Blue Planet Studio - stock.adobe
RAG best practices for enterprise AI teams
Many organizations are already using commercial chatbots driven by large language models, but adding retrieval-augmented generation (RAG) can improve accuracy and personalization.

Large language models are designed to respond to almost any question. But those responses aren't necessarily grounded in verified or up-to-date information.
Retrieval-augmented generation enables generative AI applications to access external knowledge stores -- a particularly useful approach for enterprises seeking to use their proprietary data. By implementing RAG as part of a broader generative AI strategy, organizations can create AI applications that use internal, current knowledge while maintaining accuracy, security and regulatory compliance.
To get started, explore RAG architecture fundamentals, benefits and challenges. Then walk through a six-step best practices checklist and review tips for enterprise adoption.
The main features of RAG
In a non-RAG generative AI application, a large language model (LLM) draws exclusively on what it has learned from its training data: billions of parameters encoding statistical patterns mined from public data sets. The model responds to prompts based on calculations about what is most likely to be the next word. However, an LLM does not have access to any information past the cutoff date of its training data, nor anything proprietary to a given business. It is a freestanding prediction engine.
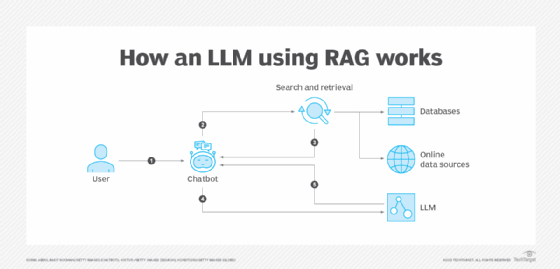
RAG changes this process by incorporating external data for the LLM to access in real time when answering a query. The RAG process comprises three stages: retrieval, augmentation and generation.
1. Retrieval
When a user asks a question, a RAG architecture does not immediately generate an answer from the LLM's existing internal knowledge. Instead, it first searches predefined knowledge repositories, such as internal documents, reports, curated databases or web sources. Retrieval is not guessing; it is a process of directed information-seeking to locate information that might be relevant to the query.
2. Augmentation
The retrieved documents are then fed into the context window of information that the LLM uses to answer the user's question. Augmentation injects live, specific and often proprietary information into the model's short-term memory, temporarily modifying the model's knowledge to help it answer the question.
3. Generation
The LLM begins crafting a natural-language response after retrieval and augmentation. Generation draws simultaneously on the model's general language abilities and the retrieved data. The model no longer responds based solely on internal knowledge; instead, it responds based on retrieved facts relevant to the business and the user's query.
Considerations for RAG in the enterprise
RAG addresses three critical limitations of typical LLMs:
- Knowledge cutoffs. LLMs have training data cutoff dates after which they are unaware of world events or company developments. RAG gives models access to recent and relevant data past those cutoff points.
- Hallucinations. LLMs sometimes generate incorrect information when asked questions outside their knowledge base. RAG reduces the risk of hallucination, although it still can occur.
- Proprietary knowledge. Standard LLMs cannot access an organization's internal data, documents and expertise. RAG enables the LLM to use specified company data.
While RAG offers many benefits, enterprise implementations also face challenges such as the following:
- Data security and privacy. Enterprise data contains sensitive information that may be subject to industry regulations and company policies.
- Complex information landscapes. Large organizations typically have vast document repositories spread across multiple systems, with varying levels of structure and quality.
- Integration requirements. Enterprise RAG systems must connect with existing legacy IT infrastructure, authentication systems and content management platforms.
- Scale and performance demands. Enterprise applications might need to handle thousands of concurrent users while maintaining low latency.
- Governance and compliance. Not only does legislation increasingly govern the use of AI, but regulated sectors often must align with industry codes of practice and internal standards.
Checklist: 6 RAG best practices
To get the most out of RAG, adopt these six best practices.
1. Create a data preparation strategy
Before thinking about retrieval, you need a data strategy. Focus first on surfacing your most valuable sources, such as knowledge bases, reports, customer call transcripts and even overlooked internal wikis. Then, build a repeatable data preparation pipeline:
- Filter out irrelevant or outdated information.
- Break documents into appropriately sized segments.
- Clean and standardize text formats.
- Extract and preserve metadata.
- Use version control for document updates.
A data preparation strategy is not a one-time effort but an ongoing process. You also need automated workflows to continuously update knowledge bases as new information becomes available.
2. Choose a vector database
Vector embeddings are essential for retrieval. When processing a document, the LLM doesn't just store the raw text for keyword matching. Instead, it passes the text through an embedding model: a neural network trained to translate language into arrays of numbers called high-dimensional vectors.
Think of two sentences that mean similar things but use different words. Vector embeddings map these to nearby points in space. For example, "How can I reset my password?" and "I forgot my login credentials. How do I recover access?" are not similar in their keywords. But they are close together in embedding space because their meanings overlap.
A vector database stores document embeddings and thus enables similarity searches for related meanings -- an essential aspect of RAG. Popular options include Pinecone, Weaviate, Milvus and Qdrant, though many organizations also use vector capabilities in their existing database platforms.
When selecting a vector database, consider the following:
- Scalability for when successful projects result in higher usage.
- Query performance for expected load.
- Security features, including encryption and access controls.
- Integration capabilities with existing data ecosystems and architecture.
- Operational requirements and maintenance overhead.
3. Develop a retrieval strategy
Effective retrieval is crucial for RAG performance, and many projects stumble here. The goal is to retrieve relevant information, but too much data can create noise. The information returned should be comprehensive enough to answer user queries yet concise enough for the LLM to process effectively.
Consider the following retrieval best practices:
- Combine keyword and semantic similarity approaches with hybrid search.
- Rerank retrieved documents based on relevance: Not all "similar" documents are useful.
- Filter metadata to narrow search context.
- Use query reformulation techniques to improve search effectiveness.
- Create user feedback loops to continuously improve retrieval accuracy. With their unpredictable queries, real-world users often find issues in RAG that test teams overlook.
4. Ensure security and compliance
Security safeguards help ensure that a RAG system doesn't expose information or violate privacy regulations.
Security best practices include the following:
- Develop role-based access controls for both retrieval and generation.
- Track data lineage to identify data sources.
- Log all queries and responses for audit purposes.
- Use content filters to prevent exposure of sensitive information.
- Create clear, well-communicated policies for handling personally identifiable information.
5. Optimize prompt engineering
Don't treat prompt engineering like an end-user issue. Enterprises should define templates, citations and formats in advance. Effective steps include the following:
- Create standardized prompt templates for different use cases.
- Include clear instructions for source citation.
- Specify the expected format and level of detail in responses.
- Provide context about the user's role and access permissions.
- Test prompts systematically and iteratively.
Well-designed prompts help the LLM properly contextualize retrieved information and generate appropriate responses.
6. Govern RAG architecture rigorously
A RAG system's knowledge base can drift over time because information becomes outdated, contradicts new data or is biased due to selective usage.
Governance mechanisms help organizations maintain control over their RAG systems and continuously improve performance. An effective governance process includes the following:
- Monitor usage patterns and performance metrics with dashboards.
- Track the retrieved sources and keep an audit log of which sources are used.
- Evaluate user satisfaction and, for advanced teams, implement specific accuracy measures for generative AI.
- Identify and address potential biases in responses.
- Manage costs and resources, with alerts for spikes and overruns.
Integrating RAG into your generative AI roadmap
As you plan your generative AI projects, make RAG part of the early conversations with architecture and operational teams.
Look for focused use cases where high-quality, structured data is available. Customer support, internal knowledge management, process manuals and compliance documentation are good candidates.
Take a phased approach, beginning with a limited scope and expanding as you gain experience with RAG techniques. Develop in-house skills, especially in data preparation, vector embeddings and prompt engineering. Lastly, plan for integration with other AI capabilities -- such as fine-tuning and supervised learning -- that can complement RAG and improve the model's capabilities in areas specific to your business.
Donald Farmer is a data strategist with 30-plus years of experience, including as a product team leader at Microsoft and Qlik. He advises global clients on data, analytics, AI and innovation strategy, with expertise spanning from tech giants to startups.
Dig Deeper on AI business strategies
-
![]()
How to use AI agents for infrastructure management
By: Wisdom Ekpotu
-
![]()
How agentic RAG supports effective business workflows
By: Marius Sandbu
-
![]()
Cloudian launches object storage AI platform at corporate LLM
By: Antony Adshead
-
![]()
Understanding the limitations and challenges of RAG systems
By: Kashyap Kompella