Machine learning regularization explained with examples
Regularization in machine learning refers to a set of techniques used by data scientists to prevent overfitting. Learn how it improves ML models and prevents costly errors.

What is regularization in machine learning?
Regularization in machine learning is a set of techniques used to ensure that a machine learning model can generalize to new data within the same data set. These techniques can help reduce the impact of noisy data that falls outside the expected range of patterns. Regularization can also improve the model by making it easier to detect relevant edge cases within a classification task.
Consider an algorithm specifically trained to identify spam emails. In this scenario, the algorithm is trained to classify emails that appear to be from a well-known U.S. drugstore chain and contain only a single image as likely to be spam. However, this narrow approach runs the risk of disappointing loyal customers of the chain, who were looking forward to being notified about the store's latest sales. A more effective algorithm would consider other factors, such as the timing of the emails, the use of images and the types of links embedded in the emails to accurately label the emails as spam.
This more complex model, however, would also have to account for the impact that each of these measures added to the algorithm. Without regularization, the new algorithm risks being overly complex, subject to bias and unable to detect variance. We will elaborate on these concepts below.
In short, regularization pushes the model to reduce its complexity as it is being trained, explained Bret Greenstein, data, AI and analytics leader at PwC.
 Bret Greenstein
Bret Greenstein
"Regularization acts as a type of penalty that gets added to the loss function or the value that is used to help assign importance to model features," Greenstein said. "This penalty inhibits the model from finding parameters that may over-assign importance to its features."
As such, regularization is an important tool that can be used by data scientists to improve model training to achieve better generalization, or to improve the odds that the model will perform well when exposed to unknown examples.
The purpose of regularization
Adnan Masood, chief architect of AI and machine learning at digital transformation consultancy UST, said his firm frequently uses regularization to strike a balance between model complexity and performance, adeptly steering clear of both underfitting and overfitting.
Overfitting occurs when a model is too complex and learns noise in the training data. Underfitting occurs when a model is too simple to capture underlying data patterns.
"Regularization provides a means to find the optimal balance between these two extremes," Masood said.
Consider another example of the use of regularization in retail. In this scenario, the business wants to develop a model that can predict when a certain product might be out of stock. To do this, the business has developed a training data set with many features, such as past sales data, seasonality, promotional events, and external factors such as weather or holidays.
This, however, could lead to overfitting when the model is too closely tied to specific patterns in the training data and as a result might be less effective at predicting stockouts based on new, unseen data.
"Without regularization, our machine learning model could potentially learn the training data too well and become overly sensitive to noise or fluctuations in the historical data," Masood said.
In this case, a data scientist might apply a linear regression model to minimize the sum of the squared difference between actual and predicted stockout instances. This discourages the model from assigning too much importance to any one feature.
 Adnan Masood
Adnan Masood
In addition, they might assign a lambda parameter to determine the strength of regularization. Higher values of this parameter increase regularization and lower the model coefficients (weights of the model).
When this regularized model is trained, it will balance fitting the training data and keeping the model weights small. The result is a model that is potentially less accurate on the training data and more accurate when predicting stockouts on new, unseen data.
"In this way, regularization helps us build a robust model, better generalizes to new data and more effectively predicts stockouts, thereby enabling the business to manage its inventory better and prevent loss of sales," Masood said.
He finds that regularization is vital in managing overfitting and underfitting. It also indirectly helps control bias (error from faulty assumptions) and variance (error from sensitivity to small fluctuations in a training data set), facilitating a balanced model that generalizes well on unseen data.
Business benefits of regularization in machine learning
Niels Bantilan, chief ML engineer at machine learning orchestration platform Union.ai, finds it useful to think of regularization as a way to prevent a machine learning model from memorizing the data during training.
 Niels Bantilan
Niels Bantilan
For example, a home automation robot trained on making coffee in one kitchen might inadvertently memorize the quirks and layouts of that specific kitchen. It will likely break when presented with a new kitchen where ingredients and equipment differ from the one it memorized.
In this case, regularization forces the model to learn higher-level concepts like "coffee mugs tend to be stored in overhead cabinets" rather than learning specific quirks of the first kitchen, such as "the coffee mugs are stored in the top left-most shelf."
In business, regularization is important to operationalizing machine learning, as it can mitigate errors and save cost, since it is expensive to constantly retrain models on the latest data.
"Therefore, it makes sense to ensure they have some generalization capacity beyond their training data, so the models can handle new situations up to a certain point without having to retrain them on expensive hardware or cloud infrastructure," Bantilan said.
Key concepts in regularization, explained
What is overfitting?
The term overfitting is used to describe a model that has learned too much from the training data. This can include noise, such as inaccurate data accidentally read by a sensor or a human deliberately inputting bad data to evade a spam filter or fraud algorithm. It can also include data specific to that particular situation but not relevant to other use cases, such as a store shelf layout in one store that might not be relevant to different stores in a stockout predictor.
What is underfitting?
Underfitting occurs when a model has not learned to map features to an accurate prediction for new data. Greenstein said that regularization can sometimes lead to underfitting. In that case, it is important to change the influence that regularization has during model training. Underfitting also relates to bias and variance.
What is bias?
Bantilan described bias in machine learning as the degree to which a model's predictions agree with the actual ground truth. For example, a spam filter that perfectly predicts the spam/not-spam labels in training data would be a low-bias model. It could be considered a high-bias model if it was wrong all the time.
What is variance?
Variance characterizes the degree to which the model's predictions can handle small perturbations in the training data. One good test is removing a few records to see what happens, Bantilan said. If the model's predictions remain the same, then the model is considered a low-variance model. If the predictions change wildly, then it is considered a high-variance model.
Greenstein observed that high variance could be present when a model trained on multiple variations of data appears to learn a solution but struggles to perform on test data. This is one form of overfitting, and regularization can assist with addressing the issue.
Examples of machine regularization in industry
Bharath Thota, partner in the advanced analytics practice of Kearney, a global strategy and management consulting firm, said that some of the common use cases in industry include the following:
 Bharath Thota
Bharath Thota
- Manufacturing. Regularization can improve predictive maintenance models by honing their ability to accurately identify and preempt equipment malfunctions.
- Retail. In the realm of demand forecasting models, regularization can augment the precision of inventory predictions, leading to more efficient supply chain management.
- Healthcare. In the analysis of medical data, regularization is used to bolster the accuracy of disease detection, thereby minimizing the incidence of false positives.
Problems regularization can help solve
Regularization needs to be considered as a handy technique in the process of improving ML models rather than a specific use case. Greenstein has found it most useful when problems are high-dimensional, which means they contain many and sometimes complex features. These types of problems are prone to overfitting, as a model might fail to identify simplified patterns to map features to objectives.
Regularization is also helpful with noisy data sets, such as high-dimensional data, where examples vary a lot and are subject to overfitting. In these cases, the models might learn the noise rather than a generalized way of representing the data.
It is also good for nonlinear problems since problems that require nonlinear algorithms can often lead to overfitting. These kinds of algorithms uncover complex boundaries for classifying data that map well to the training data but are only partially applicable to real-world data.
Greenstein noted that regularization is one of many tools that can assist with resolving challenges from an overfit model. Other techniques, such as bagging, reduced learning rates and data sampling methods, can complement or replace regularization, depending on the problem.
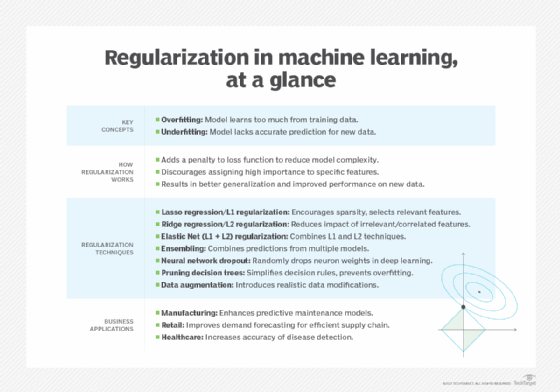
Machine regularization techniques
There are a range of different regularization techniques. The most common approaches rely on statistical methods such as lasso regularization (also called L1 regularization), ridge regularization (L2 regularization) and elastic net regularization, which combines both Lasso and Ridge techniques. Various other regulation techniques use different principles, such as ensembling, neural network dropout, pruning decision tree-based models and data augmentation.
Masood said the choice of regularization method and tuning for the regularization strength parameter -- lambda -- largely depends on the specific use case and the nature of the data set.
"The right regularization can significantly improve model performance, but the wrong choice could lead to underperformance or even harm the model's predictive power," Masood cautioned. Consequently, it is important to approach regularization with a solid understanding of both the data and the problem at hand.
Here are brief descriptions of the common regularization techniques.
Lasso regression (L1 regularization). The lasso regularization technique, an acronym for least absolute shrinkage and selection operator, is derived from calculating the median of the data. A median is a value in the middle of a data set. It calculates a penalty function using absolute weights. Kearney's Thota said this regularization technique encourages sparsity in the model, meaning it can set some coefficients to exactly zero, effectively performing feature selection.
Ridge regression (L2 regularization). Ridge regulation is derived from calculating the mean of the data, which is the average of a set of numbers. It calculates a penalty function using a square or other exponent of each variable. Thota said this technique is useful for reducing the impact of irrelevant or correlated features and helps in stabilizing the model's behavior.
Elastic net (L1 + L2) regularization. Elastic net combines both L1 and L2 techniques to improve the results for certain problems.
Ensembling. Ensembling combines the predictions from a suite of models, thus reducing the reliance on any one model for prediction.
Neural network dropout. Neural network dropout involves randomly dropping out the weights of some neurons. It is sometimes used in deep learning algorithms comprised of multiple layers of neural networks. Bantilan said this forces the deep learning algorithm to learn an ensemble of sub-networks to achieve the task effectively.
Pruning decision tree-based models. Pruning decision tree-based models is used in tree-based models such as decision trees. The process of pruning branches can simplify the decision rules of a particular tree to prevent it from relying on the quirks of the training data.
Data augmentation. Data augmentation uses prior knowledge about the data distribution to prevent the model from learning the quirks of the data set. For example, in an image classification use case, you might flip an image horizontally, introduce noise, blurriness or crop an image. "As long as the data corruption or modification is something we might find in the real world, the model should learn how to handle those situations," Bantilan said.
Editor's note: This article was updated in July 2024 to improve the reader experience.
George Lawton is a journalist based in London. Over the last 30 years he has written more than 3,000 stories about computers, communications, knowledge management, business, health and other areas that interest him.
Dig Deeper on AI technologies
-
![]()
Generative AI ethics: 16 biggest concerns and risks
By: George Lawton
-
![]()
Regression in machine learning: A crash course for engineers
By: Stephen Bigelow
-
![]()
Sample Questions for AWS' Machine Learning Associate Certification
By: Cameron McKenzie
-
![]()
Certified GCP Data Engineer Sample Questions and Answers
By: Cameron McKenzie



