ensemble modeling
What is ensemble modeling?
Ensemble modeling is the process of running two or more related but different analytical models and then synthesizing the results into a single score or spread. This improves the accuracy of predictive analytics and data mining applications. Ensemble modeling techniques are commonly used in machine learning applications to improve the overall predictive performance.
Analytical and machine learning models process some inputs and identify patterns in those inputs. Then, based on those patterns, they produce some output (outcome), which is usually some kind of prediction.
In many applications, one model is not enough to produce accurate predictions (i.e., predictions with low generalization error). To improve the prediction process and deliver better predictive output, multiple models are combined and trained. This approach is known as ensemble modeling.
Combining multiple models is akin to seeking the wisdom of crowds in making predictions and in reducing predictive or generalization error. It's important to note that the ensemble model's predictive error only decreases when the base estimators are both diverse and independent.
The models being combined are known as base estimators, base learners or first-level models. Regardless of how many base estimators are used, the ensemble model acts and performs as a single model.
The need for ensemble modeling
In machine learning, predictive modeling and other types of data analytics, a single model based on one data sample or data set can have biases and thus provide output based on an analysis of too few features. It may also have high variability, meaning the model is too sensitive to the inputs for the learned features. Another issue is that it may have outright inaccuracies so it cannot properly fit the entire training data set. All these issues can affect the reliability of the model's analytical or predictive findings.
By combining different models or analyzing multiple samples, data scientists, data analysts and machine learning engineers can reduce the effects of those limitations. They can boost the overall accuracy of the output by reducing error and provide better information to business decision-makers. Ensemble modeling also boosts resilience against uncertainties in the data set and increases the probability of producing more robust and reliable forecasts.
Ensemble modeling has grown in popularity as more organizations have deployed the computing resources and advanced analytics software needed to run such models. Hadoop and other big data technologies have led businesses to store and analyze greater volumes of data, creating increased potential for running analytical models on different data samples, or in other words, ensemble models.
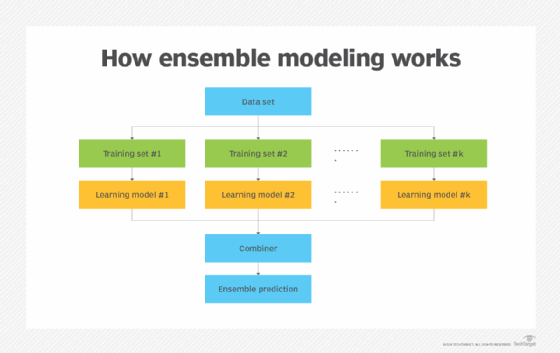
Example of ensemble modeling
A random forest model is a common example of ensemble modeling. This approach uses multiple decision trees -- an analytical model that predicts outcomes based on different variables and rules. It blends decision trees that may analyze different sample data, evaluate different factors or weight common variables differently. The results of the various decision trees are then either converted into a simple average or aggregated through further weighting.
The random forest algorithm is a popular algorithm in machine learning. It is one of the bagging techniques used to create ensemble models, in which different models use a subset of the training data set to minimize variance and overfitting.
Learn more about machine learning algorithms, how they work and their various types.
Ensemble modeling techniques
Many techniques are used to create ensemble models, especially in machine learning. These are the most popular techniques: stacking, bagging, blending and boosting.
Stacking
Stacking, also known as the stacked ensembles method or stacked generalization, is the process of combining the predictions from multiple base estimators to build a new model that produces better (i.e., more accurate) predictions.
How it works: Multiple base models (sometimes known as weak learners) are trained on the same training data set. Their predictions are then fed into a higher-level model to make the final prediction. The latter, also known as a meta-model or second-level model, combines the predictions of all the base models to generate the final prediction.
Bagging
Like stacking, bagging also combines the results of multiple models to produce a generalized result. What's important to note is that the various models are trained on slightly different subsets of the original data set.
How it works: Multiple sets of the original training data are created with replacements. All subsets are of the same size. These subsets are also known as bags and the method is known as bootstrap aggregating. Here, the bags are used to get a fair idea of the complete set and to train the models in parallel.
Blending
Blending is like stacking. One key difference is that the final model learns both training and validation (holdout) data.
How it works: In blending, both the validation set and predictions are used to build a model. The model is fitted on the training set while predictions are made on the validation set and test set. The features are extended to include the validation set and the model is used to make final predictions.
Boosting
Boosting is a sequential ensemble modeling technique in which the errors of one model are corrected by the subsequent model. The models whose errors are corrected are known as weak learners. Adaptive boosting is the most popular version of the boosting ensemble modeling technique in machine learning.
How it works: A subset of the original training data is created with all the data points having equal weight. This subset is used to create a base model that makes predictions on the entire data set. Based on the actual and predicted values, errors are calculated and the incorrectly predicted observations are given higher weights. A new model is created that tries to correct the errors and new predictions are made on the data set. This process continues, with each new model attempting to correct the previous model's errors, until a final model or strong learner is created. This model is the weighted mean of all the weak learners, and it improves the overall performance of the ensemble.
Understand the differences between advanced and predictive analytics techniques to maximize insights. Explore top predictive analytics use cases with enterprise examples. Learn about machine learning models using types and examples.
Continue Reading About ensemble modeling
Dig Deeper on Data science and analytics
-
![]()
Ensemble, Cohere partner on LLM for revenue cycle management
By: Jacqueline LaPointe
-
![]()
AI workflows - xtype: Everything you wanted to know (no, really, everything)
By: Adrian Bridgwater
-
![]()
Machine learning regularization explained with examples
By: George Lawton
-
![]()
What is boosting in machine learning?
By: George Lawton



