in a certain direction.
To do that, language models need proprietary data.
As a result, after the initial hype around ChatGPT began to wear off, and enterprises realized that public LLMs couldn't really help them without being augmented with their proprietary data, some began training models with their own data.
Rather than wait for vendors to provide them with tools, a small number of enterprises with significant data science resources started building domain-specific models from scratch. Others, meanwhile, integrated their data with existing LLMs.
"We've entered a new phase of GenAI adoption in which companies are applying language models to their own domain-specific data in order to address specialized use cases," said Kevin Petrie, an analyst at Eckerson Group.
One way they're doing so is by exporting proprietary data and fine-tuning a pre-trained model, he continued. Another is essentially taking the opposite approach and importing LLMs to enrich users' data prompts.
"The vector database feeds domain-specific data to language models to support both these scenarios, especially the prompt-enrichment scenario," Petrie said.
Similarly, Donald Farmer, founder and principal of TreeHive Strategy, said vectors are particularly useful for training generative AI.
He noted that generative AI is good at understanding subtleties, which is particularly applicable to language. Vectors help generative AI discover not only what data -- including words -- is most likely to be related, but what data is most applicable to a given query.
"That's something a traditional system can't do because it doesn't have weightings," Farmer said. "GenAI can use these weightings -- these vectors -- that give it the subtlety to choose the right [data]."
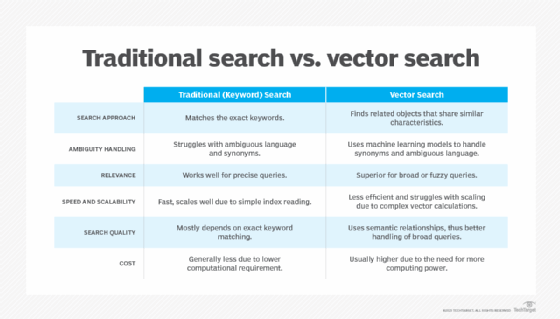
A comparison of vector search and keyword search.
Part of a pipeline
While vectors have become integral to training generative AI models, organizations still need to get vectorized data from a vector database or other storage repository into a model.
RAG is an AI capability that gathers data from where it's stored to supplement the data already used to inform an application. The intent is to improve the application's output by adding more training data.
In particular, RAG pipelines both keep applications current by providing the applications with the most recent data as well as make them more accurate by adding more data volume. Not surprisingly, as organizations aim to improve the accuracy of LLMs and train them to understand domain-specific use cases, many have made RAG pipelines a priority.
Vector search, meanwhile, is a key component of a RAG pipeline.
Along with searches to discover relevant structured data, vector search enables the discovery of relevant unstructured data to train a model. The two are combined with other capabilities such as data observability to monitor quality to create a RAG pipeline.
"The most popular method of enriching prompts is RAG," Petrie said.
Using a RAG pipeline, generative AI applications can receive prompts from users, search vector storage for responses to past prompts that were similar, retrieve the vectors and then add them to the generative AI application, according to Petrie.
"At that point, the language model has relevant facts and content that help it respond more accurately to the user prompt," he said.
As a result of the growing importance of RAG pipelines and the role of vector search in feeding those pipelines, Databricks in early December unveiled an entire suite of new tools designed to help customers build RAG pipelines.
Databricks has been among the most aggressive vendors in making generative AI a focus over the past year. In June, it acquired MosaicML for $1.3 billion to add LLM development capabilities. In October, it introduced LLM and GPU optimization capabilities aimed at helping customers improve the results of generative AI applications. In November, Databricks unveiled plans to combine AI and its existing data lakehouse platform and rename its primary tool the Data Intelligence Platform.
Graph database specialist Neo4j is another data management vendor with plans to add RAG pipeline development capabilities. Meanwhile, data observability specialist Monte Carlo in November added observability for not only vector databases, but also Apache Kafka, a popular tool for feeding data into vector databases.
While perhaps the most popular method, RAG pipelines aren't the only way to feed vectorized data into a generative AI application.
In fact, there are ways to feed generative AI that don't include vectors, according to MongoDB's Azam. Vectors, however, when paired with other capabilities in a data pipeline, improve and enhance the pipelines that inform generative AI.
"A GenAI app is still an app," Azam said. "You still need a database that can serve transactions at high fidelity and high performance, [semantic] search capabilities to understand similarities, and stream processing to deal with data in real time. These other capabilities don't go away. Vectors open a whole new ecosystem of use, but are one pillar in a data layer to empower applications."
Effectiveness
Despite the importance of what vectors enable, they are not a guarantee of accuracy.
Vectors can improve the accuracy of a generative AI application. They can help retrain a public LLM with proprietary data so that an organization can use the generative AI capabilities of the public LLM to analyze its data. They can also help inform a private language model by making sure it has enough data to largely avoid AI hallucinations.
But there's a significant caveat.
No matter how much data is used to train an application, its accuracy remains most dependent on the quality of the data. If the data is inaccurate, the application will be inaccurate as well.
"If you have inaccurate data, it doesn't matter how good the model is," Dremio's Merced said. "Data quality has become super important this year because of GenAI. Everyone wants to build generative AI models, so now all of the data quality talk we've been having for years really matters. We can't build these models if we don't do those hard things that we should have been doing for years."
As a result, there has been new emphasis on data observability, data lineage and other enablers of data quality, he continued.
"These used to be boring things that make data a little bit better," Merced said. "But now people realize their data needs to be better or they can't build these cutting-edge tools. DataOps is going to be a very big story this coming year because of that."
Petrie likewise noted the importance of data quality in determining whether generative AI applications deliver accurate responses.
"This stuff is easier said than done," he said. "Companies have struggled with data quality issues for decades. They need to implement the right data observability and data governance controls to ensure they're feeding accurate content into the vector databases. They also need to make sure their vectors properly characterize the features of their content."
In fact, that proper characterization of features -- the quality of the algorithms that assign vectors -- is perhaps as important as data quality in determining the effectiveness of a generative AI application, according to Farmer.
If an algorithm is written well, and similar words such as mutt and hound are assigned similar vectors, a vector search will discover the similarity. But if an algorithm is written poorly, and the numbers assigned to those words and others such as dog and pooch don't correspond to one another, a vector search won't discover the similarity.
"Vector search algorithms are improving all the time," Farmer said. "None of this would work without vector search being effective."
Nevertheless, with vagaries in algorithms, vector searches aren't foolproof and can result in AI hallucinations.
"They are very effective at getting the most mathematically correct answer, but they have to get feedback and get retrained to know if that is the most accurate in human terms," Farmer said. "That's why they're constantly asking for feedback, and models are constantly being retrained."
Outlook
After quickly becoming a critical capability as organizations develop pipelines to feed generative AI models, vector search will likely continue to gain momentum, according to Petrie.
But beyond vendors developing and providing vector search capabilities, more organizations will actually use them in the coming year.
"I think many companies will adopt or expand their usage of vector databases as they ramp up their investments in generative AI," Petrie said.
Similarly, Merced predicted that adoption of vector search and storage capabilities will continue increasing.
"The general trend of everything is making it easier to use data and making data more accessible and more open," he said. "So, I'm optimistic that vectors will continue to be a big thing."
Farmer noted that new technologies are being developed that, like vector search, will help discover the data needed to train generative AI applications.
OpenAI reportedly is developing a platform called Q* -- pronounced "Q-Star" -- that's more powerful than ChatGPT and better at solving math equations.
"We're at the stage where there are rumors of new technologies coming out," Farmer said. "But anybody who's got one is keeping it pretty quiet."
Meanwhile, there is plenty of room for vector search to grow and improve, and help generative AI do the same, he continued.
"We've seen a huge improvement in GenAI over the course of a year," Farmer said. "That hasn't been driven by new technology. That has been driven by existing technology, which is by no means at its peak. There's a lot of headroom left to reach in the technologies we have today."
Eric Avidon is a senior news writer for TechTarget Editorial and a journalist with more than 25 years of experience. He covers analytics and data management.