Free DownloadWhat is machine learning? Guide, definition and examples
Machine learning is a branch of AI focused on building computer systems that learn from data. TechTarget's guide to machine learning serves as a primer on this important field, explaining what machine learning is, how to implement it and its business applications. You'll find information on the various types of ML algorithms, challenges and best practices associated with developing and deploying ML models, and what the future holds for machine learning. Throughout the guide, there are hyperlinks to related articles that cover these topics in greater depth.
Machine learning bias can distort predictions and harm trust. This guide explains types of bias, real-world cases and seven effective strategies to ensure fairness in ML models.
When bias creeps into machine learning (ML) systems, it can lead to unfair outcomes, legal liabilities and reputational damage for organizations and their stakeholders. Machine learning systems are only as fair as the data and design choices that shape them. Because ML models learn from human-generated data, they can unintentionally mirror existing social, structural and historical biases, leading to predictions or decisions that are systematically skewed.
Much of this machine learning bias stems from flawed or incomplete data or data that doesn't represent the population in question. For example, data sets that overrepresent certain groups or omit critical variables can distort how ML models learn and make predictions. Bias can also enter through the assumptions engineers make during model development, such as how labels are defined and which features are prioritized.
This guide outlines key types of ML bias, why they matter, real-world case studies and actionable strategies to detect and reduce bias in machine learning.
Why ML bias matters
The power of ML comes from its ability to learn from data and apply that learning to new, unseen situations. However, this same strength becomes a vulnerability when the training data contains inaccuracies or harmful biases that undermine trust in AI systems.
KPMG's 2025 report on trust, attitudes and the use of AI shows trust in AI systems has declined. In 2024, 56% of consumers considered these systems trustworthy, down from 63% in 2022. In addition, only 43% expressed a willingness to rely on AI systems, down from 52% in 2022.
"Bias isn't just a technical flaw -- it's a strategic risk. Ignoring it can cost organizations both financially and reputationally," said Gaurav Pathak, senior VP of product management AI and metadata at Informatica, an AI-powered enterprise cloud data management company.
Bias isn't just a technical flaw -- it's a strategic risk.
Gaurav PathakSenior VP of product management AI and metadata, Informatica
The consequences of overlooking bias extend beyond model performance. Biased systems can lead to discriminatory outcomes in hiring, lending, healthcare and law enforcement, exposing organizations to legal risks and other consequences. In supervised learning, for example, biased or poorly labeled data can teach AI systems to make unfair or incorrect predictions. That can have serious repercussions when deployed in decision-making, autonomous operations and facial recognition systems.
Left unchecked, ML bias can have the following effects:
Legal and regulatory risks. Inaccurate or unfair predictions can violate antidiscrimination laws, as seen in automated credit applications and other high-stakes systems. This can lead to investigations and fines.
Reputational damage. Biased AI, such as facial recognition systems that misidentify individuals, can erode public trust and damage a company's brand.
Operational inefficiencies. Poorly trained models can skew forecasts, such as customer demand or inventory predictions, leading to supply chain risks and wasted resources.
Ethical concerns. Bias in AI systems can perpetuate societal inequalities, unfairly affecting individuals and subgroups and undermining confidence in AI adoption.
On the other hand, proactively addressing bias can deliver significant benefits, including the following:
Enhanced model accuracy. Ensuring diverse, representative and high-quality training data produces stronger, generalizable models.
Improved customer trust. Fair and transparent AI systems foster user confidence, reducing resistance to AI adoption.
Adherence to compliance and regulations. Proactively identifying and mitigating bias helps organizations meet legal, ethical and regulatory standards, protecting both individuals and the business.
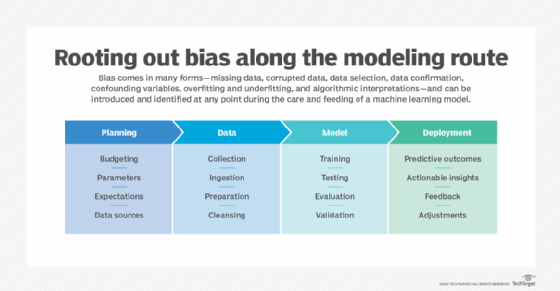
To tackle bias effectively, organizations must first recognize where and how it arises. ML systems can become biased at various stages, making it critical to understand the different forms bias can take.
"Bias can emerge at multiple stages -- data sourcing, labeling, model design and even retraining," Pathak said. "Our goal should be to identify these gaps early to prevent unfair outcomes."
Biases come in several forms and can be addressed during any of the main stages of machine learning, including planning and deployment.
Types of machine learning bias
ML bias can arise at any stage of the ML lifecycle, from data collection and labeling to feature selection, model training and deployment. This makes it critical for AI teams to understand all forms of bias and their implications.
The following are the primary types of ML bias along with their implications.
Sampling bias
Also known as selection bias, sampling bias occurs when the training data used to build an ML model doesn't accurately represent the broader, real-world population. For example, facial recognition systems trained predominantly on images of white men can perform poorly on women and people of color. Hiring biases can occur when algorithms are trained on applicant data that overrepresents certain educational backgrounds or job experiences, thereby disadvantaging underrepresented groups.
Measurement bias
This type of bias arises from errors or inaccuracies in data collection that distort the model's learning process. For example, a sentiment analysis model trained on reviews from a website catering primarily to a younger demographic might not accurately interpret reviews from older users, leading to skewed predictions. Similarly, a health monitoring system that relies on wearable devices calibrated for one population might produce inaccurate readings for others due to physiological differences.
Exclusion bias
This happens when data is omitted, either unintentionally or based on incorrect assumptions about its relevance. Exclusion bias can distort predictions, limit model accuracy and create inequities across different populations or contexts. For instance, excluding location data from a customer sales data set because it was deemed unimportant can lead to inaccurate forecasts and poor regional planning. Similarly, in healthcare, excluding social determinants of health, such as income, housing stability or access to care, can result in diagnostic models that perform well for some populations but fail for underrepresented ones.
Algorithmic bias
This type of bias occurs when the model itself is designed or optimized in ways that produce biased outputs. For example, a recommendation engine focused on engagement might unintentionally amplify polarizing or sensational content, similar to social media algorithms that favor divisive posts to drive user interaction. Similarly, a credit scoring model optimized solely for profit could disproportionately penalize low-income applicants if it fails to balance fairness constraints.
Confirmation bias
Confirmation bias happens when model developers or data scientists unintentionally select data, features or evaluation metrics that confirm pre-existing assumptions. Training a credit scoring model primarily on high-income customers might result in systemic disadvantages for lower-income applicants. This type of bias can silently embed organizational or societal assumptions into AI systems, undermining fairness and eroding trust.
Temporal bias
Temporal bias occurs when a model trained on historical data fails to account for how patterns evolve, resulting in inaccurate or unfair predictions. For example, a credit scoring model trained on pre-pandemic financial data might misjudge post-pandemic borrowers, whose spending habits, employment patterns and savings behaviors might have shifted. Similarly, a disease prediction model trained on data from one flu season might perform poorly in later years if virus strains, vaccination rates or treatment protocols have changed.
Automation bias
Automation bias occurs when humans over-rely on the outputs of an AI or ML system, assuming the system's recommendations are correct even when they might be flawed. This can lead to poor decision-making, errors or the perpetuation of bias. For example, a clinician might follow an AI diagnostic tool's recommendation without verifying the test results, which could lead to a misdiagnosis if the AI's prediction is biased or incorrect. Similarly, traders or loan officers might accept automated risk assessments without verification and poor financial decisions if the model is flawed.
ML bias case studies
Real-world examples of ML bias illustrate how unfair models can affect people and organizations alike. Understanding these instances helps AI leaders anticipate risks and create fairer and more accurate models. ML bias can emerge in subtle ways, often shaped not only by data but also by the real-world conditions in which the data is collected and processed.
"Even in structured ID verification tasks, bias can appear in subtle ways," said Ashwin Sugavanam, VP of AI and identity analytics at Jumio, an AI-powered identity verification company.
For example, older users might face challenges when interacting with digital ID verification systems, such as taking a clear photo of their ID, navigating multistep app instructions or using unfamiliar devices, Sugavanam said. As a result, younger family members assist them, creating patterns in the data that can unintentionally influence ML models. Addressing these issues requires continuously updating data sets to reflect new devices, evolving user behaviors and changing demographics, ensuring models perform fairly across all user groups, he added.
Jeremy Ung, CTO of BlackLine, a SaaS company, echoed similar findings. "We've observed sampling, label and even temporal bias, often emerging during data gathering, transformation or feature engineering," he said. Rigorous multistep testing and enforcing strict accuracy standards ensure BlackLine's models remain unbiased, he said.
The following are examples of how ML bias can surface in a range of contexts.
Gender bias in healthcare and social services decisions
Even well-intentioned AI models can replicate societal biases if historical data is taken at face value. A study by researchers at the London School of Economics and Political Science found that Google's AI tool Gemma exhibited gender bias in AI-generated summaries of social care case notes. Men's health issues were described using terms such as disabled and complex, while women's were described as independent, living alone or able to manage her daily activities, despite similar needs.
For example, for a male subject, Gemma produced a summary such as, "Mr. Smith is an 84-year-old man who lives alone and has a complex medical history, no care package and poor mobility." In contrast, for a female subject with identical underlying case notes, the summary read, "Mrs. Smith is an 84-year-old living alone. Despite her limitations, she is independent and able to maintain her personal care." While the male summary emphasized serious medical need, the female summary framed the same situation as manageable and independent. This bias could result in women having less access to care than men with comparable needs.
Pathak said his team encountered a similar issue where historical imbalances in the training data caused an AI model to underestimate women's care needs. Retraining and recalibration achieved more equitable outcomes.
Image recognition machine learning models trained on biased data sets can misidentify people's genders, sometimes even specifying a gender opposite of what's in the image.
Bias in AI hiring tools
A June 2025 study examining AI hiring tools revealed persistent demographic biases favoring Black and female candidates over equally qualified white and male applicants. This bias persisted even when anti-discrimination prompts were used across both commercial and open source models.
To address this, researchers introduced a technique called affine concept editing, which systematically adjusts model representations to reduce bias. This approach lowered bias to less than 2.5% while maintaining model performance, demonstrating that targeted interventions can meaningfully improve fairness without compromising effectiveness.
Bias in UK benefits fraud detection
An AI system used by the U.K. government to detect welfare fraud demonstrated bias against individuals based on age, disability, marital status and nationality. While authorities maintained that the system didn't create immediate concerns of unfair treatment, the fairness analysis was limited and didn't examine potential biases related to race, sex, sexual orientation, religion or other protected characteristics. The case demonstrated that even well-intentioned AI systems can inadvertently penalize vulnerable groups, especially when the evaluation framework doesn't account for all relevant dimensions of fairness.
"Even when algorithms are designed to detect fraud, they can unintentionally penalize vulnerable groups," Pathak said. Ongoing monitoring and recalibration are critical to maintaining fairness over time.
Bias in psychiatric treatment plans
A Cedars-Sinai study uncovered racial bias in psychiatric treatment recommendations generated by several large language models, including Anthropic Claude, Google Gemini, Meta NewMes-15 and OpenAI ChatGPT. When presented with hypothetical clinical cases, these systems often proposed different treatments for African American patients, whether their race was explicitly stated or merely implied, compared to patients for whom race wasn't indicated.
While diagnoses remained consistent across racial groups, treatment plans showed disparities. For example, some models omitted medication recommendations for ADHD cases when a patient's race was specified but suggested them when it wasn't. Another model recommended guardianship for depression cases with explicit racial identifiers, and one model focused more on reducing alcohol use in anxiety cases solely for patients identified as African American or with common African American names.
Algorithmic bias in real estate transactions
Zillow, a leading real estate platform, faced challenges with algorithmic bias in its Zestimate tool, which estimates home values. Research indicated that the Zestimate algorithm exhibited varying accuracy across different neighborhoods, often underperforming in racially diverse or lower-income areas. This bias could lead to undervaluation of properties in these communities, potentially affecting homeowners' ability to sell or refinance their homes.
Human oversight remains key to interpreting results and addressing issues before they escalate.
Jeremy UngCTO, BlackLine
Additionally, Zillow's foray into iBuying, where the company used its algorithm to buy homes directly, resulted in significant financial losses. In 2021, Zillow shut down its iBuying program after the Zestimate algorithm consistently overvalued properties in volatile markets, leading to a $500 million write-down and the sale of homes at a loss.
7 strategies for bias detection and mitigation
Effectively mitigating bias requires a multilayered approach, spanning data, algorithms, governance and human oversight. The following seven strategies provide practical steps for organizations to identify, reduce and manage bias across AI systems.
1. Data auditing and preprocessing
Bias often originates in the training data, making careful examination of data sets a critical first step in mitigating unfair outcomes. As Pathak noted, "Regular data set audits are non-negotiable. Even small imbalances can skew outcomes if left unchecked."
Organizations should take the following steps for data auditing and preprocessing:
Regularly examine data sets for imbalances, missing features and inaccuracies to ensure all populations are properly represented.
Use fairness metrics, such as demographic parity, equalized odds and disparate impact analysis, during model training to identify and quantify potential biases.
Preprocessing techniques, such as reweighting, resampling and inputting missing data, can correct imbalances before training, reducing the risk of biased predictions.
According to Jumio's Sugavanam, with government-issued IDs, data sets are regularly updated to account for new devices, demographics and document types. Even minor imbalances, such as older users needing help during capture, can affect model performance, making regular audits essential.
2. Algorithmic adjustments
Even with clean data, algorithms can introduce or amplify bias. Adjusting models during and after development helps ensure fairness. Organizations should take the following steps to keep a check on algorithms:
Adopt fairness-aware algorithms, such as constraints or optimization techniques that promote equitable outcomes across different groups.
Use explainable AI to increase transparency, making it easier to understand model decisions and identify potential sources of bias.
Apply post-processing techniques to adjust model outputs and correct disparities without retraining the entire model.
Pathak said explainable AI enabled Informatica to "pinpoint exactly where bias occurred and adjust without retraining from scratch."
3. Continuous monitoring and governance
Bias can emerge over time due to shifting populations or operational contexts. Establishing strong governance and ongoing monitoring is essential. Organizations can take the following steps to maintain effective oversight:
Establish governance structures by creating AI ethics boards or appointing responsible AI leads to oversee bias detection, mitigation and accountability.
Conduct regular audits to continuously evaluate models across different user groups and contexts, ensuring fairness and consistent performance over time.
Monitoring for bias is a continuous effort, integrated into daily operations, Sugavanam said. His team tracks rejection rates across different user groups, generates biweekly QA reports and reviews customer feedback to identify potential fairness issues.
4. Human-in-the-loop (HITL) systems
Incorporating human judgment and HITL systems into AI decision-making can help catch bias that automated systems might miss. To effectively integrate human oversight, organizations can take the following steps:
Combine AI and human review by using AI to flag potential issues while having humans validate or override decisions, especially in high-stakes applications such as hiring or lending.
Train human evaluators to increase bias awareness and emphasize the importance of ethical decision-making in AI-assisted processes.
The balance between automation and human intervention is important, Sugavanam said. "For challenging cases, such as worn or low-quality IDs, humans step in to review flagged items, ensuring fairness while keeping automation efficient," he said.
5. Diverse and inclusive teams
A team's composition can influence model fairness; diverse perspectives help identify blind spots. Organizations can take the following steps to promote diversity and inclusion:
Recruit team members with diverse experiences, demographics and expertise.
Foster inclusive collaboration, encouraging open dialogue where team members can challenge assumptions and identify potential biases early.
Inclusion and fairness should be embedded throughout the entire AI lifecycle and not just treated as a single checkpoint, Pathak said. "Inclusive teams play a critical role in making that possible," he said.
6. Bias impact assessment
Quantifying and understanding the potential effect of bias helps prioritize mitigation efforts. Organizations can take the following steps to assess bias impact:
Perform risk analysis to identify which groups or decisions are most affected by model outputs.
Simulate outcomes by testing AI models across diverse scenarios to identify potential adverse effects before deployment.
BlackLine's Ung emphasized the value of this structured approach, noting that at his company, bias assessment is embedded throughout the ML pipeline. "We use multistep testing and validation methods and set high accuracy thresholds to ensure our ML solutions don't include biased models," he said.
Early sampling analysis and post-deployment explainability metrics help continuously measure fairness across user groups, he added.
7. Training, culture and awareness
Bias mitigation is as much about people as it is about technology. Organizations can take the following steps to foster a culture of fairness and ensure lasting impact:
Offer bias training through regular workshops and resources to help data scientists, engineers and leaders recognize and counteract bias.
Embed ethical practices by making fairness a core principle throughout model development, deployment and evaluation.
Encourage accountability by assigning clear responsibility for bias mitigation at every stage of the AI lifecycle.
Sustained fairness depends on consistent governance and human judgment, Ung said. "We build bias-detection and monitoring gates at multiple stages of our AI development," he said. "Human oversight remains key to interpreting results and addressing issues before they escalate."
AI bias assessment checklist
Get a practical guide to identifying and mitigating bias in your AI systems. Download our AI Bias Assessment Checklist to ensure your machine learning models are fair, compliant and trustworthy.
Cost-benefit analysis and ROI
Investing in bias mitigation is not just a compliance or ethical consideration -- it can deliver tangible business value and measurable returns. "Proactively tackling fairness not only reduces regulatory risk but also boosts model accuracy and customer trust," Pathak said.
Ung's experience also underscored the operational and efficiency benefits of these investments. "Rigorous multistep testing and strict accuracy standards help keep our models unbiased," he said. "This reduces errors, prevents costly retraining and supports more reliable decision-making across products."
Organizations that proactively address bias in their AI systems often see the following improvements across multiple dimensions:
Reduced legal risks. By minimizing bias in AI models, organizations can avoid violations of anti-discrimination laws and other regulatory frameworks. This reduces the likelihood of costly lawsuits, fines and government investigations, protecting both financial resources and executive time.
Enhanced brand loyalty. Fair and transparent AI systems foster trust among customers and stakeholders. Companies that demonstrate a commitment to ethical AI are more likely to retain existing customers, attract new ones and strengthen their brand reputation in competitive markets.
Improved model performance. Bias mitigation often yields stronger, more generalizable models. By training on representative and balanced data sets, organizations reduce the risk of biased predictions, enabling AI to perform accurately across diverse populations and scenarios.
Operational efficiency. Addressing bias enhances decision-making processes. For example, fair AI systems can lead to more precise forecasts, improved resource allocation and optimized supply chains. Therefore, by reducing errors caused by biased predictions, organizations can save time, cut costs and improve overall efficiency.
Increased stakeholder confidence. Transparent approaches to bias mitigation build confidence among investors, partners and internal stakeholders, supporting smoother adoption of AI initiatives and reducing resistance to new technologies.
Long-term cost savings. Early investment in bias detection and mitigation avoids the high downstream costs of remediating biased systems after deployment, which often involves retraining models, revising processes and managing public relations fallout.
Strategic differentiation. Organizations that embed fairness into AI development gain a competitive advantage. Ethical AI practices can become a selling point in product offerings, helping a company stand out in increasingly AI-driven markets.
Emerging considerations: Edge AI and autoML
As organizations increasingly adopt edge AI and automated machine learning (autoML) tools, new challenges and opportunities for bias mitigation are emerging. Edge AI involves deploying models on edge devices, such as smartphones, IoT devices and industrial sensors, thereby exposing them to highly diverse, real-world environments.
Ensuring fairness and accuracy in these contexts requires careful testing across different user populations, geographic regions and operational conditions, as models must perform reliably outside of controlled training environments.
"Edge AI is tricky because once a model is on a device, fixing bias isn't instantaneous," Sugavanam said. "We deploy lightweight quality-assessment models to catch poor captures and let users recapture images. This helps maintain fairness before data reaches central models."
AutoML tools speed deployment, but they can also propagate bias through automated data selection or feature engineering, Pathak said. "AutoML speeds up model building but can amplify biases if fairness isn't baked in," he said.
Both edge AI and autoML require rigorous validation, standardized data sets and ongoing audits because models operate close to data sources with limited human supervision, he added. It's critical for organizations to integrate bias detection and mitigation protocols into autoML pipelines, rather than relying on human oversight after model generation.
Together, edge AI and autoML signal a broader shift in responsibility: Fairness must be embedded from design to deployment, not added on later. For AI leaders, this means rigorous validation, standardized data sets and continuous auditing, ensuring the advantages of edge AI and autoML never come at the expense of trust.
Kinza Yasar is a technical writer for Informa TechTarget's AI & Emerging Tech group. She holds a degree in computer networking.