How to avoid overfitting in machine learning models
Overfitting remains a common model error, but data scientists can combat the problem through automated machine learning, improving AI literacy and creating test data sets.
Overfitting is a common modeling error all enterprises who deploy machine and deep learning will encounter. When machine learning models allow noise, random data or natural fluctuations in data to dictate target functions, the model suffers in its ability to generalize new data beyond its training set.
Data scientists must build their models carefully, train them effectively, improve their machine learning literacy and instill incentive systems to combat overfitting.
Defining an overfitted model
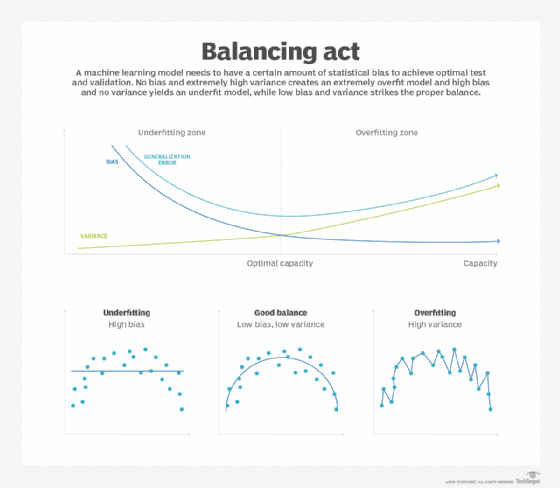
Training machine learning and deep learning models is rife with potential failure -- a major issue being Overfitting. Generally, overfitting is when a model has trained so accurately on a specific dataset that it has only become useful at finding data points within that training set and struggles to adapt to a new set.
In overfitting, the model has memorized what patterns to look for in the training set, rather than learned what to look for in general data. To a data scientist, the model appears to be trained effectively, but when brought against other datasets it is unable to repeat this success.
"We want the model to generalize well to unseen data," Benyamin Ghojogh, a graduate research assistant of machine learning and PhD candidate at the University of Waterloo, said.
For Ghojogh, avoiding overfitting requires a delicate balance of giving the right amount of details for the model to look for and train on, without giving too little information that the model is underfit.
"Something in the middle is good," Ghojogh said. "And that's a perfect fit, which can generalize to the new data and seen data."
But this is a difficult point to get your models to and one that becomes even more of an issue as your models become more complex.
"If you make the model complex but you don't have sufficient data to train it, the model will definitely get overfit and that's why neural networks are prone to it," Ghojogh said.
Ghojogh pointed out that all models must tackle the problem with overfitting, especially if the organization trains the model too much.
Overfitting and underfitting are common struggles in machine learning and deep learning models.
Rooting out overfitting in enterprise models
While getting ahead of the overfitting problem is one step in avoiding this common issue, enterprise data science teams also need to identify and avoid models that have become overfitted. But just as overfitting becomes more common as models grow in complexity, it also becomes more difficult to identify. Organizations who deploy neural networks and deep learning especially struggle with this step.
Forrester analyst Kjell Carlsson said that it has never been easier for overfitting to slip through the cracks. With the layers involved in deep learning, it's difficult to point out when and where a model has become over-trained.
With high demand on data and analytics in the enterprise, there's a time crunch on data science teams to deploy effective models. But as important as timeliness is, organizations have to implement processes and a culture that prioritizes machine learning effectiveness.
"You have to have very disciplined processes in your data science organization to go in and make sure that [you] are adhering to best practices," Carlsson said.
When it comes to model deployment, organizations need to work with their data science team. If a model isn't working or if the results aren't as promising as previously thought, Carlsson said, this is where communication becomes important. The relationship between data scientists and their organization can help determine if the model is functioning poorly due to overfitting, or the end-user application, over-hyped projections or another non-data-related cause.
The cost of overfitting and how to avoid it
Getting ahead of overfitting is crucial for model deployment. An overfitted model, when deployed against real-world data, will provide either no useable gains or false insights. Both cost an enterprise significant amounts of time, resources and buy-in from executives; and this cost grows even greater if the overfitted models' false insights go unnoticed and trusted.
As Gartner analyst Alex Linden put it, an overfitted model can render the insights from software or AI analysis useless. In the case of predictive maintenance, the system is not able to predict where or when the machine is going to fail. In predicting sales, the model will either be unable to predict whether somebody is going to react favorably to a selling proposition or will provide false positives.
Linden's prescription for this is testing. Running the model through numerous trials with different data sets is the best way to prove its capabilities to generalize rather than memorize. For Linden it is the number one way of avoiding overfitting and there are machine learning technologies that can ease this process of trial and error.
Mostly these days you can actually avoid overfitting by brute force, and the brute force capabilities of automated machine learning.
Alex LindenAnalyst, Gartner
"Mostly these days you can actually avoid overfitting by brute force, and the brute force capabilities of automated machine learning," Linden said.
Instead of having your data science team members run these trials manually and deploying numerous models to find the correct one to use, automated machine learning can run hundreds of data sets in a short amount of time.
Another way to avoid overfitting models is building in a forgetting function, especially with deep neural networks. Having your data science teams encode a forget function allows for the model to organize, create data rules and create a space to ignore noise.
"They try to only memorize the generalities of things and try to forget the exact nature of the things," Linden said.
Another way to prevent overfitting in machine and deep learning models is ensuring that you have a holdout set of data to test your model on. If your model can generalize well enough then it should do well against this test data.
Building a core knowledge of machine learning and AI
Training a model often and with variety coupled with formatting forgetting functions and separate test data sets are all effective measures against overfitting. On top of this, organizations need to ensure there is a basic level of competency about common machine learning model failures throughout the company.
This entails investing and improving your organizational machine learning and data literacy levels. Though data scientists and members of the data science team are the first line of defense against overfitting and model problems, organizations require even more oversight to ensure successful application of machine learning.
"You'll need the line-of-business stakeholder to be aware of overfitting, aware of these pitfalls and be on the lookout for them," Carlsson said.
Having another part of the enterprise team understand common problems with model applications and what to look for adds another layer of safety. While there are numerous courses about machine learning and deep learning, finding the right level of basic AI literacy among employees can be a challenge. Most of these are tailored towards data scientists and provide information that a business owner or team member won't realistically need to know.
Targeting the correct training to the right business professionals can decrease the chances of overfitting and prevent poor applications, Carlsson said.