blobbotronic - stock.adobe.com
How neural network training methods are modeled after the human brain
Training neural nets to mirror the human brain enables deep learning models to apply learning to data they've never seen before.

Much of what makes us human is the power of our brain and cognitive abilities. The human brain is an organ that gives humans the power to communicate, imagine, plan and write. However, the brain is a mystery; we don't know quite how it works.
The brain has long perplexed scientists, researchers, philosophers and thinkers on the mechanisms of cognition and consciousness.
Neural networks and the brain
When AI started to gain popularity decades ago, there was debate about making a machine "learn," since developers still had little idea how humans learned. One approach was to have machines mimic the way that the human brain learns.
Since the brain is primarily a collection of interconnected neurons, AI researchers sought inspiration from the brain by re-creating the brain's structure through artificial neurons. They could connect simple artificial neurons in complex ways, and the connections of those neurons in artificial neural networks would create more complicated outcomes.
This is how the idea of artificial neural networks emerged.
The appeal of neural networks has waxed and waned over the decades. Neural nets, and specifically a form of neural nets called deep learning, have caught the industry's attention with their remarkable capabilities when fed with large quantities of data and computing horsepower. The emergence of deep learning combined with big data and computing has brought about the recent renaissance in AI. However, there have been some challenges to the neural networking approach.
We're starting to face limitations on the abilities of neural networks and still are major innovations away from solving the hard problems of cognition. Despite decades of research on AI and neuroscience, we're still not sure how exactly the brain works, raising the question as to whether creating AI based on human brains will be successful.
Brief history of artificial neural networks
In 1943, neuroscientists came up with the concept of an artificial neural network as a proof-of-concept attempt to mimic how biological neurons worked. Ten years later, psychologist Frank Rosenblatt further evolved the idea by creating a single-layer neural network for supervised learning called the Perceptron.
It could "learn" from good examples of data that would train the network, and then the trained network could apply that learning to new data it had never seen before.
However, the Perceptron started to quickly show its limitations to handle certain kinds of problems, most notably "nonlinear functions." In 1986, AI researchers published research that detailed that "hidden layers" of neurons can be used to solve the fundamental problems faced by earlier iterations of Perceptrons, especially when trained on large amounts of data. By 2006, researchers found a formula that worked: deep learning neural nets.
The evolution of big data, GPU processors and cloud computing rekindled interest in neural networks. Neural networks power many of the major AI-enabled systems such as translation services, facial and image recognition, and voice assistants.
How to create and train a neural network
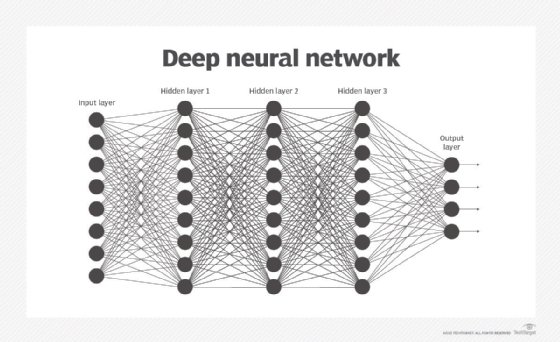
At a fundamental level, artificial neural networks are approaches to machine learning modeled after the biological activity of the human brain. Neural nets are made up of an input layer that receives data, one or more hidden layers that process the data and an output layer that provides one or more data points based on the function of the network.
Neurons are connected in various configurations. Each connection has a weight that contributes to the "activation" of another neuron, which is also adjusted by a bias and activation function to trigger further neurons in the network.
The entire network is then trained using input data of known value (labeled data), with the various errors in the network corrected after many interactions. After training sufficiently, the network has "learned" the relationship between inputs and outputs that can then be applied to future, unknown data.
At a foundational level, neural nets start from some untrained or pretrained state and the weights are then adjusted by training the network to make the output more accurate. While this may sound simple, adjusting the weights can take lots of time and compute power to get correct.
Each hidden layer in the neural net detects a specific class of features. For example, if we take a neural net built to detect cats, the first layer might detect some level of abstraction in the image. The next layers then detect a further level of abstraction. With enough training data, the neural net will adjust its weights to be able to detect if the image presented is a cat or not.
Now, you've built a model that identifies cats; a binary classifier that will give you a probability of whether the image is a cat or not. However, since no one trained the model on bird images, or car images, or flower images, the entire process needs to start over to detect each different object accurately. The model, in other words, can only tell if an image is a cat or not a cat. It can't determine what the "not a cat" image actually is.
There are approaches called transfer learning that take a neural network that has learned one thing and apply it to another similar training task, but neural networks are generally narrow in what they have learned.
Popular neural network training methods
While it may seem that neural networks are just one thing, they are a family of algorithms optimized for different kinds of patterns. In fact, there are many ways to connect neurons together to form neural networks.
Feedforward neural network (FFNN)
One of the most common forms is the feedforward neural network (FFNN), in which a neural network starts from inputs and works its way to outputs without any loops or other interesting convolutions. FFNNs are simple and can't handle more complex needs.
Since information only moves from the input layer to the output layer, hence the name "feedforward," its uses are largely limited to simple supervised learning applications. This includes image recognition, image classification and speech recognition use cases -- essentially, applications that don't require the model to look at information outside a linear time series.

Convolutional neural networks (CNNs)
Researchers in the 1990s created convolutional neural networks (CNNs) to more effectively handle certain kinds of learning tasks, and they most commonly apply CNNs to analyzing visual imagery, especially image and object recognition.
CNNs subsegment the neural network to learn parts of the network by sampling and then pooling the data together in levels of hierarchy. This enables much more sophisticated and higher-powered capabilities to identify various things within images, sound or text.
Recurrent neural networks (RNNs)
Another evolution of the neural network architecture connects various input or output layers in ways to enable networks to learn patterns. Instead of having an FFNN where each layer is structured as an output of previous layers, recurrent neural networks (RNNs) link outputs from a layer to previous layers, allowing information to flow back into the previous parts of the network. In this way, we can have a present that is dependent on past events.
This is great for situations involving a sequence such as speech, handwriting recognition, pattern and anomaly tracking, and other aspects of prediction based on time-sequence patterns. These RNNs link from a layer to previous layers, allowing information to flow back into the previous parts of the network and create a short-term memory of sorts.
As a result, RNNs are used when sequence of values and positioning matters, such as with speech and handwriting recognition, and when order matters, i.e., "the car fell on the man" and "the man fell on the car." RNNs are what power popular translation services as well as voice assistants.
There are many subcategories of RNNs, one of which is long short-term memory (LSTM) networks, which add capabilities such as connecting very distant and very recent neurons in sophisticated ways.
LSTMs are best suited for classifying, processing and making predictions based on time series data or evolving data sets where interaction between past and present data matters, such as predicting the next word in a sentence, machine translation, text generation and various probabilistic and predictive applications.
Many other kinds of neural networks form a sort of "zoo" with lots of different species and creatures for various specialized tasks. For example, there are neural networks such as Boltzmann machines, belief networks, Hopfield networks, deep residual networks and other various types that can learn different kinds of tasks with different levels of performance. If you thought that neural networks were just one kind of algorithm, you might be surprised by the sheer number of training approaches out there.
Limits of neural networks and deep learning
With the power and capabilities of modern artificial neural networks, it's no surprise that neural networks are where most of the attention, resources and developments in artificial intelligence are currently coming from. Yet, while having proven much capability across a wide range of problem areas, neural nets are just one of many practical approaches for machine learning.
News and research increasingly show the limits of deep learning capabilities and some of the downsides to the neural network approach. Artificial neural networks require massive amounts of data to learn and are very compute-hungry, limiting their application in certain use cases.
Another major downside is that it's hard for people to look behind the scenes of neural networks. Like trying to see exactly how a human brain makes a certain decision, it's not possible to examine how a particular neural net input leads to an output in any sort of explainable or transparent way. For applications that require root-cause analysis or a cause-effect explanation chain, neural networks are not a viable solution. For situations where explanations must support major decisions, "black box" technology is not always appropriate or allowed.
Additionally, neural nets are good at classifying and clustering data, but they are not great at other decision-making or learning scenarios such as deduction and reasoning. We're also starting to see how artificial neurons learn differently than the way the human brain works.
Children who are just beginning to learn and explore the world around them don't rely on supervised learning as their sole method of learning. Rather, they explore and discover the world. Indeed, it might be a combination of supervised, unsupervised and reinforcement learning that pushes the next breakthrough in AI forward.
As such, while neural networks are largely responsible for the advancement of AI that has brought about renewed interest and investment, neural networks are just a piece of the puzzle advancing the state of AI.







