
What is a validation set? How is it different from test, train data sets?

What is a validation set in machine learning?
A validation set is a set of data used to train artificial intelligence (AI) with the goal of finding and optimizing the best model to solve a given problem. Validation sets are also known as dev sets.
Supervised learning and machine learning models are trained on very large sets of labeled data, in which validation data sets play an important role in their creation.
Training, tuning, model selection and testing are performed with three different sets of data: train, test and validation. Validation sets are used to select and tune the AI model.
Validation data sets use a sample of data that is withheld from training. That data is then used to evaluate any apparent errors. Machine learning engineers can then tune the model's hyperparameters -- which are adjustable parameters used to control the behavior of the model. This process acts as an independent data set for comparing the model's performance.
Even though validation data sets use training data for testing, it is not a part of either training or testing processes. This process acts as an unbiased evaluation of a model.
What are the differences between train, validation and test data sets?
Validation data sets are an important part of AI, machine learning and deep learning models, along with training and test data sets. These models use these data sets to identify and learn from data such as text images. After training, the models can be applied to areas such as text and image generation, natural language understanding or in the medical field. Testing, training and validation data sets are all used to prepare the model for operation, but are used at different points in its development:
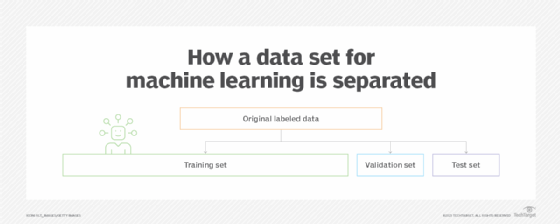
- The training set is the portion of data used to train models. The model learns from this data. In testing, the models are fit to parameters in a process that is known as adjusting weights. Training makes up most of the total data.
- Testing sets are only used when the final model is completely trained. These sets contain ideal data that extends to different scenarios the model would face in operation. This ideal set is used to test results and assess the performance of the final model.
- The validation set uses a subset of the training data to provide an unbiased evaluation of a model. The validation data set contrasts with training and test sets in that it is an intermediate phase used for choosing the best model and optimizing it. It is in this phase that hyperparameter tuning occurs. Overfitting is checked and avoided in the validation set to eliminate errors that can be caused for future predictions and observations if an analysis corresponds too precisely to a specific data set.
Model training with training, validation and test sets should be split depending on the number of data samples and the model being trained. Different models might require significantly more data to train than others. Likewise, the more hyperparameters there are, the larger the validation split needs to be. It is also generally considered unwise to attempt further adjustment past the testing phase. Attempting to add further optimization outside the validation phase will likely increase overfitting.
Learn more methods to evaluate and improve machine learning models.