How engineers can build a machine learning model in 8 steps
Building a machine learning model is a multistep process involving data collection and preparation, training, evaluation and ongoing iteration. Follow these steps to get started.

Machine learning (ML) is a foundational technology for modern AI, transforming the operational landscape of contemporary businesses. ML technology uses data to find patterns, spot anomalies and make decisions to enhance efficiency, drive business value and deliver ROI. This, in turn, mitigates risks, increases revenue and identifies competitive opportunities.
Google's report, The ROI of AI 2025, found that business leaders see the value of AI in productivity, customer experience, business growth, marketing and security. However, reaping the benefits of machine learning isn't easy.
Machine learning uses mathematical algorithms to create models that can learn from and process data. These ML models are rarely consistent; they're as unique and diverse as the organizations that use them.
Some general-purpose ML models are available as proprietary or open source components. However, business and technology leaders must expect to invest heavily in building, tailoring, training, testing, optimizing and monitoring ML systems and the AI entities built from ML models. When no suitable off-the-shelf ML models are available, businesses must develop in-house models.
To properly reap the benefits of machine learning, businesses must explore in-house ML development, the steps needed to build an ML model, development challenges, and metrics and key performance indicators (KPIs) that can help gauge the resulting model's success.
Reasons to build an ML model in-house
Dozens of available machine learning models and platforms can jumpstart an organization's ML and AI journey. Some open source examples are Keras, Scikit-learn, PyTorch and TensorFlow. However, licensing an existing ML model has limitations and runs the risk of reduced accuracy or suboptimal performance. Even the most well-developed publicly available ML model might not be right for a specific enterprise or project.
In-house ML model development is the best approach in some cases. The most compelling reasons to pursue in-house ML model development include the following:
- Model customization. In-house ML model development enables organizations to build models tailored to address the specific problems or goals of their business. This might include custom mathematical algorithms, support for certain data types and integration with other ML models, data sources and systems that would be impractical or prohibitive with off-the-shelf ML models.
- Vertical or domain expertise. In-house model development can bring together the collective knowledge of internal teams to provide precision and specificity to the ML model. This results in more accurate and efficient model performance compared to off-the-shelf models.
- Innovation and differentiation. Building an ML model in-house can be a competitive advantage, as it provides more unique outputs. For example, healthcare professionals are more likely to design and build models that yield accurate results for healthcare clinicians.
- Greater business agility. A proprietary ML model can result in vendor lock-in with dependency on the model's provider. Building and maintaining an ML model in-house lets teams tune, update, iterate and optimize models in response to changing business needs, market conditions and data. This provides the business with faster and more responsive control over the model.
- Better model governance and oversight. The common use of hosted models, such as popular large language models, can present data security and data privacy risks that affect an organization's governance and compliance posture. Building and hosting an ML model in-house gives the business control over the ML environment.
- Better integration. ML models depend on access to data stores, applications and systems for training and production data. Off-the-shelf models might not provide the necessary integrations, especially for older legacy systems. In-house models can be built to provide all the necessary integrations and bypass compatibility problems.
- Cost management. Hosted models typically charge subscription or per-use fees that can add up over time. Although the initial costs of an in-house ML model can be significant, the long-term costs associated with in-house development might be less.
8 steps to build a machine learning model
The approach used to build an ML model can be as diverse and unique as the business undertaking the project. However, a successful path typically involves the following eight steps:
1. Define tasks and goals
ML models aren't ubiquitous and are normally designed, built, deployed and maintained as task-specific software elements. The first step in any ML model development is to define the model's tasks or goals. This might involve performing analytics or interpreting spoken words.
It's also important to understand the business value of the ML model and how the model will bring about that value. Both determinations directly affect post-deployment monitoring and the metrics and KPIs used to measure the model's success.
2. Identify required data
Next, businesses must specify the model's data needs. Precisely what does the model need to know? For example, a model built for image classification will require image and video sources to train it and provide a data source for production.
Many sources can supply required data, including databases, file libraries, application programming interfaces and third-party sources. Data science teams must analyze initial training and testing data sources to understand the initial data composition, distribution and patterns. The data science team should also review initial data for bias and relevance.
3. Preprocess required data
Raw data rarely provides the quality and features that an ML algorithm can use directly. Data science teams must preprocess initial data for cleaning and feature engineering. Data cleaning identifies and resolves common data quality issues, including incomplete, inaccurate and irrelevant data elements.
Feature engineering transforms the cleaned data set into the values and scales that the ML algorithm needs. This preprocessed initial data set should be representative of the data provided in production, such as from IoT sensors or live video sources.
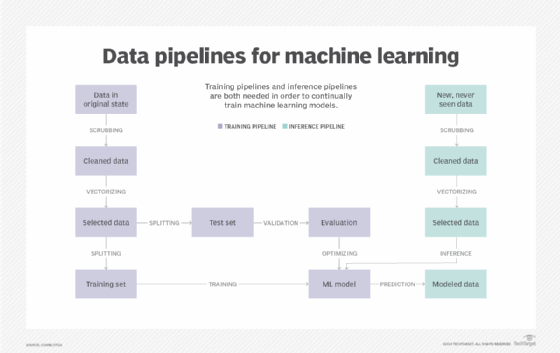
4. Create foundational data sets
The creation of an ML model involves three functional phases: training, validation and testing. Training data teaches the model. Validation data is used to fine-tune the model's hyperparameters and prevents overfitting, where the model has trouble providing results outside of its trained data. Testing data checks the model's performance with new, unseen data. The same data shouldn't be used for all three functional phases. Data sets can be version controlled to ensure reproducible outcomes and further compliance evaluation.
5. Build the model
Software development groups, such as a DevOps team, handle ML model development, training, validation, testing and deployment. They choose an algorithm, such as regression or decision tree, that's most appropriate for the model's goals.
As with any software project, the model should be version-controlled to ensure transparency and reproducibility. Some ML model projects benefit from experimentation, using several potential algorithms to determine the one with the best performance and accuracy.
6. Train and evaluate the model
The training data set enables the model to learn patterns and relationships that are key to its intended business task. The validation data set is used to test the model's hyperparameters. Models can be evaluated with various metrics and other measures, such as the Machine Intelligence Quotient. A key part of testing is to compare the model's performance against the current, nonmodel baseline.
7. Optimize the model
Models will typically benefit from some amount of optimization. For example, if the model doesn't perform well on nontraining data, it might be overfit and in need of hyperparameter adjustments until accuracy and performance are optimal. Similarly, it might be necessary to update or enhance training data to address gaps or mitigate ML bias. Finally, the model algorithm might need updates to improve performance or stability.
8. Deploy and monitor the model
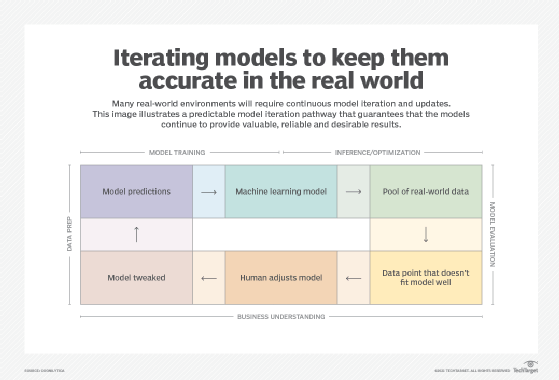
Once the ML model is well-developed and validated, teams can deploy it into production where it integrates with existing data sources and performs its tasks in real time. Metrics and KPIs should be applied to the model to provide ongoing measures of accuracy, performance and business value.
Data trends and business needs change over time, and this can cause the model to drift where its accuracy degrades. Metrics and KPIs serve as vital triggers to retrain or update the model. Changing business needs can provide new or updated goals, spawning a new set of steps to build an ML model.

Challenges of building an ML model
Despite the compelling justifications for building an ML model in-house, business and technology leaders must address and resolve several challenges before undertaking development. Common challenges and potential remediations include the following:
- Poor data quality. An ML mode is only as good as the training and production data available. Poor data quality leads to inaccurate or discriminatory outputs. Leadership teams should work closely with data science staff to ensure there's enough data; the data's provenance can be validated; and the data is accurate, consistent, complete and unbiased.
- Problematic data preprocessing. Raw data is rarely useful for ML model training without preprocessing to curate it into proper form. This typically involves cleaning data to remove inaccurate and redundant entries; transforming it to use consistent formats and data types; and extracting features from the data. Preprocessing is time- and processing-intensive, and it demands significant domain expertise from the data science team.
- Limited IT infrastructure. The business must store and process enormous data sets for both training and production data. Machine learning demands significant computational power, often requiring numerous servers with sophisticated processors, such as graphics processing units. These costly storage, network and computing resources often require scalability to maintain performance as data and user volumes increase over time. Many organizations opt to use the public cloud to ensure the necessary infrastructure is available on demand, although costs over time can become challenging.
- Complicated model selection. There are dozens of mathematical algorithms that have evolved to create ML models. Choosing the best algorithm and designing an optimal model to meet a particular ML goal can be a complex process that requires trial-and-error from software architects and developers. The software team should include architects with extensive expertise in ML algorithms and model design.
- Training and tuning issues. It's easy to overtrain a model, causing it to perform poorly on new or unseen data. It's also easy to overgeneralize a model, resulting in it only being able to handle new data at a simple level and not providing the precise distinctions needed. Further, the configuration that controls model learning can be difficult and time-consuming to optimize. This requires time and experimentation from the development team.
- Integration problems. ML models -- and the AI systems built from ML models -- must access data sources, hardware systems and enterprise applications. This makes integration a critical part of model design. Integration requires a thorough understanding of the production infrastructure, careful planning and consideration for future integration and compatibility needs. The software and IT infrastructure teams often collaborate to identify and understand integration issues.
- Reproducibility and explainability. As modern AI systems are tasked with more critical and autonomous business decisions, the need to trace or debug their decision-making and understand how model outputs are generated becomes vital to demonstrate fairness and transparency to clients, investors and regulators. Model design must result in consistent and explainable behavior to ensure trust and ethical operation of ML and AI systems. Collaboration with legal and compliance staff can clarify specific implications for the business.
- Ongoing monitoring and retraining. Building and deploying an ML model isn't a one-time task. Models demand constant monitoring to track performance, accuracy, detect bias and address data quality changes. There are many metrics to track model behavior, as well as KPIs to measure the model's business value. Selecting the right metrics and KPIs is difficult, and the business decisions to translate those measurements into model updates and retraining processes aren't always clear.
Machine learning model metrics and KPIs
An ML model must be coupled with suitable metrics and KPIs that provide an ongoing measure of its success. Metrics are practical measurements that detail how well the model performs. They're most valuable to technical staff and form the basis for future developments such as scaling, retraining, bias detection and remediation.
Typical ML metrics include accuracy, precision, recall and the F1-score, which is the mean of precision and recall. More complex metrics include a confusion matrix, area under the curve and receiver operating characteristic, root mean squared error and mean absolute percentage error. The choice and number of metrics applied to ML model monitoring varies depending on the sophistication and use of the model.
KPIs measure the model's broader business effects, so the organization can track how well the model helps meet strategic business objectives. KPIs help business leaders understand the correlation between ML investments and business outcomes.
Common ML KPIs include conversion rates, cost savings, customer churn and attrition, processing and transaction rates, ML pipeline automation, prediction latency, customer satisfaction and other engagement KPIs, and ultimately the ML ROI that compares a model's financial benefit with its cost of development, deployment and ongoing maintenance.
Businesses must routinely track both metrics and KPIs to provide a holistic view of a model's behavior and business value and to forecast potential problems, such as a falloff in accuracy that requires tuning and retraining the model.
Stephen J. Bigelow, senior technology editor at TechTarget, has more than 30 years of technical writing experience in the PC and technology industry.






