blobbotronic - stock.adobe.com
Training GANs relies on calibrating 2 unstable neural networks
Understanding the complexities and theory of dueling neural networks can carve out a path to successful GAN training.

Some have hailed generative adversarial networks as the most exciting AI technology being developed, but they can be as confusing to train as they are powerful.
At its core, GANs are made of two neural networks that talk to each other, as well as a "ground truth" data set, explained Chris Nicholson, founder and CEO at Pathmind. He sees GANs as part of a broader trend in generative machine learning that includes other generative models, like GPT-3 for generating language.
GANs are a powerful image tool and can modify real images from one environment to another -- for example, modifying a summer scene into a winter scene or a daylight scene to a night scene. These new images can also be higher quality versions of existing images. Once researchers see their power in one domain, they can begin thinking about how to expand into others, such as generating better training data, but they first have to climb the obstacle of training GANs.
How are GANs trained?
Training GANs starts with creating two convolutional neural networks that compete against each other -- this is where the term adversarial comes from. One network called the discriminator learns to recognize images from a specific domain -- think white cats or leather sectional sofas. It is trained in a standard supervised fashion, with a data set that contains both real images and fake images.
"The more interesting network is the other network, the generator," said Adrian Zidaritz, an AI researcher.
This collection on generative adversarial networks includes basic and high-level descriptions of GANs, training strategies and their use cases in the enterprise.
Generative adversarial networks could be most powerful algorithm in AI
New uses for GAN technology focus on optimizing existing tech
Applications of generative adversarial networks hold promise
The generator neural network attempts to generate such accurate images that the discriminator network classifies them as real. Both networks learn each other's strengths and weaknesses to get better at their task. There is a zero-sum aspect to this training: each incurs a penalty anytime the other one wins.
One of the largest challenges to training GANs is developing an algorithm to create unique images on the generator side. As Zidaritz noted, it's easier to recognize something already created than to create something original.
The discriminator has a leg up in the competition, as it's already pretrained on a data set, and too much success from the discriminator doesn't allow the generator to learn fast enough to challenge it. As a result, the generator parameters can fail to converge, continuously bouncing around. The convergence is achieved when the two networks reach a so-called Nash equilibrium, which is a state when neither neural network can achieve any significant improvement through a minor adjustment. Another condition that may occur is the mode collapse of the generator, whereby the generator fails to keep up with producing good candidate images or any images at all.
Challenges in training
Training machine learning and deep learning models is already a complex process, and GANs' dueling models fuel the instability.
"Training a single neural network can be difficult, so training two of them simultaneously to do what you want adds even more complexity to that task," Nicholson said.
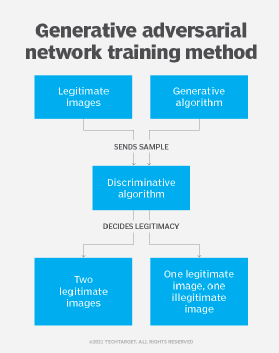
In training, Nicholson has found it useful to think of one neural network as a counterfeiter and the other as a cop. As they interact, they should both get better at their jobs, until, finally, the counterfeiter is able to produce "fake" things that would fool a human. It's important to ensure they learn at approximately the same pace, so focusing on the generator is a likely place to start.
"If one gets too good, it's hard for the other to catch up," Nicholson said.
The major problem with training neural networks is that the control settings, called hyperparameters, are significantly different when generating something compared with discriminating. Some forms of hyperparameter optimization make GAN training easier, but the parameters differ so widely across different kinds of tasks that it makes uniformity difficult.
William Falcon, co-founder and CEO of Grid.ai, a scalable AI training platform, argued that leading edge developers often solve this mismatch using a lot of tricks.
"Most [training errors] are because the practice doesn't quite match the theory, and so we learn properties of GANs that need to be fixed," Falcon said.
As a result, most GAN implementations are unstable to train unless the developers have a deep understanding of the particular domain they are working in. There are ways of getting around training issues, but it's very domain-specific and few people know all the tricks to get these working, Falcon said.
Another challenge with training neural networks is that once you change the data, you often must start building up the entire network again. Falcon recommended starting with an off-the-shelf product that is proven to be good for a particular domain, and then build from that. Once you become proficient in working with neural networks, it's easier to explore adjacent use cases.
Working out the theory
Zidaritz said that as positive applications of GANs boosted demand, researchers have focused on methods to ease the task of training GANs, rather than the theoretical foundation of the algorithm. For example, researchers are still struggling to understand the effectiveness of various proposed cost functions to fix the known and persistent problem of gradient vanishing. In this case, the training of the neural network reaches a point in which there is no easy way to adjust the relative weights of neurons for further improvement.
In the long run, he said he expects these problems to be ironed out through continuous research and dedication to theory.
"Just as with many other areas of deep learning, people get good results by continuously experimenting and turning GAN training more into an art than a science based on [rigidity]," Zidaritz said.






